Representation Learning with Conditional Information Flow Maximization

0

Sign in to get full access
Overview
- The paper proposes a new approach called "Representation Learning with Conditional Information Flow Maximization" (RCIFM) for learning representations that capture the key information in data while removing unwanted biases.
- The method aims to maximize the information flow between the input data and the learned representations, while conditioning on one or more target variables to remove unwanted information.
- This allows the model to learn more informative and interpretable representations that are useful for downstream tasks.
Plain English Explanation
In machine learning, we often want to extract useful information from data while removing unwanted biases or irrelevant details. Representation Learning with Conditional Information Flow Maximization proposes a new way to do this by maximizing the amount of important information that gets captured in the learned representations, while specifically removing information that is not relevant to the task at hand.
The key idea is to treat the process of learning representations as a communication channel, where the input data is the "message" that we want to transmit, and the learned representations are the "received signal." By maximizing the information flow between the input and the representations, we can ensure that the representations capture as much of the important information as possible.
However, we also want to remove unwanted information, such as biases or irrelevant details. To do this, the method "conditions" the information flow on one or more "target variables" - that is, it tries to maximize the information flow between the input and the representations, while keeping the information about the target variables fixed. This allows the model to learn representations that are useful for the task at hand, without being distracted by irrelevant information.
Revisiting Mutual Information Maximization for Generalized Category Discovery and Understanding Multimodal Contrastive Learning through Pointwise Mutual Information are related techniques that also aim to learn informative and interpretable representations by maximizing information flow.
Technical Explanation
The Representation Learning with Conditional Information Flow Maximization (RCIFM) method starts with the premise that the process of learning representations can be viewed as a communication channel, where the input data is the "message" that we want to transmit, and the learned representations are the "received signal."
By maximizing the mutual information between the input data and the learned representations, the model can ensure that the representations capture as much of the important information in the data as possible. However, the authors also want to remove unwanted information, such as biases or irrelevant details.
To do this, RCIFM "conditions" the information flow on one or more "target variables" - that is, it tries to maximize the mutual information between the input data and the representations, while keeping the information about the target variables fixed. This allows the model to learn representations that are useful for the task at hand, without being distracted by irrelevant information.
The authors formulate this as an optimization problem, where they try to maximize the conditional mutual information between the input data and the learned representations, given the target variables. They provide a practical algorithm for solving this optimization problem, and demonstrate the effectiveness of RCIFM on several benchmark datasets and tasks.
Learning to Maximize Mutual Information: A Chain Thought and Enforcing Conditional Independence for Fair Representation Learning are related techniques that also aim to learn informative and interpretable representations by maximizing information flow, while conditioning on relevant variables.
Critical Analysis
The RCIFM method is a novel and promising approach for learning informative and interpretable representations. By explicitly conditioning the information flow on relevant target variables, the method is able to remove unwanted biases and irrelevant information from the learned representations.
However, the authors do not address several potential limitations and areas for further research. For example, the method assumes that the target variables are known and available during training, which may not always be the case in real-world applications. It would be useful to explore ways to extend the method to scenarios where the relevant target variables are not known a priori.
Additionally, the authors only demonstrate the effectiveness of RCIFM on relatively simple datasets and tasks. It would be interesting to see how the method performs on more complex, real-world problems, and how it compares to other state-of-the-art representation learning techniques.
Finally, the authors do not provide a deep analysis of the learned representations, nor do they explore the interpretability of the method. It would be valuable to investigate the properties of the learned representations, and to understand how the conditioning on target variables affects the interpretability and usefulness of the representations for downstream tasks.
Overall, the RCIFM method is a promising and well-designed approach, but further research is needed to address its limitations and explore its full potential.
Conclusion
The Representation Learning with Conditional Information Flow Maximization (RCIFM) method proposes a novel way to learn informative and interpretable representations by maximizing the information flow between the input data and the learned representations, while conditioning on relevant target variables.
