LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion

0
Sign in to get full access
Overview
- The paper proposes an efficient and accurate end-to-end lane-level planning system called LFP that uses a fusion of camera and LiDAR sensors.
- LFP combines perception, prediction, and planning into a single neural network, enabling it to efficiently plan along the entire lane.
- The system achieves state-of-the-art performance on various public benchmarks for lane-level planning.
Plain English Explanation
The paper introduces a new system called LFP (Lane-level Planning) that can efficiently and accurately plan the entire route along a lane using a combination of camera and LiDAR sensors. LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion
Unlike traditional systems that separate perception, prediction, and planning into distinct modules, LFP combines all of these capabilities into a single neural network. This allows the system to plan the entire route along a lane in an end-to-end fashion, rather than having to pass information between different components.
By fusing data from both cameras and LiDAR sensors, LFP is able to perceive the environment more accurately than systems that rely on just one sensor type. The camera provides visual information about lane markings and other visual cues, while the LiDAR provides precise 3D data about the geometry of the surroundings.
The paper demonstrates that LFP achieves state-of-the-art performance on various public benchmarks for lane-level planning, outperforming other leading approaches. This suggests that the camera-LiDAR fusion and end-to-end architecture of LFP are effective at enabling efficient and accurate lane-level planning for autonomous vehicles.
Technical Explanation
The LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion paper presents a novel system for end-to-end lane-level planning that combines perception, prediction, and planning into a single neural network architecture.
The key innovations of LFP include:
-
Camera-LiDAR Fusion: LFP fuses data from both camera and LiDAR sensors to leverage the complementary strengths of each modality. Cameras provide rich visual information about lane markings and other cues, while LiDAR provides precise 3D geometry.
-
End-to-End Architecture: Unlike traditional systems that separate perception, prediction, and planning, LFP integrates all of these capabilities into a single neural network. This allows the system to efficiently plan the entire route along a lane in an end-to-end fashion.
-
Efficient Planning: By combining all the planning components into a single model, LFP is able to achieve high computational efficiency compared to multi-stage planning pipelines.
The authors evaluate LFP on several public benchmarks for lane-level planning and show that it outperforms other state-of-the-art approaches. This demonstrates the effectiveness of the camera-LiDAR fusion and end-to-end architecture in enabling accurate and efficient lane-level planning for autonomous vehicles.
Critical Analysis
The LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion paper presents a compelling approach to lane-level planning, but there are a few potential limitations and areas for further research:
-
Sensor Failure Modes: While the camera-LiDAR fusion approach helps improve robustness, the system may still be vulnerable to failure modes of each individual sensor, such as camera occlusion or LiDAR sensor errors. Further research could explore ways to make the system more resilient to sensor failures.
-
Generalization to Complex Environments: The paper primarily evaluates LFP on relatively simple highway scenarios. It would be important to assess the system's performance in more complex urban environments with varying lane structures, traffic conditions, and environmental factors.
-
Ethical Considerations: As with any autonomous driving system, there are important ethical questions around safety, accountability, and the system's decision-making processes that should be carefully considered.
-
Computational Efficiency: While the paper claims LFP is computationally efficient, it would be helpful to have more detailed benchmarks on metrics like inference time and power consumption to better understand the real-world deployment implications.
Overall, the LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion paper presents an innovative approach to lane-level planning that shows promise, but further research and testing would be valuable to address these potential limitations.
Conclusion
The LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion paper introduces a novel system called LFP that combines perception, prediction, and planning into a single end-to-end neural network architecture. By fusing data from camera and LiDAR sensors, LFP is able to achieve state-of-the-art performance on various lane-level planning benchmarks, demonstrating the effectiveness of this approach.
