Leveraging Superfluous Information in Contrastive Representation Learning

0

Sign in to get full access
Overview
- The paper explores how to leverage "superfluous" information during contrastive representation learning to improve model performance.
- Contrastive learning is a popular technique for learning effective representations from data, but the authors argue that existing approaches do not fully utilize all available information.
- They propose a new method called SuperCon that aims to extract and leverage additional useful signals from the training data.
Plain English Explanation
The paper focuses on a type of machine learning called "contrastive representation learning." This is a popular technique for training models to understand and represent data in an effective way. The key idea is to train the model to recognize differences between similar data points, so it learns useful features.
However, the authors argue that existing contrastive learning methods don't take full advantage of all the information available in the training data. There's often extra "superfluous" data or signals that could provide additional useful cues to the model, but get ignored.
The researchers propose a new approach called SuperCon that aims to leverage this extra information during training. The core idea is to have the model not just learn to distinguish between similar data points, but also to predict additional attributes or characteristics of the data. This forces the model to extract a richer set of features that capture more of the underlying structure and patterns.
By tapping into these additional supervisory signals, the authors show that SuperCon can lead to better representations and improved performance on downstream tasks, compared to standard contrastive learning methods. This suggests there's valuable information in the training data that is often overlooked, and finding ways to harness it can make machine learning models more powerful and effective.
Technical Explanation
The paper introduces a new contrastive representation learning method called SuperCon that leverages "superfluous" information in the training data. In standard contrastive learning, the model is trained to learn representations by contrasting similar and dissimilar data points. The authors argue that this approach does not fully utilize all the available information, as there are often additional attributes or signals in the data that could provide useful cues.
SuperCon extends the contrastive objective by adding an additional task of predicting these superfluous attributes. Specifically, the model is trained to not only distinguish between similar and dissimilar data points, but also to predict ancillary properties or characteristics of the inputs. This forces the model to learn richer representations that capture a broader set of underlying patterns and structures in the data.
The authors evaluate SuperCon on several benchmark datasets and downstream tasks, and show that it outperforms standard contrastive learning approaches. They attribute this performance boost to the model's ability to leverage the extra supervisory signals from the superfluous information, which enables it to learn more powerful and generalizable representations.
The paper also provides theoretical analysis to elucidate the mechanisms by which SuperCon is able to extract and harness this additional information. The authors demonstrate that the approach can be interpreted as maximizing a lower bound on the mutual information between the learned representations and the target variables, including both the primary task and the superfluous attributes.
Critical Analysis
The paper presents a compelling and well-designed approach for improving contrastive representation learning. By incorporating "superfluous" information into the training objective, SuperCon is able to learn richer representations that capture a broader set of underlying patterns and structures in the data.
One potential limitation is that the effectiveness of the method may depend on the nature and informativeness of the available superfluous attributes. If the additional signals are not sufficiently meaningful or correlated with the primary task, they may not provide much benefit. The authors acknowledge this and suggest further research into automatically identifying the most useful superfluous information.
Additionally, the theoretical analysis relies on certain assumptions and approximations, so there may be opportunities to further refine the theoretical foundations of the approach. It would be valuable to better understand the precise mechanisms by which SuperCon is able to extract and leverage the extra information.
Overall, the paper makes a compelling case for the importance of fully utilizing all available information during representation learning, and provides a novel and effective method for doing so. The SuperCon approach represents an important step forward in contrastive learning and suggests promising directions for future research in this area.
Conclusion
This paper introduces a new contrastive representation learning method called SuperCon that aims to leverage "superfluous" information in the training data to learn more powerful and generalizable representations. By adding an additional task of predicting ancillary attributes or characteristics of the inputs, SuperCon forces the model to extract a richer set of features that capture a broader range of underlying patterns and structures.
The authors demonstrate that this approach outperforms standard contrastive learning methods on several benchmark datasets and tasks, highlighting the value of harnessing extra information that is often overlooked. The theoretical analysis provides insights into the mechanisms by which SuperCon is able to extract and utilize this additional supervisory signal.
