Leveraging Contrastive Learning and Self-Training for Multimodal Emotion Recognition with Limited Labeled Samples

0

Sign in to get full access
Overview
- This paper explores techniques for improving multimodal emotion recognition, which involves analyzing a combination of visual, audio, and text data to detect human emotions.
- The researchers propose leveraging contrastive learning and self-training to enhance emotion recognition performance, especially when working with limited labeled training data.
- The key ideas include using contrastive learning to learn robust feature representations and self-training to generate additional pseudo-labeled data for the model.
Plain English Explanation
The paper focuses on the challenge of multimodal emotion recognition, which is the task of detecting human emotions by analyzing a combination of visual, audio, and text data. This is an important problem with applications in areas like user experience, mental health monitoring, and human-robot interaction.
One of the key difficulties is that collecting and annotating large datasets of emotional data can be time-consuming and expensive. To address this, the researchers propose using contrastive learning and self-training to improve emotion recognition performance even when working with limited labeled data.
Contrastive learning is a technique that teaches the model to learn useful feature representations by comparing similar and dissimilar examples. This can help the model extract more robust and discriminative features from the available data. Self-training, on the other hand, involves using the model's own predictions to generate additional pseudo-labeled data, which can then be used to further fine-tune the model.
By combining these two approaches, the researchers aim to create a more accurate and generalizable emotion recognition system, even when the amount of labeled training data is constrained.
Technical Explanation
The paper proposes a two-stage framework for multimodal emotion recognition that leverages contrastive learning and self-training.
In the first stage, the model is pre-trained using contrastive learning on the available labeled data. The contrastive objective encourages the model to learn feature representations that can effectively distinguish between different emotional states, even when the labeled data is limited.
In the second stage, the pre-trained model is fine-tuned using a self-training approach. The model first makes predictions on unlabeled data, and then uses its own high-confidence predictions to generate pseudo-labels. These pseudo-labeled samples are then added to the training set, and the model is further fine-tuned.
The researchers evaluate their approach on several multimodal emotion recognition benchmarks, including IEMOCAP and CMU-MOSEI. They compare their method to various baselines and show that it outperforms them, particularly when the amount of labeled training data is restricted.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of limited labeled data in multimodal emotion recognition. The combination of contrastive learning and self-training is a well-motivated strategy, and the experimental results demonstrate the effectiveness of this technique.
One potential limitation of the paper is that it does not provide a detailed analysis of the types of errors the model makes or the specific scenarios where it struggles. A more in-depth examination of the model's strengths and weaknesses could help researchers and practitioners better understand the capabilities and limitations of the proposed approach.
Additionally, the paper could have explored the impact of different hyperparameter settings or architectural choices on the model's performance. This could provide useful insights for future work in this area.
Overall, the paper presents a solid contribution to the field of multimodal emotion recognition, and the proposed techniques could be valuable for researchers and developers working on real-world applications that require accurate emotion detection with limited labeled data.
Conclusion
This paper introduces a novel approach to multimodal emotion recognition that combines contrastive learning and self-training. The key idea is to leverage contrastive learning to extract robust feature representations from the available labeled data, and then use self-training to generate additional pseudo-labeled samples that can further improve the model's performance.
The results demonstrate the effectiveness of this approach, particularly in scenarios with limited labeled training data. This is an important advancement, as collecting and annotating large-scale emotional datasets can be challenging and resource-intensive.
The techniques proposed in this paper could have significant implications for a wide range of applications that rely on accurate emotion recognition, such as user experience optimization, mental health monitoring, and human-robot interaction. As the field of multimodal learning continues to evolve, the insights and methods presented in this work could inspire further research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Contrastive Learning and Self-Training for Multimodal Emotion Recognition with Limited Labeled Samples
Qi Fan, Yutong Li, Yi Xin, Xinyu Cheng, Guanglai Gao, Miao Ma
The Multimodal Emotion Recognition challenge MER2024 focuses on recognizing emotions using audio, language, and visual signals. In this paper, we present our submission solutions for the Semi-Supervised Learning Sub-Challenge (MER2024-SEMI), which tackles the issue of limited annotated data in emotion recognition. Firstly, to address the class imbalance, we adopt an oversampling strategy. Secondly, we propose a modality representation combinatorial contrastive learning (MR-CCL) framework on the trimodal input data to establish robust initial models. Thirdly, we explore a self-training approach to expand the training set. Finally, we enhance prediction robustness through a multi-classifier weighted soft voting strategy. Our proposed method is validated to be effective on the MER2024-SEMI Challenge, achieving a weighted average F-score of 88.25% and ranking 6th on the leaderboard. Our project is available at https://github.com/WooyoohL/MER2024-SEMI.
