Leveraging Systematic Knowledge of 2D Transformations
2206.00893
0
0
📶
Abstract
The existing deep learning models suffer from out-of-distribution (o.o.d.) performance drop in computer vision tasks. In comparison, humans have a remarkable ability to interpret images, even if the scenes in the images are rare, thanks to the systematicity of acquired knowledge. This work focuses on 1) the acquisition of systematic knowledge of 2D transformations, and 2) architectural components that can leverage the learned knowledge in image classification tasks in an o.o.d. setting. With a new training methodology based on synthetic datasets that are constructed under the causal framework, the deep neural networks acquire knowledge from semantically different domains (e.g. even from noise), and exhibit certain level of systematicity in parameter estimation experiments. Based on this, a novel architecture is devised consisting of a classifier, an estimator and an identifier (abbreviated as CED). By emulating the hypothesis-verification process in human visual perception, CED improves the classification accuracy significantly on test sets under covariate shift.
Create account to get full access
Overview
- Current deep learning models struggle with out-of-distribution (OOD) performance drops in computer vision tasks
- Humans have a remarkable ability to interpret even rare images, thanks to the systematicity of their acquired knowledge
- This work focuses on:
- Acquiring systematic knowledge of 2D transformations
- Developing architectural components that can leverage this learned knowledge for OOD image classification
Plain English Explanation
Deep learning models, which are a type of artificial intelligence, often struggle when presented with images or scenes that are different from what they were trained on. For example, a model trained on photos of dogs may have trouble recognizing a dog in a rare, unusual pose.
In contrast, humans are remarkably good at interpreting even unfamiliar images, thanks to the systematic knowledge we've built up over time. This paper explores two key ideas to help deep learning models match human-level performance on these out-of-distribution tasks:
-
Systematically learning 2D transformations: The researchers developed a new training approach that helps deep neural networks acquire knowledge about how 2D shapes and objects can be transformed, even from exposure to very different types of data, like noise.
-
Architecture designed for leveraging this knowledge: Building on the systematic transformation knowledge, the researchers created a new neural network architecture called CED, which emulates the hypothesis-verification process in human visual perception. This helps the model achieve significantly better classification accuracy on test sets with different distributions than the training data.
By taking inspiration from how humans learn and perceive the world, this research aims to make deep learning models more robust and flexible, so they can perform well even on unusual or rare images, just like people can.
Technical Explanation
The paper presents a new approach to address the out-of-distribution (OOD) performance drop that currently plagues deep learning models in computer vision tasks.
The researchers first developed a new training methodology based on synthetic datasets constructed under a causal framework. This allows deep neural networks to acquire systematic knowledge of 2D transformations, such as translation, rotation, and scaling, by learning from semantically different domains, including even noise.
Building on this acquired transformation knowledge, the researchers then devised a novel neural network architecture called CED, which consists of three main components:
- Classifier: Responsible for classifying the input image.
- Estimator: Estimates the parameters of the 2D transformations applied to the input image.
- Identifier: Identifies whether the input image is in-distribution or out-of-distribution.
By emulating the hypothesis-verification process in human visual perception, the CED architecture is able to significantly improve classification accuracy on OOD test sets, where the data distribution differs from the training data.
The paper presents experimental results demonstrating the effectiveness of this approach, which allows deep learning models to better generalize to rare or unusual images, similar to the remarkable abilities of human visual perception.
Critical Analysis
The paper presents a compelling approach to addressing the OOD performance issue in deep learning, drawing inspiration from the systematicity of human knowledge acquisition and visual perception. The proposed training methodology and CED architecture show promising results in improving classification accuracy on OOD test sets.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the approach. For example, the scalability of the synthetic dataset construction process and the computational complexity of the CED architecture are not extensively discussed.
Additionally, the paper could benefit from a more thorough exploration of potential failure cases or edge cases where the proposed method might still struggle. Investigating the model's performance on a wider range of OOD scenarios would help validate the robustness and generalizability of the approach.
Further research could also examine the transferability of the acquired 2D transformation knowledge to other computer vision tasks, such as object detection or semantic segmentation, to understand the broader applicability of the techniques developed in this work.
Conclusion
This paper presents a novel approach to addressing the out-of-distribution performance challenges faced by deep learning models in computer vision tasks. By systematically teaching neural networks about 2D transformations and designing an architecture that can effectively leverage this learned knowledge, the researchers have made progress towards achieving human-level flexibility and robustness in image interpretation.