While the paper presents a compelling solution, there are a few areas for potential improvement, such as addressing sensor failure modes, evaluating performance in complex environments, and further analyzing the computational efficiency. Nevertheless, the innovations introduced in LFP represent an important step forward in enabling more efficient and accurate autonomous vehicle navigation at the lane level.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion
Guoliang You, Xiaomeng Chu, Yifan Duan, Xingchen Li, Sha Zhang, Jianmin Ji, Yanyong Zhang
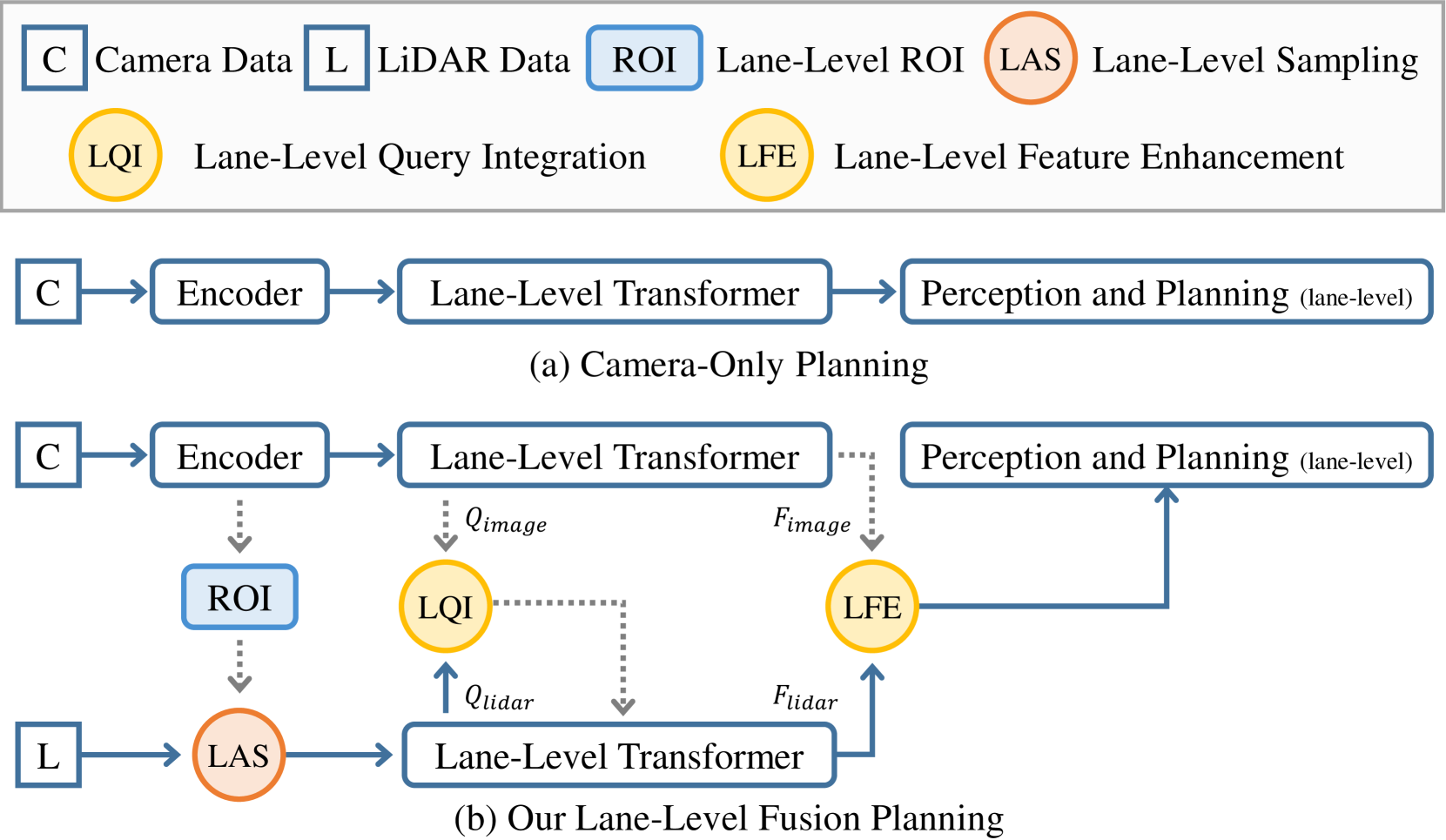
Multi-modal systems enhance performance in autonomous driving but face inefficiencies due to indiscriminate processing within each modality. Additionally, the independent feature learning of each modality lacks interaction, which results in extracted features that do not possess the complementary characteristics. These issue increases the cost of fusing redundant information across modalities. To address these challenges, we propose targeting driving-relevant elements, which reduces the volume of LiDAR features while preserving critical information. This approach enhances lane level interaction between the image and LiDAR branches, allowing for the extraction and fusion of their respective advantageous features. Building upon the camera-only framework PHP, we introduce the Lane-level camera-LiDAR Fusion Planning (LFP) method, which balances efficiency with performance by using lanes as the unit for sensor fusion. Specifically, we design three modules to enhance efficiency and performance. For efficiency, we propose an image-guided coarse lane prior generation module that forecasts the region of interest (ROI) for lanes and assigns a confidence score, guiding LiDAR processing. The LiDAR feature extraction modules leverages lane-aware priors from the image branch to guide sampling for pillar, retaining essential pillars. For performance, the lane-level cross-modal query integration and feature enhancement module uses confidence score from ROI to combine low-confidence image queries with LiDAR queries, extracting complementary depth features. These features enhance the low-confidence image features, compensating for the lack of depth. Experiments on the Carla benchmarks show that our method achieves state-of-the-art performance in both driving score and infraction score, with maximum improvement of 15% and 14% over existing algorithms, respectively, maintaining high frame rate of 19.27 FPS.
Read more9/24/2024
🚀
0
Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion
Haisong Liu, Tao Lu, Yihui Xu, Jia Liu, Limin Wang
