Leveraging Large Language Models for Web Scraping

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have impressive capabilities in replicating human tasks and boosting productivity, but their direct application for data extraction has limitations.
- This research aims to overcome these limitations by leveraging the knowledge representation power of pre-trained LLMs and the targeted information access enabled by RAG models.
- The researchers investigate a general-purpose accurate data scraping recipe for RAG models designed for language generation.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text, perform a wide variety of tasks, and boost productivity. However, when it comes to directly extracting specific data from unstructured text, LLMs have some limitations. They tend to prioritize fluency over factual accuracy, and they can struggle to manipulate or target particular pieces of information.
To address these limitations, the researchers in this study combined the knowledge representation capabilities of pre-trained LLMs with the targeted information access enabled by RAG models. RAG models are a type of AI system that can retrieve and attend to relevant documents from a large corpus, which can be useful for tasks like question answering.
The researchers developed a general-purpose data scraping approach using RAG models that is designed to accurately extract complex data from unstructured text. They tested this approach on three specific tasks: (1) classifying the semantic meaning of HTML elements, (2) chunking HTML text for better understanding, and (3) comparing the performance of different LLMs and ranking algorithms.
The key idea is that by combining the broad knowledge of LLMs with the targeted information access of RAG models, it's possible to create an efficient data extraction tool that can work with complex, unstructured text sources like webpages. This could have important implications for fields that rely on extracting valuable data from vast repositories of textual information.
Technical Explanation
This research investigates a general-purpose accurate data scraping recipe for RAG models designed for language generation. RAG models combine the knowledge representation power of pre-trained LLMs with the targeted information access enabled by retrieval systems.
The researchers used pre-trained language models with a latent knowledge retriever, which allows the model to retrieve and attend to relevant documents from a large corpus. They evaluated the capabilities of this RAG-based approach under three tasks:
- Semantic Classification of HTML Elements: The model was tasked with classifying the semantic meaning of different HTML elements (e.g., headings, paragraphs, lists).
- Chunking HTML Text: The model was used to break up HTML text into meaningful chunks to aid in understanding the structure and content.
- Comparing LLMs and Ranking Algorithms: The researchers compared the performance of different large language models and ranking algorithms within the RAG-based data extraction framework.
The researchers found that LLMs pre-trained on standard natural language, when combined with effective chunking, searching, and ranking algorithms, can be an efficient data scraping tool for extracting complex information from unstructured text. This contrasts with previous work that has focused on developing dedicated architectures and training procedures specifically for HTML understanding and extraction.
Critical Analysis
The researchers acknowledge that the proposed RAG-based data extraction approach still faces some challenges, particularly around provenance tracking and dynamic knowledge updates. Provenance tracking is important for understanding the origin and reliability of the extracted data, while dynamic knowledge updates are crucial for keeping the system up-to-date as new information becomes available.
Additionally, while the researchers have demonstrated the capabilities of their approach on HTML data, it's unclear how well it would generalize to other types of unstructured text sources. Further research and testing would be needed to understand the broader applicability of this method.
It's also worth considering the potential ethical implications of a powerful data extraction tool, such as concerns around privacy, data ownership, and the potential for misuse. The researchers do not explicitly address these issues in the paper, and it would be valuable for future work to consider the societal impact of this technology.
Conclusion
This research presents a novel approach to data extraction that leverages the strengths of large language models and RAG models. By combining the broad knowledge representation of LLMs with the targeted information access of RAG models, the researchers have developed a general-purpose data scraping tool that can accurately extract complex information from unstructured text sources like webpages.
The potential implications of this work are significant, as it could revolutionize how we extract valuable data from the vast repositories of textual information available online and in other domains. However, the researchers acknowledge the need to address challenges around provenance tracking and dynamic knowledge updates, as well as the potential ethical considerations of such a powerful data extraction tool.