This approach allows the model to capture the key information in the data while removing unwanted biases and irrelevant details, which can be useful for a wide range of machine learning tasks. The method builds on the principles of information theory and mutual information maximization, and provides a practical algorithm for solving the associated optimization problem.
While the RCIFM method shows promising results, there are still several areas for further research, such as extending the method to scenarios where the relevant target variables are not known a priori, exploring its performance on more complex real-world problems, and investigating the interpretability and properties of the learned representations.
Overall, the RCIFM method is an important contribution to the field of representation learning, and its insights and techniques may inspire other researchers to develop new and innovative approaches for learning informative and interpretable representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Representation Learning with Conditional Information Flow Maximization
Dou Hu, Lingwei Wei, Wei Zhou, Songlin Hu
This paper proposes an information-theoretic representation learning framework, named conditional information flow maximization, to extract noise-invariant sufficient representations for the input data and target task. It promotes the learned representations have good feature uniformity and sufficient predictive ability, which can enhance the generalization of pre-trained language models (PLMs) for the target task. Firstly, an information flow maximization principle is proposed to learn more sufficient representations for the input and target by simultaneously maximizing both input-representation and representation-label mutual information. Unlike the information bottleneck, we handle the input-representation information in an opposite way to avoid the over-compression issue of latent representations. Besides, to mitigate the negative effect of potential redundant features from the input, we design a conditional information minimization principle to eliminate negative redundant features while preserve noise-invariant features. Experiments on 13 language understanding benchmarks demonstrate that our method effectively improves the performance of PLMs for classification and regression. Extensive experiments show that the learned representations are more sufficient, robust and transferable.
Read more8/13/2024

0
Leveraging Superfluous Information in Contrastive Representation Learning
Xuechu Yu
Contrastive representation learning, which aims to learnthe shared information between different views of unlabeled data by maximizing the mutual information between them, has shown its powerful competence in self-supervised learning for downstream tasks. However, recent works have demonstrated that more estimated mutual information does not guarantee better performance in different downstream tasks. Such works inspire us to conjecture that the learned representations not only maintain task-relevant information from unlabeled data but also carry task-irrelevant information which is superfluous for downstream tasks, thus leading to performance degeneration. In this paper we show that superfluous information does exist during the conventional contrastive learning framework, and further design a new objective, namely SuperInfo, to learn robust representations by a linear combination of both predictive and superfluous information. Besides, we notice that it is feasible to tune the coefficients of introduced losses to discard task-irrelevant information, while keeping partial non-shared task-relevant information according to our SuperInfo loss.We demonstrate that learning with our loss can often outperform the traditional contrastive learning approaches on image classification, object detection and instance segmentation tasks with significant improvements.
Read more8/21/2024

0
Revisiting Mutual Information Maximization for Generalized Category Discovery
Zhaorui Tan, Chengrui Zhang, Xi Yang, Jie Sun, Kaizhu Huang
Generalized category discovery presents a challenge in a realistic scenario, which requires the model's generalization ability to recognize unlabeled samples from known and unknown categories. This paper revisits the challenge of generalized category discovery through the lens of information maximization (InfoMax) with a probabilistic parametric classifier. Our findings reveal that ensuring independence between known and unknown classes while concurrently assuming a uniform probability distribution across all classes, yields an enlarged margin among known and unknown classes that promotes the model's performance. To achieve the aforementioned independence, we propose a novel InfoMax-based method, Regularized Parametric InfoMax (RPIM), which adopts pseudo labels to supervise unlabeled samples during InfoMax, while proposing a regularization to ensure the quality of the pseudo labels. Additionally, we introduce novel semantic-bias transformation to refine the features from the pre-trained model instead of direct fine-tuning to rescue the computational costs. Extensive experiments on six benchmark datasets validate the effectiveness of our method. RPIM significantly improves the performance regarding unknown classes, surpassing the state-of-the-art method by an average margin of 3.5%.