The work suggests that there is valuable information in training data that is often underutilized by existing machine learning techniques. Finding effective ways to tap into these rich sources of signals could lead to significant performance improvements and more robust, generalizable models. The SuperCon method represents an important step in this direction and opens up promising avenues for future research in contrastive representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Superfluous Information in Contrastive Representation Learning
Xuechu Yu
Contrastive representation learning, which aims to learnthe shared information between different views of unlabeled data by maximizing the mutual information between them, has shown its powerful competence in self-supervised learning for downstream tasks. However, recent works have demonstrated that more estimated mutual information does not guarantee better performance in different downstream tasks. Such works inspire us to conjecture that the learned representations not only maintain task-relevant information from unlabeled data but also carry task-irrelevant information which is superfluous for downstream tasks, thus leading to performance degeneration. In this paper we show that superfluous information does exist during the conventional contrastive learning framework, and further design a new objective, namely SuperInfo, to learn robust representations by a linear combination of both predictive and superfluous information. Besides, we notice that it is feasible to tune the coefficients of introduced losses to discard task-irrelevant information, while keeping partial non-shared task-relevant information according to our SuperInfo loss.We demonstrate that learning with our loss can often outperform the traditional contrastive learning approaches on image classification, object detection and instance segmentation tasks with significant improvements.
Read more8/21/2024
0
A Mutual Information Perspective on Federated Contrastive Learning
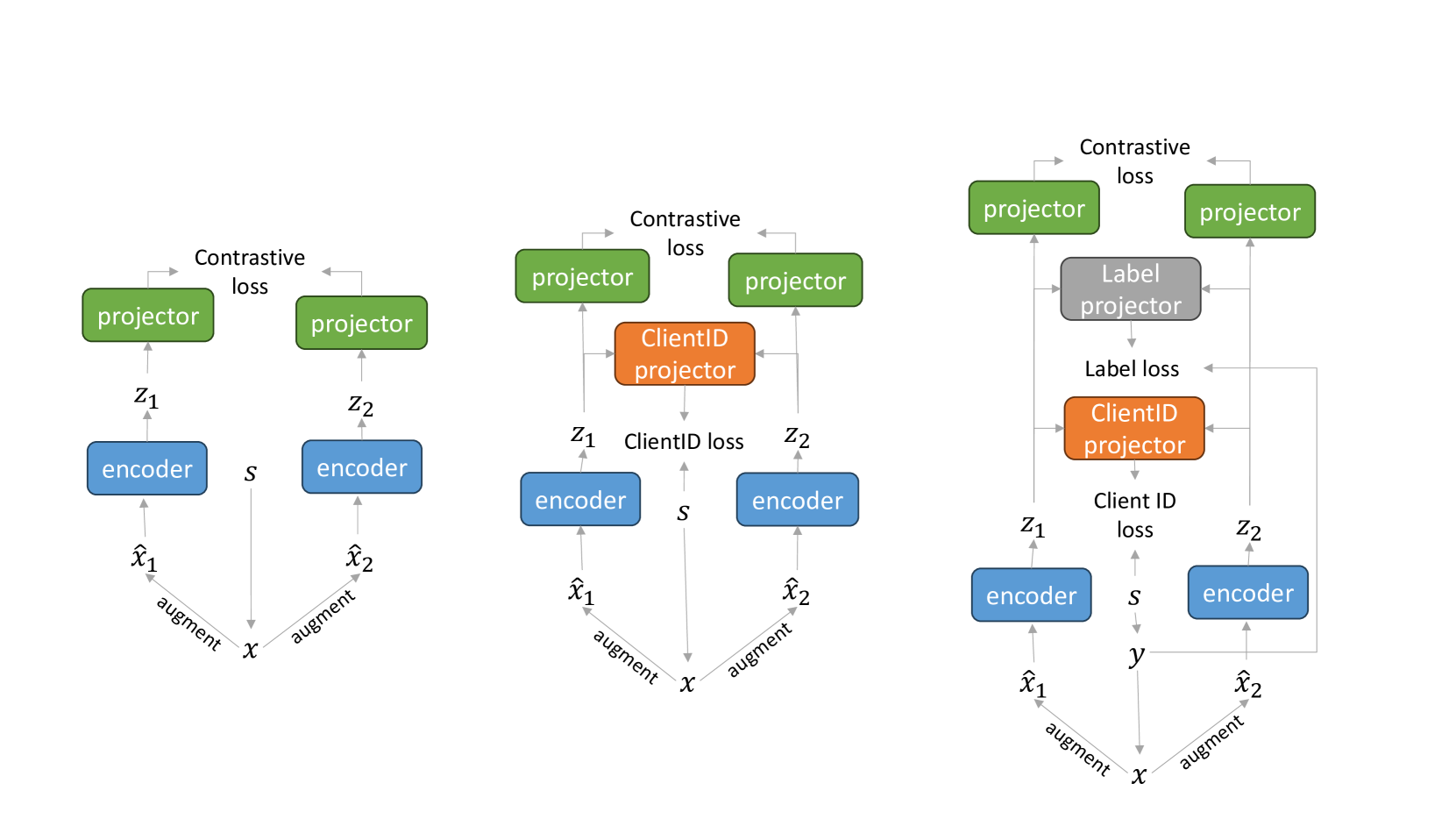
Christos Louizos, Matthias Reisser, Denis Korzhenkov
We investigate contrastive learning in the federated setting through the lens of SimCLR and multi-view mutual information maximization. In doing so, we uncover a connection between contrastive representation learning and user verification; by adding a user verification loss to each client's local SimCLR loss we recover a lower bound to the global multi-view mutual information. To accommodate for the case of when some labelled data are available at the clients, we extend our SimCLR variant to the federated semi-supervised setting. We see that a supervised SimCLR objective can be obtained with two changes: a) the contrastive loss is computed between datapoints that share the same label and b) we require an additional auxiliary head that predicts the correct labels from either of the two views. Along with the proposed SimCLR extensions, we also study how different sources of non-i.i.d.-ness can impact the performance of federated unsupervised learning through global mutual information maximization; we find that a global objective is beneficial for some sources of non-i.i.d.-ness but can be detrimental for others. We empirically evaluate our proposed extensions in various tasks to validate our claims and furthermore demonstrate that our proposed modifications generalize to other pretraining methods.