Read more9/10/2024
0
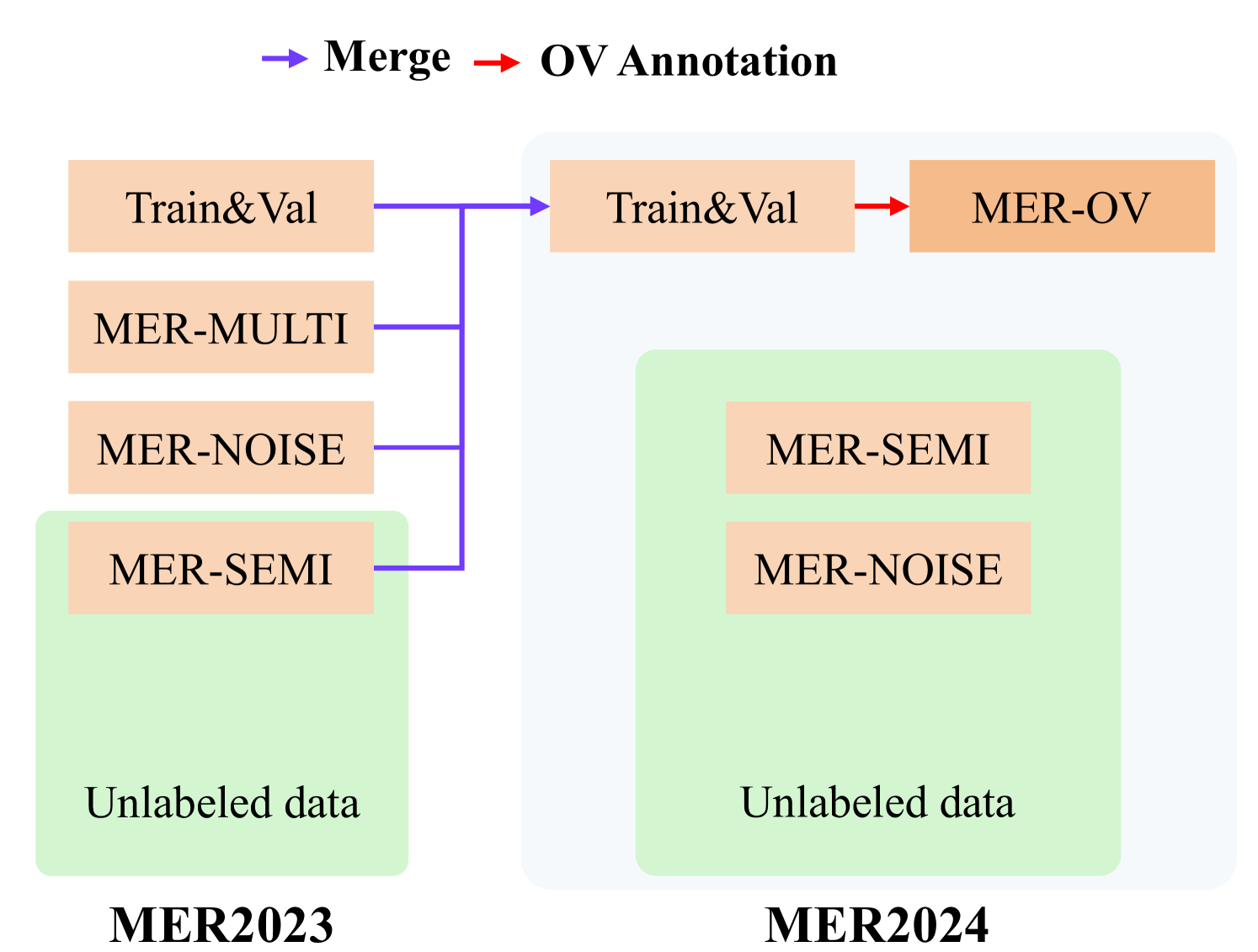
MER 2024: Semi-Supervised Learning, Noise Robustness, and Open-Vocabulary Multimodal Emotion Recognition
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, Jiangyan Yi, Rui Liu, Kele Xu, Bin Liu, Erik Cambria, Guoying Zhao, Bjorn W. Schuller, Jianhua Tao
Multimodal emotion recognition is an important research topic in artificial intelligence. Over the past few decades, researchers have made remarkable progress by increasing the dataset size and building more effective algorithms. However, due to problems such as complex environments and inaccurate annotations, current systems are hard to meet the demands of practical applications. Therefore, we organize the MER series of competitions to promote the development of this field. Last year, we launched MER2023, focusing on three interesting topics: multi-label learning, noise robustness, and semi-supervised learning. In this year's MER2024, besides expanding the dataset size, we further introduce a new track around open-vocabulary emotion recognition. The main purpose of this track is that existing datasets usually fix the label space and use majority voting to enhance the annotator consistency. However, this process may lead to inaccurate annotations, such as ignoring non-majority or non-candidate labels. In this track, we encourage participants to generate any number of labels in any category, aiming to describe emotional states as accurately as possible. Our baseline code relies on MERTools and is available at: https://github.com/zeroQiaoba/MERTools/tree/master/MER2024.
Read more7/19/2024

0
Improving Multimodal Emotion Recognition by Leveraging Acoustic Adaptation and Visual Alignment
Zhixian Zhao, Haifeng Chen, Xi Li, Dongmei Jiang, Lei Xie
Multimodal Emotion Recognition (MER) aims to automatically identify and understand human emotional states by integrating information from various modalities. However, the scarcity of annotated multimodal data significantly hinders the advancement of this research field. This paper presents our solution for the MER-SEMI sub-challenge of MER 2024. First, to better adapt acoustic modality features for the MER task, we experimentally evaluate the contributions of different layers of the pre-trained