Leveraging WaveNet for Dynamic Listening Head Modeling from Speech

0
🗣️
Sign in to get full access
Overview
- The paper aims to create realistic videos of a listener's facial responses during a conversation with a speaker.
- The goal is to generate believable listener reactions that capture subtle nuances and preserve individual identity.
- The approach uses a sequence-to-sequence model with a combination of WaveNet and Long Short-Term Memory (LSTM) networks.
- Experiments show the proposed method outperforms baseline models on the ViCo benchmark dataset.
Plain English Explanation
The researchers developed a system to simulate realistic facial responses from a listener during a face-to-face conversation. The idea is to create videos of a listener's head that respond naturally and authentically to what a single speaker is saying.
To do this, the researchers used a type of machine learning model called a sequence-to-sequence model. This model combines two other types of models: a WaveNet and a Long Short-Term Memory (LSTM) network.
The goal was to capture the subtle expressions and reactions that a listener might have during a conversation, while also preserving the individual identity of the listener. In other words, the facial responses should look genuine and true to the specific person.
When the researchers tested their system, they found that it performed better than other baseline models on a dataset called ViCo, which is used to evaluate this type of technology.
Technical Explanation
The paper presents a sequence-to-sequence model that combines a WaveNet and an LSTM network to generate realistic listener facial responses during a conversation.
The WaveNet component is used to model the high-frequency details of the listener's facial movements, while the LSTM network captures the temporal dynamics and contextual information. By integrating these two elements, the model is able to produce nuanced and natural-looking listener reactions that preserve the individual's identity.
The researchers trained and evaluated their model on the ViCo benchmark dataset, which contains videos of real-world conversations. Their experiments showed that the proposed approach outperforms other baseline methods in terms of generating believable and authentic listener facial responses.
Critical Analysis
The paper addresses an important challenge in simulating interactive communication and provides a technically sound solution. However, the authors do not discuss any potential limitations or caveats of their approach.
For example, the model may struggle to generalize to a wide range of speakers or conversation contexts, as the training data is likely biased. Additionally, the paper does not explore the ethics of generating synthetic facial responses, which could raise privacy concerns if used without proper consent.
Further research is needed to understand the broader implications of this technology and to address any potential issues or unintended consequences. Nonetheless, the researchers have made a valuable contribution to the field of interactive communication modeling.
Conclusion
This paper presents a novel approach for generating realistic listener facial responses during a conversation with a single speaker. By combining a WaveNet and an LSTM network, the researchers' sequence-to-sequence model is able to capture the subtle nuances and individual identity of the listener's facial expressions.
The results demonstrate that this method outperforms baseline models on the ViCo benchmark dataset, suggesting its potential for improving the realism and authenticity of interactive communication systems. However, the authors do not address potential limitations or ethical considerations, which should be explored in future research.
Overall, this work represents an important step forward in the field of interactive communication modeling, with potential applications in areas such as virtual assistants, telepresence, and social robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Leveraging WaveNet for Dynamic Listening Head Modeling from Speech
Minh-Duc Nguyen, Hyung-Jeong Yang, Seung-Won Kim, Ji-Eun Shin, Soo-Hyung Kim
The creation of listener facial responses aims to simulate interactive communication feedback from a listener during a face-to-face conversation. Our goal is to generate believable videos of listeners' heads that respond authentically to a single speaker by a sequence-to-sequence model with an combination of WaveNet and Long short-term memory network. Our approach focuses on capturing the subtle nuances of listener feedback, ensuring the preservation of individual listener identity while expressing appropriate attitudes and viewpoints. Experiment results show that our method surpasses the baseline models on ViCo benchmark Dataset.
Read more9/10/2024