The insights and techniques developed in this work have the potential to significantly improve the real-world performance of deep learning systems, enabling them to perform well even in rare or unusual circumstances, just as humans can. As the field of artificial intelligence continues to advance, research like this that draws inspiration from the human cognitive system could lead to even more powerful and capable machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
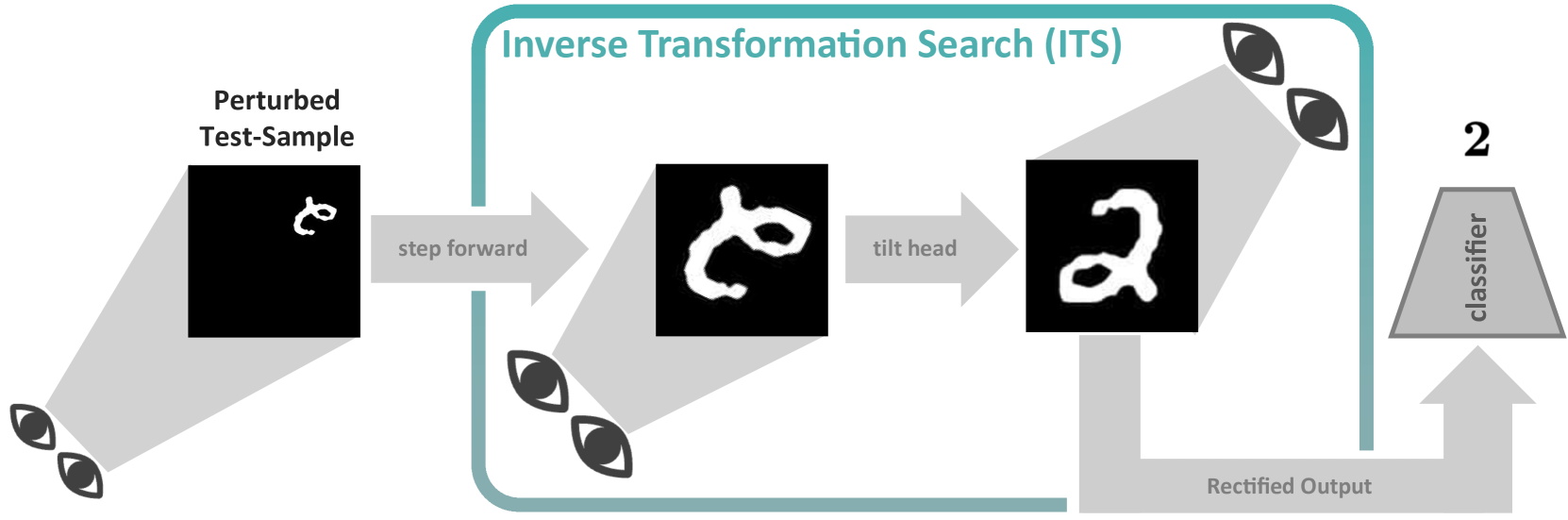
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
0
0
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
5/28/2024
🌀
Unexplored Faces of Robustness and Out-of-Distribution: Covariate Shifts in Environment and Sensor Domains
Eunsu Baek, Keondo Park, Jiyoon Kim, Hyung-Sin Kim
0
0
Computer vision applications predict on digital images acquired by a camera from physical scenes through light. However, conventional robustness benchmarks rely on perturbations in digitized images, diverging from distribution shifts occurring in the image acquisition process. To bridge this gap, we introduce a new distribution shift dataset, ImageNet-ES, comprising variations in environmental and camera sensor factors by directly capturing 202k images with a real camera in a controllable testbed. With the new dataset, we evaluate out-of-distribution (OOD) detection and model robustness. We find that existing OOD detection methods do not cope with the covariate shifts in ImageNet-ES, implying that the definition and detection of OOD should be revisited to embrace real-world distribution shifts. We also observe that the model becomes more robust in both ImageNet-C and -ES by learning environment and sensor variations in addition to existing digital augmentations. Lastly, our results suggest that effective shift mitigation via camera sensor control can significantly improve performance without increasing model size. With these findings, our benchmark may aid future research on robustness, OOD, and camera sensor control for computer vision. Our code and dataset are available at https://github.com/Edw2n/ImageNet-ES.
4/26/2024
🏋️
Out-of-Domain Generalization in Dynamical Systems Reconstruction
Niclas Goring, Florian Hess, Manuel Brenner, Zahra Monfared, Daniel Durstewitz
0
0
In science we are interested in finding the governing equations, the dynamical rules, underlying empirical phenomena. While traditionally scientific models are derived through cycles of human insight and experimentation, recently deep learning (DL) techniques have been advanced to reconstruct dynamical systems (DS) directly from time series data. State-of-the-art dynamical systems reconstruction (DSR) methods show promise in capturing invariant and long-term properties of observed DS, but their ability to generalize to unobserved domains remains an open challenge. Yet, this is a crucial property we would expect from any viable scientific theory. In this work, we provide a formal framework that addresses generalization in DSR. We explain why and how out-of-domain (OOD) generalization (OODG) in DSR profoundly differs from OODG considered elsewhere in machine learning. We introduce mathematical notions based on topological concepts and ergodic theory to formalize the idea of learnability of a DSR model. We formally prove that black-box DL techniques, without adequate structural priors, generally will not be able to learn a generalizing DSR model. We also show this empirically, considering major classes of DSR algorithms proposed so far, and illustrate where and why they fail to generalize across the whole phase space. Our study provides the first comprehensive mathematical treatment of OODG in DSR, and gives a deeper conceptual understanding of where the fundamental problems in OODG lie and how they could possibly be addressed in practice.
6/11/2024

The More You See in 2D, the More You Perceive in 3D
Xinyang Han, Zelin Gao, Angjoo Kanazawa, Shubham Goel, Yossi Gandelsman
0
0
Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
4/5/2024