Real-Time and Accurate: Zero-shot High-Fidelity Singing Voice Conversion with Multi-Condition Flow Synthesis

0

Sign in to get full access
Overview
- This paper presents a novel method for zero-shot high-fidelity singing voice conversion using a multi-condition flow synthesis model.
- The approach enables real-time and accurate conversion of singing voices, without requiring any parallel data or target speaker recordings.
- The model leverages a novel inverse short-time Fourier transform (iSTFT) module to generate high-quality audio directly from the network outputs.
Plain English Explanation
The researchers have developed a new way to transform one person's singing voice into another person's voice, without needing to record the target person singing. This is called "singing voice conversion." Their method works in real-time and can produce very realistic, high-quality results.
Traditionally, singing voice conversion has required recordings of the target singer performing the same songs as the source singer. This "parallel data" is used to train the conversion model. However, the researchers behind SingIt found a way to bypass this requirement by using a "multi-condition flow synthesis" approach.
Their model learns to map the acoustic features of the source singer's voice to the target singer's voice, without needing any actual recordings from the target. This "zero-shot" capability means the model can convert singing voices it has never heard before.
The key innovation is the use of an "inverse short-time Fourier transform" (iSTFT) module, which allows the model to directly generate high-quality audio from its internal representations, rather than relying on a separate vocoder. This results in very realistic and natural-sounding voice transformations.
Technical Explanation
The proposed model consists of a multi-condition flow-based generator that learns to map the acoustic features of the source singer's voice to the target singer's voice. This is achieved without requiring any parallel data or target speaker recordings, through a "zero-shot" learning approach.
The generator is trained on a diverse dataset of singing voices, learning to capture the statistical relationships between various acoustic conditions (e.g., gender, timbre, pitch range) and the corresponding spectral features. At conversion time, the model takes the source singer's mel-spectrogram as input and generates the target singer's mel-spectrogram, which is then passed through a novel iSTFT module to produce the final audio waveform.
The iSTFT module is a key component of the system, as it allows the model to generate high-fidelity audio directly from the network outputs, without the need for a separate vocoder. This end-to-end design enables real-time and accurate singing voice conversion, as demonstrated by the authors' experiments.
Critical Analysis
The paper presents a compelling approach to singing voice conversion that addresses several limitations of prior work. The zero-shot, parallel-data-free capability is particularly noteworthy, as it significantly expands the practical applicability of this technology.
However, the authors acknowledge that their method may struggle with certain challenging cases, such as converting between vastly different vocal styles or preserving certain nuances of the source singer's expression. Additionally, the model's performance may degrade when dealing with noisy or low-quality input audio.
Further research could explore ways to improve the model's robustness and generalization abilities, perhaps by incorporating more diverse training data or developing techniques to better capture the subtle characteristics of singing voices. Comparisons to state-of-the-art singing voice conversion systems, as well as subjective evaluations by human listeners, could also provide valuable insights.
Conclusion
The proposed zero-shot high-fidelity singing voice conversion system represents a significant advancement in the field, enabling real-time and accurate voice transformations without the need for parallel data or target speaker recordings. The innovative use of a multi-condition flow synthesis model and an iSTFT module allows for the generation of high-quality audio directly from the network outputs.
This research has the potential to unlock new applications in areas such as music production, virtual performance, and accessibility, empowering users to easily modify and personalize singing voices. As the authors continue to refine and expand upon this work, it could lead to even more transformative breakthroughs in the realm of singing voice conversion and digital audio synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Real-Time and Accurate: Zero-shot High-Fidelity Singing Voice Conversion with Multi-Condition Flow Synthesis
Hui Li, Hongyu Wang, Zhijin Chen, Bohan Sun, Bo Li
Singing voice conversion is to convert the source singing voice into the target singing voice except for the content. Currently, flow-based models can complete the task of voice conversion, but they struggle to effectively extract latent variables in the more rhythmically rich and emotionally expressive task of singing voice conversion, while also facing issues with low efficiency in speech processing. In this paper, we propose a high-fidelity flow-based model based on multi-decoupling feature constraints called RASVC, which enhances the capture of vocal details by integrating multiple latent attribute encoders. We also use Multi-stream inverse short-time Fourier transform(MS-iSTFT) to enhance the speed of speech processing by skipping some complicated decoder processing steps. We compare the synthesized singing voice with other models from multiple dimensions, and our proposed model is highly consistent with the current state-of-the-art, with the demo which is available at url{https://lazycat1119.github.io/RASVC-demo/}.