0
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
Read more4/1/2024

0
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Kim Sung-Bin, Lee Chae-Yeon, Gihun Son, Oh Hyun-Bin, Janghoon Ju, Suekyeong Nam, Tae-Hyun Oh
Recent studies in speech-driven 3D talking head generation have achieved convincing results in verbal articulations. However, generating accurate lip-syncs degrades when applied to input speech in other languages, possibly due to the lack of datasets covering a broad spectrum of facial movements across languages. In this work, we introduce a novel task to generate 3D talking heads from speeches of diverse languages. We collect a new multilingual 2D video dataset comprising over 420 hours of talking videos in 20 languages. With our proposed dataset, we present a multilingually enhanced model that incorporates language-specific style embeddings, enabling it to capture the unique mouth movements associated with each language. Additionally, we present a metric for assessing lip-sync accuracy in multilingual settings. We demonstrate that training a 3D talking head model with our proposed dataset significantly enhances its multilingual performance. Codes and datasets are available at https://multi-talk.github.io/.
Read more6/21/2024
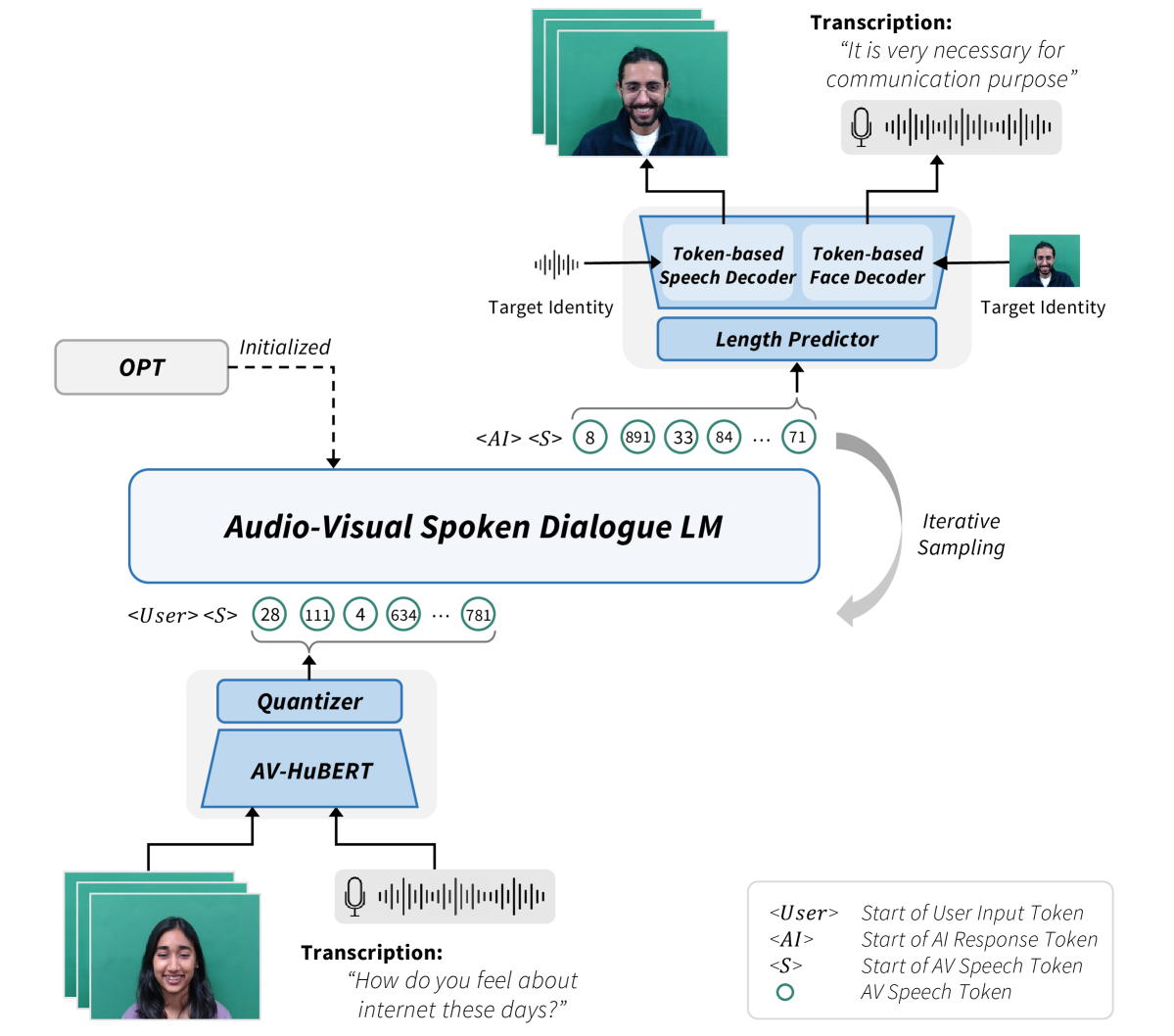
0
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, Joanna Hong, Jeong Hun Yeo, Yong Man Ro
In this paper, we introduce a novel Face-to-Face spoken dialogue model. It processes audio-visual speech from user input and generates audio-visual speech as the response, marking the initial step towards creating an avatar chatbot system without relying on intermediate text. To this end, we newly introduce MultiDialog, the first large-scale multimodal (i.e., audio and visual) spoken dialogue corpus containing 340 hours of approximately 9,000 dialogues, recorded based on the open domain dialogue dataset, TopicalChat. The MultiDialog contains parallel audio-visual recordings of conversation partners acting according to the given script with emotion annotations, which we expect to open up research opportunities in multimodal synthesis. Our Face-to-Face spoken dialogue model incorporates a textually pretrained large language model and adapts it into the audio-visual spoken dialogue domain by incorporating speech-text joint pretraining. Through extensive experiments, we validate the effectiveness of our model in facilitating a face-to-face conversation. Demo and data are available at https://multidialog.github.io and https://huggingface.co/datasets/IVLLab/MultiDialog, respectively.
Read more8/6/2024