Sound event detection based on auxiliary decoder and maximum probability aggregation for DCASE Challenge 2024 Task 4

0
🔎
Sign in to get full access
Overview
- Proposes three novel methods for developing a sound event detection (SED) model for the DCASE 2024 Challenge Task 4
- Auxiliary decoder attached to final convolutional block to improve feature extraction and reduce dependency on pre-trained embeddings
- Maximum probability aggregation (MPA) to align model output with soft labels in MAESTRO dataset
- Multi-channel input features using logmel and MFCC to generate time-frequency patterns
Plain English Explanation
The researchers in this paper have come up with three new techniques to build a better sound event detection (SED) model for a competition called the DCASE 2024 Challenge Task 4.
First, they added an extra "decoder" to the final layer of the main model. This extra decoder helps the model extract more useful features from the input data, without needing to rely too heavily on pre-trained models.
Next, they introduced a method called "maximum probability aggregation" (MPA) during the training process. This helps the model's output match up better with the soft labels (which indicate how certain the labels are) in one of the datasets they're using, called MAESTRO.
Finally, they used a combination of different types of audio features - including logmel and MFCC - as the input to their model. This gives the model a richer set of time-frequency patterns to work with.
The experiments showed that these three techniques were effective at improving the sound event detection performance of the model, especially when working with different datasets and label types.
Technical Explanation
The paper proposes three key innovations for developing an SED model for the DCASE 2024 Challenge Task 4:
-
Auxiliary Decoder: The researchers attach an auxiliary decoder to the final convolutional block of the model. This auxiliary decoder operates independently from the main decoder, allowing it to focus on enhancing the feature extraction capabilities of the convolutional layers during the initial training stages. By assigning different weight strategies between the main and auxiliary decoder losses, the model can learn more robust features without relying as heavily on embeddings from pre-trained large models.
-
Maximum Probability Aggregation (MPA): To address the time interval mismatch between the DESED and MAESTRO datasets, the researchers propose the MPA method during training. MPA enables the model's output to be better aligned with the soft labels of 1 second duration in the MAESTRO dataset, improving the model's performance across different datasets and label types.
-
Multi-Channel Input Features: The model takes in a combination of various versions of logmel and MFCC features as input. This multi-channel input helps the model capture a richer set of time-frequency patterns, further enhancing its sound event detection capabilities.
The experimental results demonstrate the effectiveness of these proposed methods in improving SED performance by achieving a balanced enhancement across different datasets and label types. This work represents a significant step forward in developing more robust and flexible SED models.
Critical Analysis
The paper presents a thorough and well-designed approach to improving SED performance for the DCASE 2024 Challenge Task 4. The proposed techniques, such as the auxiliary decoder, MPA, and multi-channel input features, seem well-justified and their effectiveness is supported by the experimental results.
One potential limitation of the research is that it is focused specifically on the DCASE 2024 Challenge dataset and task. While the methods may be broadly applicable to other SED tasks, the paper does not explore their generalizability to other datasets or real-world scenarios. Further research could investigate the transferability of these techniques to a wider range of SED problems.
Additionally, the paper does not provide a detailed analysis of the computational complexity or inference time of the proposed model. This information would be valuable for evaluating the practicality of deploying the model in real-time or resource-constrained applications.
Overall, this research represents a significant contribution to the field of sound event detection, and the proposed methods could serve as a foundation for developing even more robust and efficient SED models in the future.
Conclusion
This paper presents three innovative techniques for improving sound event detection (SED) performance on the DCASE 2024 Challenge Task 4. The key contributions include an auxiliary decoder to enhance feature extraction, maximum probability aggregation to better align model output with dataset labels, and a multi-channel input feature representation to capture richer time-frequency patterns.
The experimental results demonstrate the effectiveness of these methods in achieving a balanced enhancement in SED performance across different datasets and label types. This work represents an important step forward in the development of more robust and flexible SED models, with potential applications in areas such as audio monitoring, smart home systems, and autonomous vehicles.
