Leveraging Language Model Capabilities for Sound Event Detection

0
💬
Sign in to get full access
Overview
- Large language models have demonstrated impressive capabilities in understanding and generating multi-modal content, including audio.
- However, existing methods rarely leverage language models for the specific task of sound event detection (SED).
- This work proposes an end-to-end framework that combines pre-trained acoustic models and language models to enhance sound event detection and timestamp precision.
Plain English Explanation
The provided paper describes a new approach for understanding audio features and generating sound events and their timestamps. Traditionally, audio classification has struggled to extract useful features directly from raw audio data.
This framework uses pre-trained acoustic models to capture distinctive features across different sound categories. It then leverages language models to provide contextual understanding of the audio, allowing for more precise detection of sound events and their timestamps.
By combining these two powerful AI technologies, the researchers were able to enhance the accuracy of sound event detection and localization compared to conventional methods that struggle with pure audio-based classification.
Technical Explanation
The proposed framework employs pre-trained acoustic models to extract discriminative features from the audio input. These features are then fed into a language model, which is tasked with both classifying the sound events and predicting their temporal locations.
The key innovation is that the language model can leverage the rich semantic context aligned with the acoustic representation, allowing it to understand the audio content more flexibly than traditional audio-only methods. This leads to improved performance in sound event detection and timestamp precision.
The researchers conducted experiments to evaluate the effectiveness of their approach, and the results demonstrate the advantages of their framework over conventional techniques.
Critical Analysis
The paper does not discuss any significant limitations or caveats of the proposed method. It would be helpful to understand the potential drawbacks or edge cases where the framework may struggle, as well as areas for future research to address these issues.
Additionally, the authors could have provided more details on the specific pre-trained models used, the dataset, and the evaluation metrics to allow for a more thorough assessment of the research.
Overall, the work presents a promising approach to enhancing sound event detection by leveraging the power of language models. However, a more comprehensive critical analysis would strengthen the contribution and help readers form a balanced opinion.
Conclusion
This paper introduces an innovative end-to-end framework that combines pre-trained acoustic and language models to improve sound event detection and localization. By harnessing the contextual understanding of language models, the proposed method outperforms traditional audio-only classification techniques.
The findings of this research have the potential to advance the field of multi-modal AI, particularly in applications where accurate sound event recognition is crucial, such as audio-based surveillance, smart home devices, and autonomous systems. Further exploration of this approach could lead to even more robust and versatile sound event detection solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Leveraging Language Model Capabilities for Sound Event Detection
Hualei Wang, Jianguo Mao, Zhifang Guo, Jiarui Wan, Hong Liu, Xiangdong Wang
Large language models reveal deep comprehension and fluent generation in the field of multi-modality. Although significant advancements have been achieved in audio multi-modality, existing methods are rarely leverage language model for sound event detection (SED). In this work, we propose an end-to-end framework for understanding audio features while simultaneously generating sound event and their temporal location. Specifically, we employ pretrained acoustic models to capture discriminative features across different categories and language models for autoregressive text generation. Conventional methods generally struggle to obtain features in pure audio domain for classification. In contrast, our framework utilizes the language model to flexibly understand abundant semantic context aligned with the acoustic representation. The experimental results showcase the effectiveness of proposed method in enhancing timestamps precision and event classification.
Read more8/6/2024
🔎
0
Enhance Temporal Relations in Audio Captioning with Sound Event Detection
Zeyu Xie, Xuenan Xu, Mengyue Wu, Kai Yu
Automated audio captioning aims at generating natural language descriptions for given audio clips, not only detecting and classifying sounds, but also summarizing the relationships between audio events. Recent research advances in audio captioning have introduced additional guidance to improve the accuracy of audio events in generated sentences. However, temporal relations between audio events have received little attention while revealing complex relations is a key component in summarizing audio content. Therefore, this paper aims to better capture temporal relationships in caption generation with sound event detection (SED), a task that locates events' timestamps. We investigate the best approach to integrate temporal information in a captioning model and propose a temporal tag system to transform the timestamps into comprehensible relations. Results evaluated by the proposed temporal metrics suggest that great improvement is achieved in terms of temporal relation generation.
Read more7/19/2024

0
New!Unified Audio Event Detection
Yidi Jiang, Ruijie Tao, Wen Huang, Qian Chen, Wen Wang
Sound Event Detection (SED) detects regions of sound events, while Speaker Diarization (SD) segments speech conversations attributed to individual speakers. In SED, all speaker segments are classified as a single speech event, while in SD, non-speech sounds are treated merely as background noise. Thus, both tasks provide only partial analysis in complex audio scenarios involving both speech conversation and non-speech sounds. In this paper, we introduce a novel task called Unified Audio Event Detection (UAED) for comprehensive audio analysis. UAED explores the synergy between SED and SD tasks, simultaneously detecting non-speech sound events and fine-grained speech events based on speaker identities. To tackle this task, we propose a Transformer-based UAED (T-UAED) framework and construct the UAED Data derived from the Librispeech dataset and DESED soundbank. Experiments demonstrate that the proposed framework effectively exploits task interactions and substantially outperforms the baseline that simply combines the outputs of SED and SD models. T-UAED also shows its versatility by performing comparably to specialized models for individual SED and SD tasks on DESED and CALLHOME datasets.
Read more9/16/2024
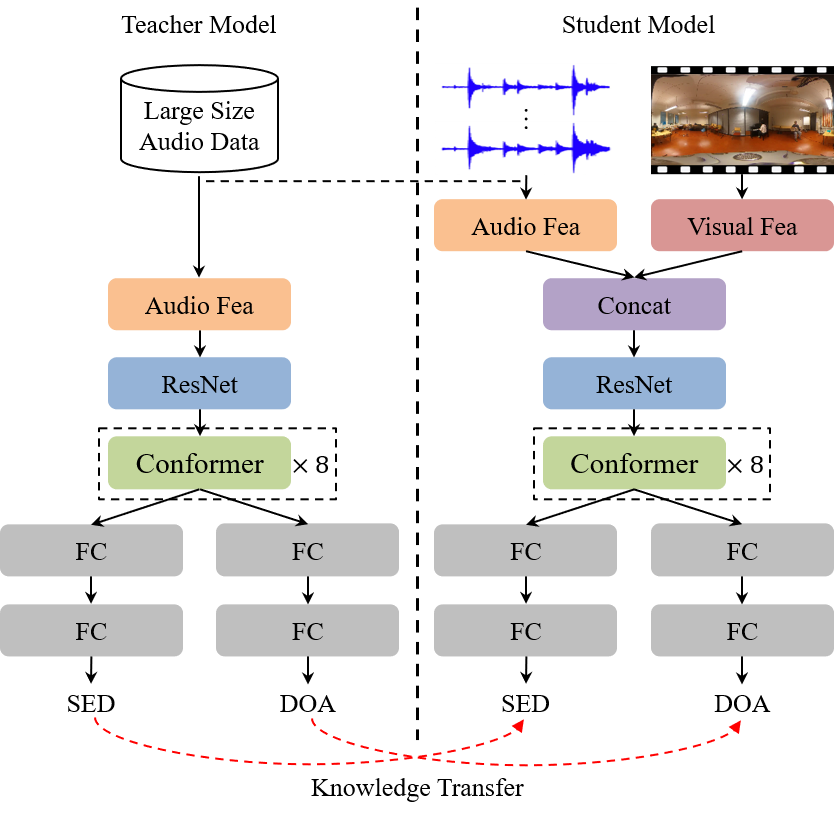
0
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
Read more6/24/2024