Read more9/10/2024

0
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Wangjin Zhou, Fengrun Zhang, Yiming Liu, Wenhao Guan, Yi Zhao, He Qu
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
Read more9/14/2024
0
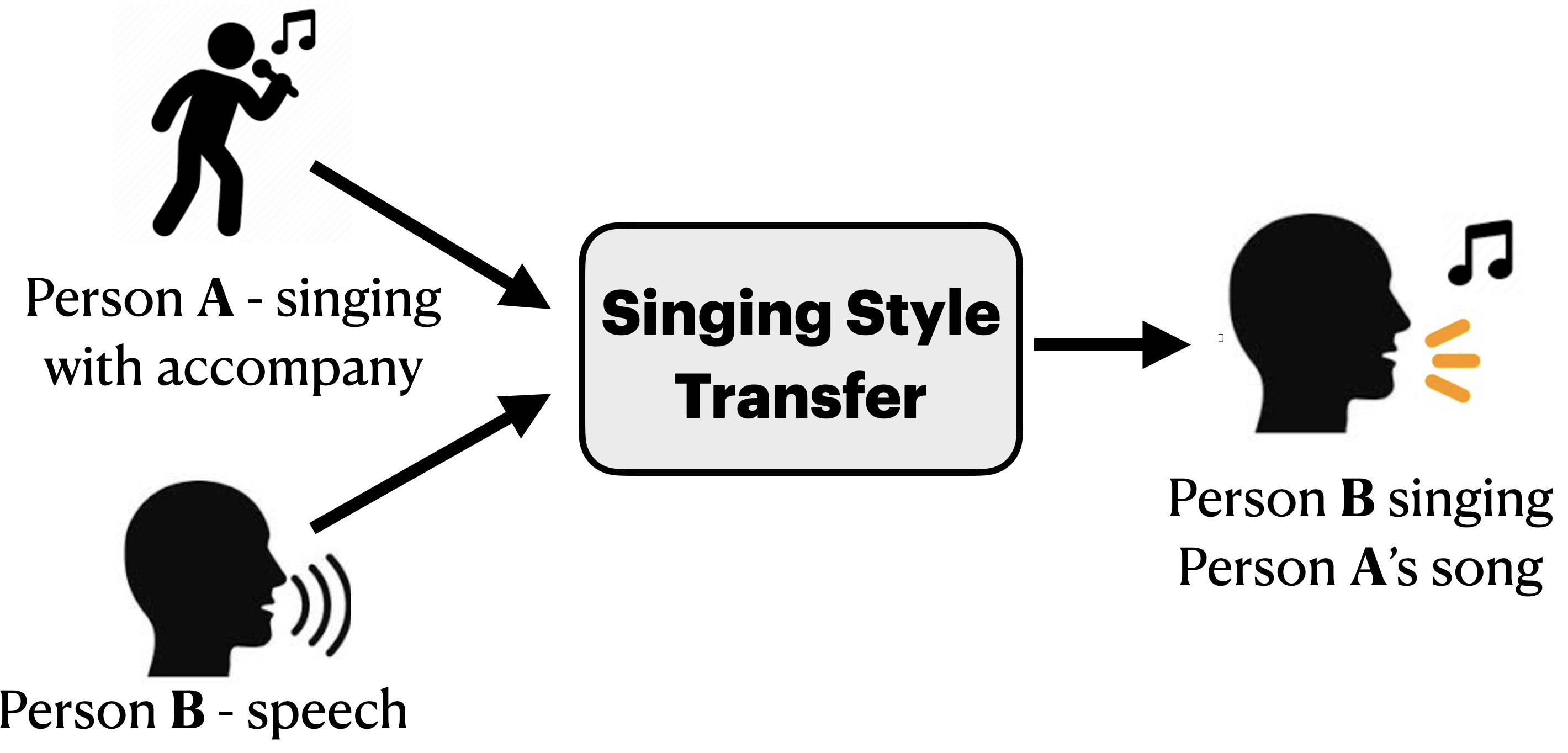
SingIt! Singer Voice Transformation
Amit Eliav, Aaron Taub, Renana Opochinsky, Sharon Gannot
In this paper, we propose a model which can generate a singing voice from normal speech utterance by harnessing zero-shot, many-to-many style transfer learning. Our goal is to give anyone the opportunity to sing any song in a timely manner. We present a system comprising several available blocks, as well as a modified auto-encoder, and show how this highly-complex challenge can be achieved by tailoring rather simple solutions together. We demonstrate the applicability of the proposed system using a group of 25 non-expert listeners. Samples of the data generated from our model are provided.
