Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation

0
Sign in to get full access
Overview
- This paper presents a novel spoken dialogue model for face-to-face conversations, called "Let's Go Real Talk".
- The model aims to enable natural and engaging spoken interactions between AI agents and humans in a face-to-face setting.
- The researchers develop a comprehensive framework that jointly models the verbal and nonverbal components of conversation, drawing inspiration from human communication patterns.
Plain English Explanation
The paper describes a new approach to building AI systems that can have natural conversations with people. The key idea is to create an AI agent that can not only understand and respond to what someone is saying, but also pick up on and respond to their body language, facial expressions, and other nonverbal cues - just like how people communicate with each other in real life.
The researchers developed a comprehensive framework that models both the verbal and nonverbal aspects of conversation. This allows the AI to have more lifelike and engaging interactions, where it can pick up on and respond to social signals beyond just the words being spoken. By taking inspiration from how humans communicate, the aim is to make the interactions feel more natural and human-like.
This could have applications in areas like Faces That Speak, Timed Conversations, Audio-Driven Talking Faces, and Emotional Conversations, where AI agents need to engage in natural dialogue while also responding to nonverbal cues.
Technical Explanation
The paper proposes a "Let's Go Real Talk" framework for building spoken dialogue models that can engage in natural face-to-face conversations. The key innovation is the comprehensive modeling of both verbal and nonverbal aspects of interaction.
On the verbal side, the model utilizes state-of-the-art language understanding and generation techniques to engage in fluent, contextually-appropriate dialogue. This builds on prior work in areas like Modeling Real-Time Interactive Conversations.
Crucially, the framework also models nonverbal communication, such as facial expressions, head movements, and body language. This allows the AI agent to pick up on social signals and respond accordingly, rather than just focusing on the literal meaning of the words. The researchers draw inspiration from how humans seamlessly integrate verbal and nonverbal cues during face-to-face interactions.
The model is trained on a large corpus of human-to-human conversational data, which captures the natural flow and interplay of verbal and nonverbal behaviors. This enables the AI to learn patterns and subtleties of human communication that can then be applied to its own interactions.
Critical Analysis
The paper presents a well-designed and comprehensive approach to building more natural, human-like conversational AI. The integration of verbal and nonverbal modeling is a key strength, as it allows the system to engage in a richer form of interaction that better reflects real-world communication dynamics.
That said, the authors acknowledge some limitations of the current work. For example, the model may struggle with highly context-dependent or ambiguous conversational scenarios, where human intuition and common sense reasoning play a large role. There is also the challenge of scaling the model to handle a wide range of conversational topics and situations.
Additionally, the paper does not address potential biases or ethical concerns that could arise from such advanced conversational AI systems. As these models become more sophisticated, there will be important questions to consider around transparency, accountability, and the societal impact of increasingly human-like digital agents.
Overall, the "Let's Go Real Talk" framework represents an exciting step forward in building more natural and engaging spoken dialogue systems. However, continued research and careful consideration of the technology's implications will be crucial as this field continues to advance.
Conclusion
This paper presents a novel approach to building spoken dialogue models that can engage in natural, face-to-face conversations. By comprehensively modeling both the verbal and nonverbal aspects of interaction, the "Let's Go Real Talk" framework aims to enable more lifelike and responsive AI agents.
The integration of verbal and nonverbal communication is a key strength of the approach, as it allows the system to pick up on and respond to social cues in a way that better reflects human communication patterns. This could have significant applications in areas like 3D Talking Faces and Emotional Conversations.