Overall, this research represents an important step forward in the field of information retrieval and language understanding, and it opens up new avenues for future exploration and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Leveraging Large Language Models for Web Scraping
Aman Ahluwalia, Suhrud Wani
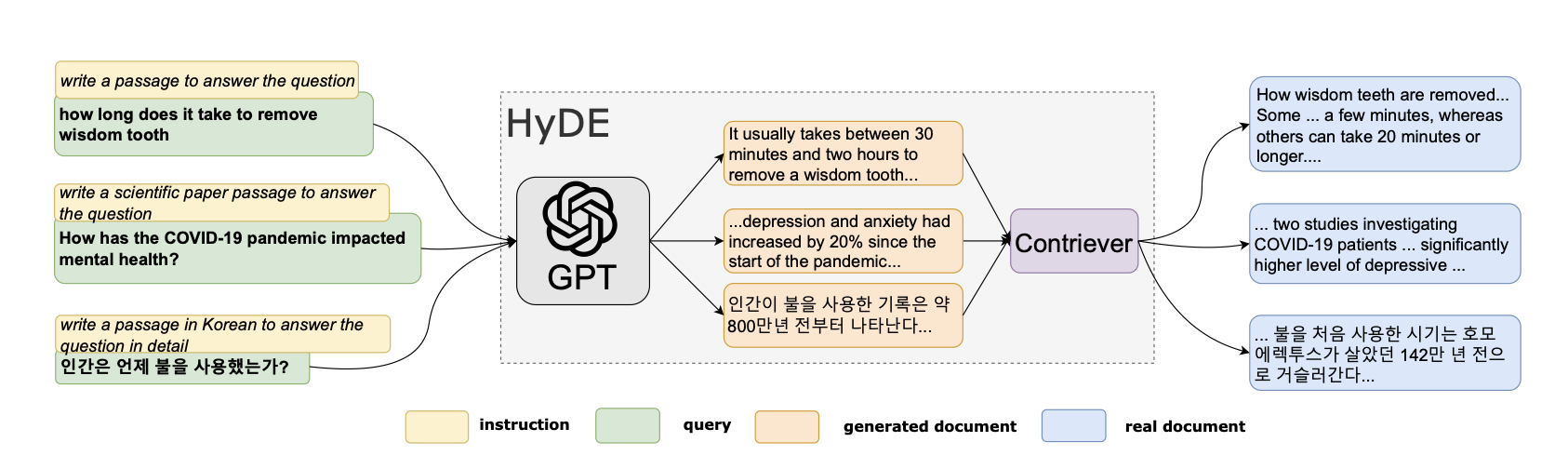
Large Language Models (LLMs) demonstrate remarkable capabilities in replicating human tasks and boosting productivity. However, their direct application for data extraction presents limitations due to a prioritisation of fluency over factual accuracy and a restricted ability to manipulate specific information. Therefore to overcome these limitations, this research leverages the knowledge representation power of pre-trained LLMs and the targeted information access enabled by RAG models, this research investigates a general-purpose accurate data scraping recipe for RAG models designed for language generation. To capture knowledge in a more modular and interpretable way, we use pre trained language models with a latent knowledge retriever, which allows the model to retrieve and attend over documents from a large corpus. We utilised RAG model architecture and did an in-depth analysis of their capabilities under three tasks: (i) Semantic Classification of HTML elements, (ii) Chunking HTML text for effective understanding, and (iii) comparing results from different LLMs and ranking algorithms. While previous work has developed dedicated architectures and training procedures for HTML understanding and extraction, we show that LLMs pre-trained on standard natural language with an addition of effective chunking, searching and ranking algorithms, can prove to be efficient data scraping tool to extract complex data from unstructured text. Future research directions include addressing the challenges of provenance tracking and dynamic knowledge updates within the proposed RAG-based data extraction framework. By overcoming these limitations, this approach holds the potential to revolutionise data extraction from vast repositories of textual information.
Read more6/13/2024
0
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Harsh Thakkar, Alyssa Lee, Eden Chung, Natan Vidra
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
Read more8/2/2024
↗️
0
T-RAG: Lessons from the LLM Trenches
Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla
Large Language Models (LLM) have shown remarkable language capabilities fueling attempts to integrate them into applications across a wide range of domains. An important application area is question answering over private enterprise documents where the main considerations are data security, which necessitates applications that can be deployed on-prem, limited computational resources and the need for a robust application that correctly responds to queries. Retrieval-Augmented Generation (RAG) has emerged as the most prominent framework for building LLM-based applications. While building a RAG is relatively straightforward, making it robust and a reliable application requires extensive customization and relatively deep knowledge of the application domain. We share our experiences building and deploying an LLM application for question answering over private organizational documents. Our application combines the use of RAG with a finetuned open-source LLM. Additionally, our system, which we call Tree-RAG (T-RAG), uses a tree structure to represent entity hierarchies within the organization. This is used to generate a textual description to augment the context when responding to user queries pertaining to entities within the organization's hierarchy. Our evaluations, including a Needle in a Haystack test, show that this combination performs better than a simple RAG or finetuning implementation. Finally, we share some lessons learned based on our experiences building an LLM application for real-world use.
Read more6/7/2024
💬
0
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
Read more6/18/2024