Leveraging Diverse Semantic-based Audio Pretrained Models for Singing Voice Conversion

0
🧪
Sign in to get full access
Overview
- Singing Voice Conversion (SVC) is a technique that allows any singer to perform any song.
- To achieve this, the system needs to extract speaker-agnostic representations from the source audio, which is a significant challenge.
- The paper investigates the use of semantic-based audio pretrained models as feature extractors for SVC, and explores how well these features can model melody, lyrics, and speaker independence for real-world acoustic environments.
Plain English Explanation
The paper is about a technology called Singing Voice Conversion (SVC) that allows any singer to perform any song. This is a tricky problem because the system needs to extract features from the source audio that are independent of the specific singer's voice. A common approach is to use a pretrained model that can understand the semantic content of the audio, such as the melody and lyrics. However, it's not clear how well these models can actually meet the requirements of SVC, such as accurately modeling the melody and lyrics, being independent of the speaker's voice, and working well in real-world noisy environments.
The researchers delve into this question in detail, exploring the knowledge contained in different semantic-based pretrained models and how they can be combined in an efficient way to address the SVC task. They propose a framework called DSFF-SVC that uses diverse semantic-based features to improve the performance of various existing SVC models, especially in challenging real-world conversion tasks.
Technical Explanation
The paper investigates the use of semantic-based audio pretrained models as feature extractors for Singing Voice Conversion (SVC). The key questions explored are:
- How well can the extracted features from these models capture the melody and lyrics, as well as be independent of the speaker's voice?
- How robust are these features to real-world acoustic environments?
To address these questions, the researchers thoroughly analyze the knowledge contained in different semantic-based pretrained models and find that they are diverse and can be complementary for SVC. To jointly utilize these models with mismatched time resolutions, they propose an efficient ReTrans strategy to fuse the features.
Based on these insights, the researchers design a Singing Voice Conversion framework based on Diverse Semantic-based Feature Fusion (DSFF-SVC). Experimental results demonstrate that DSFF-SVC can be generalized and improve various existing SVC models, particularly in challenging real-world conversion tasks.
Critical Analysis
The paper provides a comprehensive investigation of the use of semantic-based pretrained models for SVC, highlighting both the potential and limitations of this approach. While the researchers demonstrate the effectiveness of their DSFF-SVC framework, they also acknowledge that there is still room for improvement, particularly in handling challenging acoustic environments and further enhancing the speaker-independence of the extracted features.
One potential area for further research could be exploring alternative feature extraction methods, such as those based on disentangled speech representations or iterative refinement, which may provide more robust and speaker-independent features for SVC tasks.
Additionally, the paper could have delved deeper into the issue of "who is the authentic speaker" and how to ensure the converted voice sounds natural and believable, as this is a crucial aspect of SVC. Exploring these areas could further strengthen the research and provide valuable insights for the development of more advanced SVC systems.
Conclusion
The paper presents an in-depth investigation of the use of semantic-based pretrained models for Singing Voice Conversion (SVC), a technology that enables any singer to perform any song. The researchers explore the capabilities of these models in capturing melody, lyrics, and speaker-independence, as well as their robustness to real-world acoustic environments.
By proposing the DSFF-SVC framework, which leverages diverse semantic-based features, the researchers demonstrate the ability to improve the performance of various existing SVC models, particularly in challenging real-world conversion tasks. This work contributes to the ongoing efforts to develop more advanced and versatile SVC systems, with potential applications in music production, live performances, and even virtual assistants capable of singing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
Leveraging Diverse Semantic-based Audio Pretrained Models for Singing Voice Conversion
Xueyao Zhang, Zihao Fang, Yicheng Gu, Haopeng Chen, Lexiao Zou, Junan Zhang, Liumeng Xue, Zhizheng Wu
Singing Voice Conversion (SVC) is a technique that enables any singer to perform any song. To achieve this, it is essential to obtain speaker-agnostic representations from the source audio, which poses a significant challenge. A common solution involves utilizing a semantic-based audio pretrained model as a feature extractor. However, the degree to which the extracted features can meet the SVC requirements remains an open question. This includes their capability to accurately model melody and lyrics, the speaker-independency of their underlying acoustic information, and their robustness for in-the-wild acoustic environments. In this study, we investigate the knowledge within classical semantic-based pretrained models in much detail. We discover that the knowledge of different models is diverse and can be complementary for SVC. Based on the above, we design a Singing Voice Conversion framework based on Diverse Semantic-based Feature Fusion (DSFF-SVC). Experimental results demonstrate that DSFF-SVC can be generalized and improve various existing SVC models, particularly in challenging real-world conversion tasks. Our demo website is available at https://diversesemanticsvc.github.io/.