In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline that splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, which consists of 2D and 3D branches with multiple bidirectional fusion connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to extract the LiDAR features, as it preserves the geometric structure of point clouds. To fuse dense image features and sparse point features, we propose a learnable operator named bidirectional camera-LiDAR fusion module (Bi-CLFM). We instantiate two types of the bidirectional fusion pipeline, one based on the pyramidal coarse-to-fine architecture (dubbed CamLiPWC), and the other one based on the recurrent all-pairs field transforms (dubbed CamLiRAFT). On FlyingThings3D, both CamLiPWC and CamLiRAFT surpass all existing methods and achieve up to a 47.9% reduction in 3D end-point-error from the best published result. Our best-performing model, CamLiRAFT, achieves an error of 4.26% on the KITTI Scene Flow benchmark, ranking 1st among all submissions with much fewer parameters. Besides, our methods have strong generalization performance and the ability to handle non-rigid motion. Code is available at https://github.com/MCG-NJU/CamLiFlow.
Read more4/9/2024

0
Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection
Yiran Yang, Xu Gao, Tong Wang, Xin Hao, Yifeng Shi, Xiao Tan, Xiaoqing Ye, Jingdong Wang
Camera and LiDAR serve as informative sensors for accurate and robust autonomous driving systems. However, these sensors often exhibit heterogeneous natures, resulting in distributional modality gaps that present significant challenges for fusion. To address this, a robust fusion technique is crucial, particularly for enhancing 3D object detection. In this paper, we introduce a dynamic adjustment technology aimed at aligning modal distributions and learning effective modality representations to enhance the fusion process. Specifically, we propose a triphase domain aligning module. This module adjusts the feature distributions from both the camera and LiDAR, bringing them closer to the ground truth domain and minimizing differences. Additionally, we explore improved representation acquisition methods for dynamic fusion, which includes modal interaction and specialty enhancement. Finally, an adaptive learning technique that merges the semantics and geometry information for dynamical instance optimization. Extensive experiments in the nuScenes dataset present competitive performance with state-of-the-art approaches. Our code will be released in the future.
Read more7/23/2024

0
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, Ziwei Liu
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
Read more5/9/2024