Read more6/3/2024
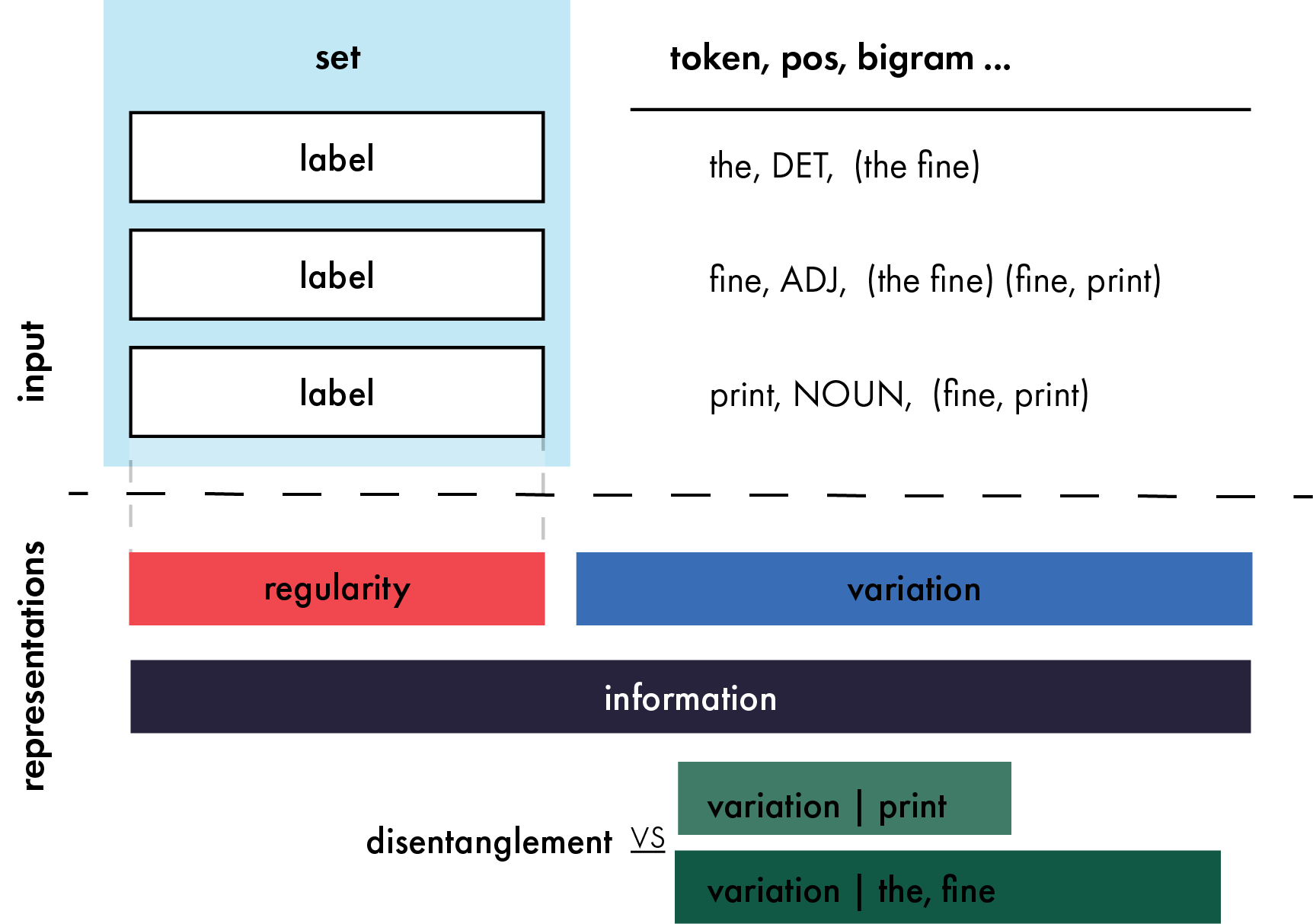
0
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Read more6/5/2024