Read more5/9/2024
0
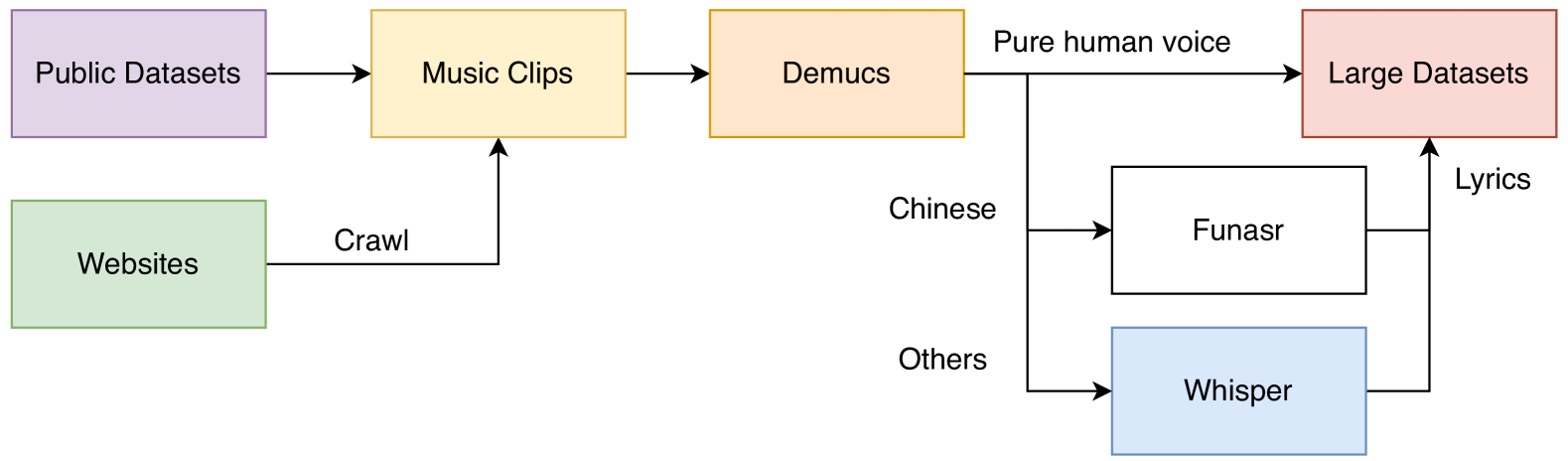
SaMoye: Zero-shot Singing Voice Conversion Based on Feature Disentanglement and Synthesis
Zihao Wang, Le Ma, Yongsheng Feng, Xin Pan, Yuhang Jin, Kejun Zhang
Singing voice conversion (SVC) aims to convert a singer's voice to another singer's from a reference audio while keeping the original semantics. However, existing SVC methods can hardly perform zero-shot due to incomplete feature disentanglement or dependence on the speaker look-up table. We propose the first open-source high-quality zero-shot SVC model SaMoye that can convert singing to human and non-human timbre. SaMoye disentangles the singing voice's features into content, timbre, and pitch features, where we combine multiple ASR models and compress the content features to reduce timbre leaks. Besides, we enhance the timbre features by unfreezing the speaker encoder and mixing the speaker embedding with top-3 similar speakers. We also establish an unparalleled large-scale dataset to guarantee zero-shot performance, which comprises more than 1,815 hours of pure singing voice and 6,367 speakers. We conduct objective and subjective experiments to find that SaMoye outperforms other models in zero-shot SVC tasks even under extreme conditions like converting singing to animals' timbre. The code and weight of SaMoye are available on https://github.com/CarlWangChina/SaMoye-SVC.
Read more9/16/2024