Read more5/6/2024

0
Clustering-friendly Representation Learning for Enhancing Salient Features
Toshiyuki Oshima, Kentaro Takagi, Kouta Nakata
Recently, representation learning with contrastive learning algorithms has been successfully applied to challenging unlabeled datasets. However, these methods are unable to distinguish important features from unimportant ones under simply unsupervised settings, and definitions of importance vary according to the type of downstream task or analysis goal, such as the identification of objects or backgrounds. In this paper, we focus on unsupervised image clustering as the downstream task and propose a representation learning method that enhances features critical to the clustering task. We extend a clustering-friendly contrastive learning method and incorporate a contrastive analysis approach, which utilizes a reference dataset to separate important features from unimportant ones, into the design of loss functions. Conducting an experimental evaluation of image clustering for three datasets with characteristic backgrounds, we show that for all datasets, our method achieves higher clustering scores compared with conventional contrastive analysis and deep clustering methods.
Read more8/12/2024

0
Representation Learning with Conditional Information Flow Maximization
Dou Hu, Lingwei Wei, Wei Zhou, Songlin Hu
This paper proposes an information-theoretic representation learning framework, named conditional information flow maximization, to extract noise-invariant sufficient representations for the input data and target task. It promotes the learned representations have good feature uniformity and sufficient predictive ability, which can enhance the generalization of pre-trained language models (PLMs) for the target task. Firstly, an information flow maximization principle is proposed to learn more sufficient representations for the input and target by simultaneously maximizing both input-representation and representation-label mutual information. Unlike the information bottleneck, we handle the input-representation information in an opposite way to avoid the over-compression issue of latent representations. Besides, to mitigate the negative effect of potential redundant features from the input, we design a conditional information minimization principle to eliminate negative redundant features while preserve noise-invariant features. Experiments on 13 language understanding benchmarks demonstrate that our method effectively improves the performance of PLMs for classification and regression. Extensive experiments show that the learned representations are more sufficient, robust and transferable.
Read more8/13/2024