While the focus of this research is on the DCASE 2024 Challenge, the proposed techniques could be valuable starting points for further investigations into generalizable SED solutions that can be deployed in real-world scenarios. Continued research in this direction has the potential to significantly advance the state of the art in sound event detection and its diverse range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Sound event detection based on auxiliary decoder and maximum probability aggregation for DCASE Challenge 2024 Task 4
Sang Won Son, Jongyeon Park, Hong Kook Kim, Sulaiman Vesal, Jeong Eun Lim
In this report, we propose three novel methods for developing a sound event detection (SED) model for the DCASE 2024 Challenge Task 4. First, we propose an auxiliary decoder attached to the final convolutional block to improve feature extraction capabilities while reducing dependency on embeddings from pre-trained large models. The proposed auxiliary decoder operates independently from the main decoder, enhancing performance of the convolutional block during the initial training stages by assigning a different weight strategy between main and auxiliary decoder losses. Next, to address the time interval issue between the DESED and MAESTRO datasets, we propose maximum probability aggregation (MPA) during the training step. The proposed MPA method enables the model's output to be aligned with soft labels of 1 s in the MAESTRO dataset. Finally, we propose a multi-channel input feature that employs various versions of logmel and MFCC features to generate time-frequency pattern. The experimental results demonstrate the efficacy of these proposed methods in a view of improving SED performance by achieving a balanced enhancement across different datasets and label types. Ultimately, this approach presents a significant step forward in developing more robust and flexible SED models
Read more6/26/2024

0
Mixstyle based Domain Generalization for Sound Event Detection with Heterogeneous Training Data
Yang Xiao, Han Yin, Jisheng Bai, Rohan Kumar Das
This work explores domain generalization (DG) for sound event detection (SED), advancing adaptability towards real-world scenarios. Our approach employs a mean-teacher framework with domain generalization to integrate heterogeneous training data, while preserving the SED model performance across the datasets. Specifically, we first apply mixstyle to the frequency dimension to adapt the mel-spectrograms from different domains. Next, we use the adaptive residual normalization method to generalize features across multiple domains by applying instance normalization in the frequency dimension. Lastly, we use the sound event bounding boxes method for post-processing. Our approach integrates features from bidirectional encoder representations from audio transformers and a convolutional recurrent neural network. We evaluate the proposed approach on DCASE 2024 Challenge Task 4 dataset, measuring polyphonic SED score (PSDS) on the DESED dataset and macro-average pAUC on the MAESTRO dataset. The results indicate that the proposed DG-based method improves both PSDS and macro-average pAUC compared to the challenge baseline.