Read more9/17/2024

0
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Wangjin Zhou, Fengrun Zhang, Yiming Liu, Wenhao Guan, Yi Zhao, He Qu
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
Read more9/14/2024
🧪
0
SPA-SVC: Self-supervised Pitch Augmentation for Singing Voice Conversion
Bingsong Bai, Fengping Wang, Yingming Gao, Ya Li
Diffusion-based singing voice conversion (SVC) models have shown better synthesis quality compared to traditional methods. However, in cross-domain SVC scenarios, where there is a significant disparity in pitch between the source and target voice domains, the models tend to generate audios with hoarseness, posing challenges in achieving high-quality vocal outputs. Therefore, in this paper, we propose a Self-supervised Pitch Augmentation method for Singing Voice Conversion (SPA-SVC), which can enhance the voice quality in SVC tasks without requiring additional data or increasing model parameters. We innovatively introduce a cycle pitch shifting training strategy and Structural Similarity Index (SSIM) loss into our SVC model, effectively enhancing its performance. Experimental results on the public singing datasets M4Singer indicate that our proposed method significantly improves model performance in both general SVC scenarios and particularly in cross-domain SVC scenarios.
Read more6/12/2024
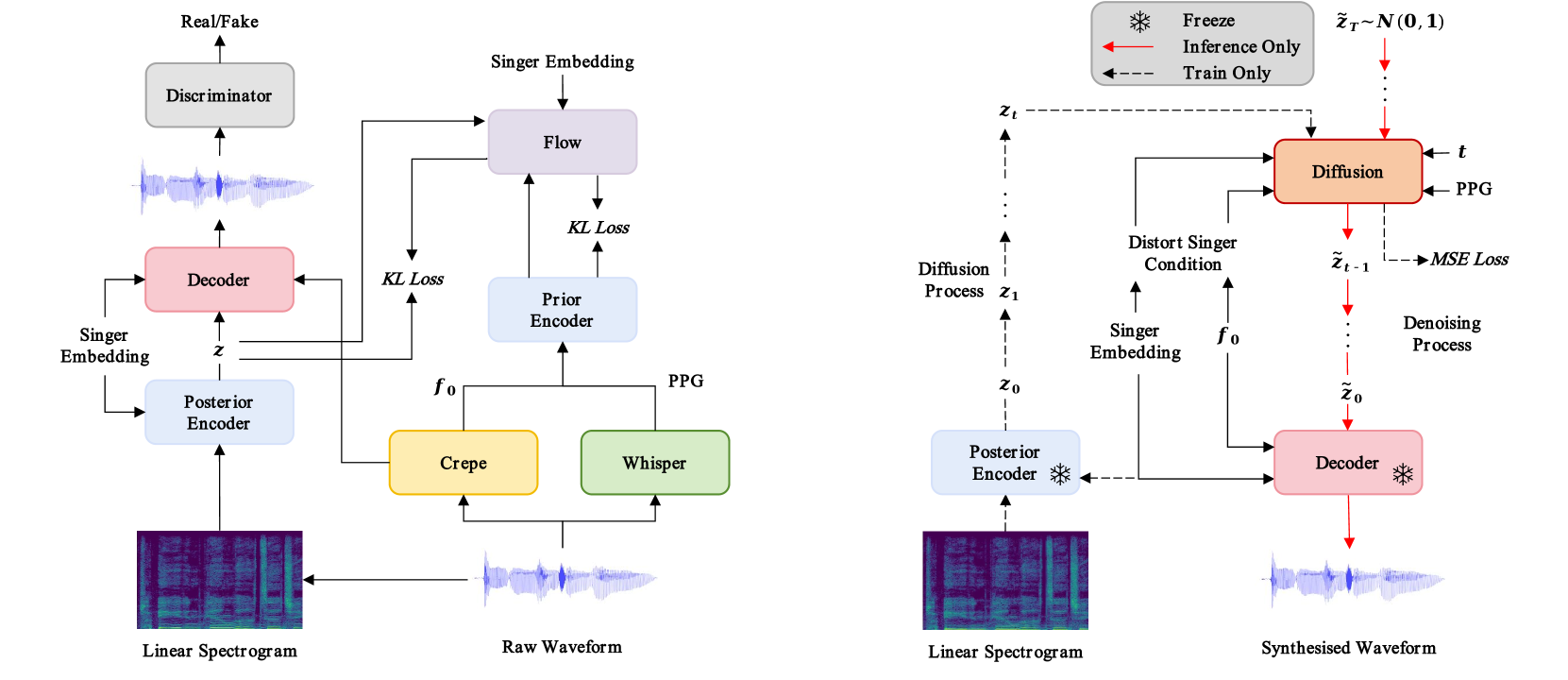
0
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Shihao Chen, Yu Gu, Jie Zhang, Na Li, Rilin Chen, Liping Chen, Lirong Dai
Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
Read more6/11/2024