speech model HuBERT in emotion recognition. Based on these observations, we perform Parameter-Efficient Fine-Tuning (PEFT) on the layers identified as most effective for emotion recognition tasks, thereby achieving optimal adaptation for emotion recognition with a minimal number of learnable parameters. Second, leveraging the strengths of the acoustic modality, we propose a feature alignment pre-training method. This approach uses large-scale unlabeled data to train a visual encoder, thereby promoting the semantic alignment of visual features within the acoustic feature space. Finally, using the adapted acoustic features, aligned visual features, and lexical features, we employ an attention mechanism for feature fusion. On the MER2024-SEMI test set, the proposed method achieves a weighted F1 score of 88.90%, ranking fourth among all participating teams, validating the effectiveness of our approach.
Read more9/11/2024

0
Multimodal Emotion Recognition with Vision-language Prompting and Modality Dropout
Anbin QI, Zhongliang Liu, Xinyong Zhou, Jinba Xiao, Fengrun Zhang, Qi Gan, Ming Tao, Gaozheng Zhang, Lu Zhang
In this paper, we present our solution for the Second Multimodal Emotion Recognition Challenge Track 1(MER2024-SEMI). To enhance the accuracy and generalization performance of emotion recognition, we propose several methods for Multimodal Emotion Recognition. Firstly, we introduce EmoVCLIP, a model fine-tuned based on CLIP using vision-language prompt learning, designed for video-based emotion recognition tasks. By leveraging prompt learning on CLIP, EmoVCLIP improves the performance of pre-trained CLIP on emotional videos. Additionally, to address the issue of modality dependence in multimodal fusion, we employ modality dropout for robust information fusion. Furthermore, to aid Baichuan in better extracting emotional information, we suggest using GPT-4 as the prompt for Baichuan. Lastly, we utilize a self-training strategy to leverage unlabeled videos. In this process, we use unlabeled videos with high-confidence pseudo-labels generated by our model and incorporate them into the training set. Experimental results demonstrate that our model ranks 1st in the MER2024-SEMI track, achieving an accuracy of 90.15% on the test set.
Read more9/12/2024