While the paper presents a well-designed and comprehensive framework, the authors acknowledge some limitations and areas for further research. As this technology continues to advance, it will be important to carefully consider the ethical implications and potential societal impacts of increasingly human-like conversational AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Let's Go Real Talk: Spoken Dialogue Model for Face-to-Face Conversation
Se Jin Park, Chae Won Kim, Hyeongseop Rha, Minsu Kim, Joanna Hong, Jeong Hun Yeo, Yong Man Ro
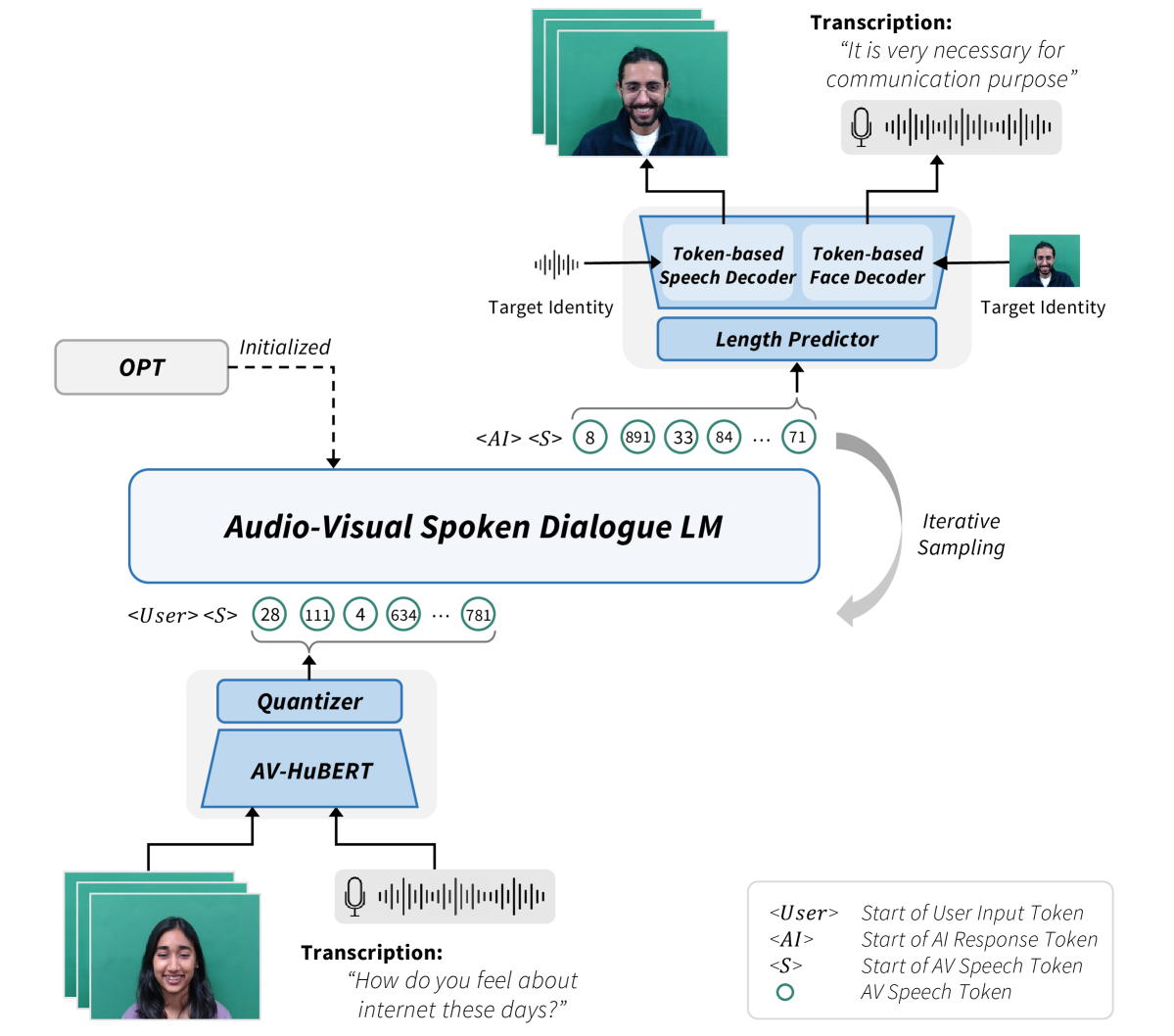
In this paper, we introduce a novel Face-to-Face spoken dialogue model. It processes audio-visual speech from user input and generates audio-visual speech as the response, marking the initial step towards creating an avatar chatbot system without relying on intermediate text. To this end, we newly introduce MultiDialog, the first large-scale multimodal (i.e., audio and visual) spoken dialogue corpus containing 340 hours of approximately 9,000 dialogues, recorded based on the open domain dialogue dataset, TopicalChat. The MultiDialog contains parallel audio-visual recordings of conversation partners acting according to the given script with emotion annotations, which we expect to open up research opportunities in multimodal synthesis. Our Face-to-Face spoken dialogue model incorporates a textually pretrained large language model and adapts it into the audio-visual spoken dialogue domain by incorporating speech-text joint pretraining. Through extensive experiments, we validate the effectiveness of our model in facilitating a face-to-face conversation. Demo and data are available at https://multidialog.github.io and https://huggingface.co/datasets/IVLLab/MultiDialog, respectively.