Read more8/30/2024
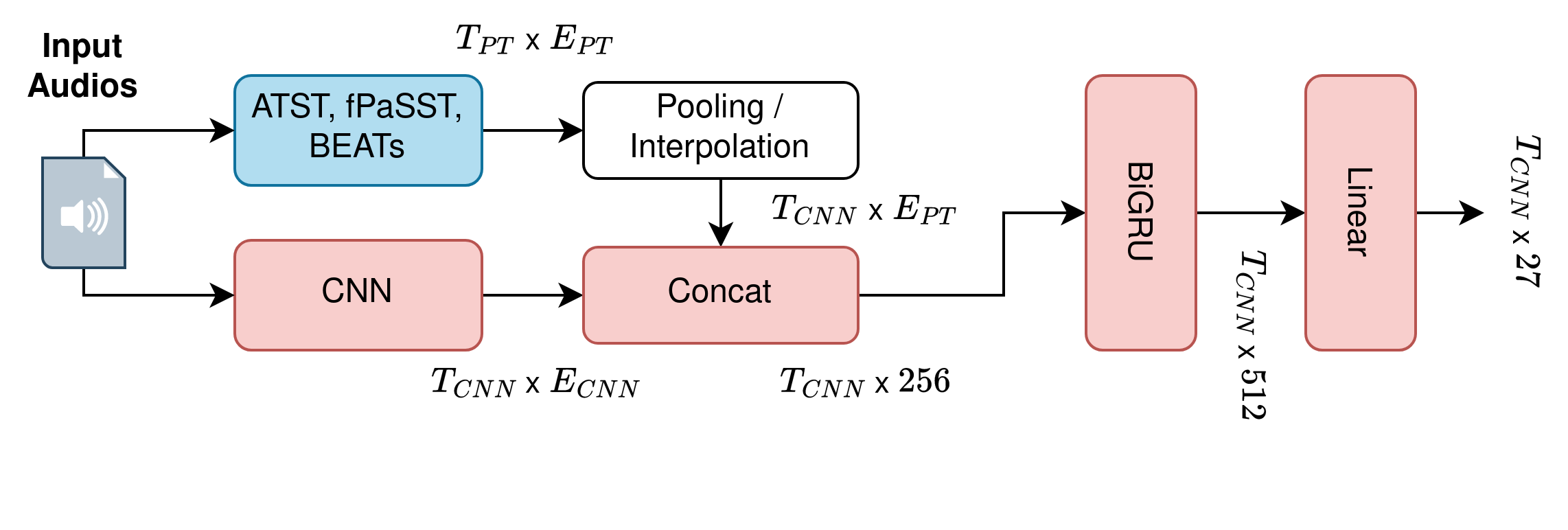
0
Multi-Iteration Multi-Stage Fine-Tuning of Transformers for Sound Event Detection with Heterogeneous Datasets
Florian Schmid, Paul Primus, Tobias Morocutti, Jonathan Greif, Gerhard Widmer
A central problem in building effective sound event detection systems is the lack of high-quality, strongly annotated sound event datasets. For this reason, Task 4 of the DCASE 2024 challenge proposes learning from two heterogeneous datasets, including audio clips labeled with varying annotation granularity and with different sets of possible events. We propose a multi-iteration, multi-stage procedure for fine-tuning Audio Spectrogram Transformers on the joint DESED and MAESTRO Real datasets. The first stage closely matches the baseline system setup and trains a CRNN model while keeping the pre-trained transformer model frozen. In the second stage, both CRNN and transformer are fine-tuned using heavily weighted self-supervised losses. After the second stage, we compute strong pseudo-labels for all audio clips in the training set using an ensemble of fine-tuned transformers. Then, in a second iteration, we repeat the two-stage training process and include a distillation loss based on the pseudo-labels, achieving a new single-model, state-of-the-art performance on the public evaluation set of DESED with a PSDS1 of 0.692. A single model and an ensemble, both based on our proposed training procedure, ranked first in Task 4 of the DCASE Challenge 2024.
Read more7/19/2024

0
FMSG-JLESS Submission for DCASE 2024 Task4 on Sound Event Detection with Heterogeneous Training Dataset and Potentially Missing Labels
Yang Xiao, Han Yin, Jisheng Bai, Rohan Kumar Das
This report presents the systems developed and submitted by Fortemedia Singapore (FMSG) and Joint Laboratory of Environmental Sound Sensing (JLESS) for DCASE 2024 Task 4. The task focuses on recognizing event classes and their time boundaries, given that multiple events can be present and may overlap in an audio recording. The novelty this year is a dataset with two sources, making it challenging to achieve good performance without knowing the source of the audio clips during evaluation. To address this, we propose a sound event detection method using domain generalization. Our approach integrates features from bidirectional encoder representations from audio transformers and a convolutional recurrent neural network. We focus on three main strategies to improve our method. First, we apply mixstyle to the frequency dimension to adapt the mel-spectrograms from different domains. Second, we consider training loss of our model specific to each datasets for their corresponding classes. This independent learning framework helps the model extract domain-specific features effectively. Lastly, we use the sound event bounding boxes method for post-processing. Our proposed method shows superior macro-average pAUC and polyphonic SED score performance on the DCASE 2024 Challenge Task 4 validation dataset and public evaluation dataset.
Read more7/2/2024