Read more8/6/2024
0
Faces that Speak: Jointly Synthesising Talking Face and Speech from Text
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, Joon Son Chung
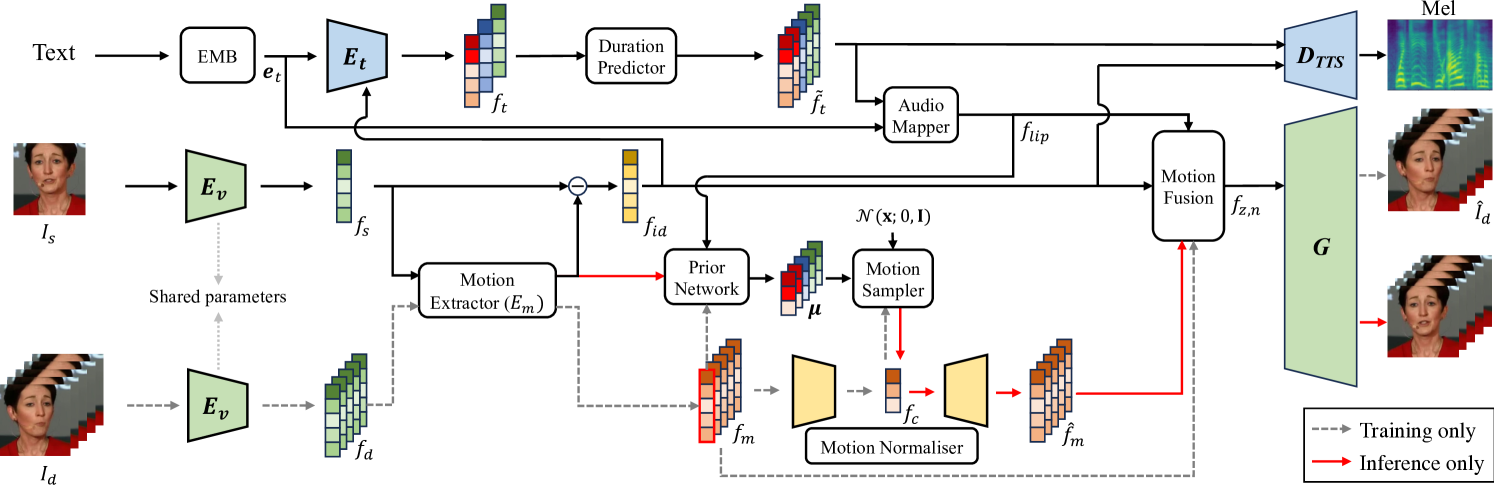
The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
Read more5/17/2024
➖
0
Modeling Real-Time Interactive Conversations as Timed Diarized Transcripts
Garrett Tanzer, Gustaf Ahdritz, Luke Melas-Kyriazi
Chatbots built upon language models have exploded in popularity, but they have largely been limited to synchronous, turn-by-turn dialogues. In this paper we present a simple yet general method to simulate real-time interactive conversations using pretrained text-only language models, by modeling timed diarized transcripts and decoding them with causal rejection sampling. We demonstrate the promise of this method with two case studies: instant messenger dialogues and spoken conversations, which require generation at about 30 tok/s and 20 tok/s respectively to maintain real-time interactivity. These capabilities can be added into language models using relatively little data and run on commodity hardware.
Read more5/24/2024

0
Style-Talker: Finetuning Audio Language Model and Style-Based Text-to-Speech Model for Fast Spoken Dialogue Generation
Yinghao Aaron Li, Xilin Jiang, Jordan Darefsky, Ge Zhu, Nima Mesgarani
The rapid advancement of large language models (LLMs) has significantly propelled the development of text-based chatbots, demonstrating their capability to engage in coherent and contextually relevant dialogues. However, extending these advancements to enable end-to-end speech-to-speech conversation bots remains a formidable challenge, primarily due to the extensive dataset and computational resources required. The conventional approach of cascading automatic speech recognition (ASR), LLM, and text-to-speech (TTS) models in a pipeline, while effective, suffers from unnatural prosody because it lacks direct interactions between the input audio and its transcribed text and the output audio. These systems are also limited by their inherent latency from the ASR process for real-time applications. This paper introduces Style-Talker, an innovative framework that fine-tunes an audio LLM alongside a style-based TTS model for fast spoken dialog generation. Style-Talker takes user input audio and uses transcribed chat history and speech styles to generate both the speaking style and text for the response. Subsequently, the TTS model synthesizes the speech, which is then played back to the user. While the response speech is being played, the input speech undergoes ASR processing to extract the transcription and speaking style, serving as the context for the ensuing dialogue turn. This novel pipeline accelerates the traditional cascade ASR-LLM-TTS systems while integrating rich paralinguistic information from input speech. Our experimental results show that Style-Talker significantly outperforms the conventional cascade and speech-to-speech baselines in terms of both dialogue naturalness and coherence while being more than 50% faster.
Read more8/23/2024