LiCAF: LiDAR-Camera Asymmetric Fusion for Gait Recognition

0

Sign in to get full access
Overview
- This paper introduces LiCAF, a novel approach for gait recognition that fuses information from LiDAR and camera sensors.
- Gait recognition is the task of identifying individuals based on their walking patterns, which can be useful for security and surveillance applications.
- The authors propose an asymmetric fusion strategy that leverages the complementary strengths of LiDAR and camera data to improve gait recognition performance.
Plain English Explanation
The paper presents a new method called LiCAF for recognizing people based on how they walk. Recognizing someone by their gait can be useful for things like security and tracking people in an area.
LiCAF combines information from two different types of sensors - LiDAR, which uses lasers to measure distances, and cameras, which capture visual images. The key idea is that LiDAR and cameras each provide unique information that can be used together to more accurately identify individuals by their walking patterns.
The authors' "asymmetric fusion" strategy means they don't just blindly combine the LiDAR and camera data. Instead, they have a specialized approach to fuse the data in a way that takes advantage of the strengths of each sensor. This leads to better overall gait recognition performance compared to using LiDAR or cameras alone.
Technical Explanation
The paper proposes the LiCAF (LiDAR-Camera Asymmetric Fusion) framework for gait recognition. LiCAF combines information from LiDAR and camera sensors to improve gait recognition.
The key innovation is the asymmetric fusion strategy, which allows the system to selectively leverage the complementary strengths of LiDAR and camera data. LiDAR provides accurate 3D spatial information, while cameras capture detailed visual cues. By fusing these modalities in an asymmetric way, LiCAF can achieve better gait recognition performance compared to using either sensor alone or simple fusion approaches.
The LiCAF framework consists of three main components: 1) LiDAR-based pose estimation, 2) Camera-based appearance modeling, and 3) an asymmetric fusion module. These components work together to leverage the strengths of LiDAR and cameras for robust gait recognition.
The authors evaluate LiCAF on standard gait recognition benchmarks and demonstrate significant improvements over prior state-of-the-art methods. LiCAF's asymmetric fusion strategy proves effective at combining LiDAR and camera data for enhanced gait-based person identification.
Critical Analysis
The paper provides a thorough technical explanation of the LiCAF framework and presents compelling experimental results. However, some potential limitations or areas for further research are not discussed:
- The authors do not explore the computational and memory efficiency of the LiCAF model, which could be an important practical consideration for real-world deployment.
- The paper focuses on controlled laboratory settings, so the generalization of LiCAF to more unconstrained "in the wild" scenarios is unclear.
- The fusion strategy is asymmetric, but the authors do not provide much intuition or analysis on why this specific form of asymmetry is beneficial compared to other fusion approaches.
Overall, the LiCAF method represents a promising advance in multimodal gait recognition, but further research is needed to fully understand its strengths, weaknesses, and potential real-world impact. Continued work on cross-modal gait recognition techniques like LiCAF could lead to more robust and practical person identification systems.
Conclusion
This paper introduces LiCAF, a novel approach for gait recognition that fuses data from LiDAR and camera sensors using an asymmetric fusion strategy. The key insight is that LiDAR and cameras provide complementary information that can be effectively combined to improve gait-based person identification.
LiCAF's fusion mechanism allows it to selectively leverage the strengths of each sensor modality, leading to better performance compared to using LiDAR or cameras alone. The technical evaluation demonstrates the effectiveness of the LiCAF framework on standard benchmarks.
While the paper presents a promising advance in multimodal gait recognition, further research is needed to fully understand the practical benefits and limitations of the approach. Continued work in this direction could lead to more robust and widely applicable person identification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LiCAF: LiDAR-Camera Asymmetric Fusion for Gait Recognition
Yunze Deng, Haijun Xiong, Bin Feng
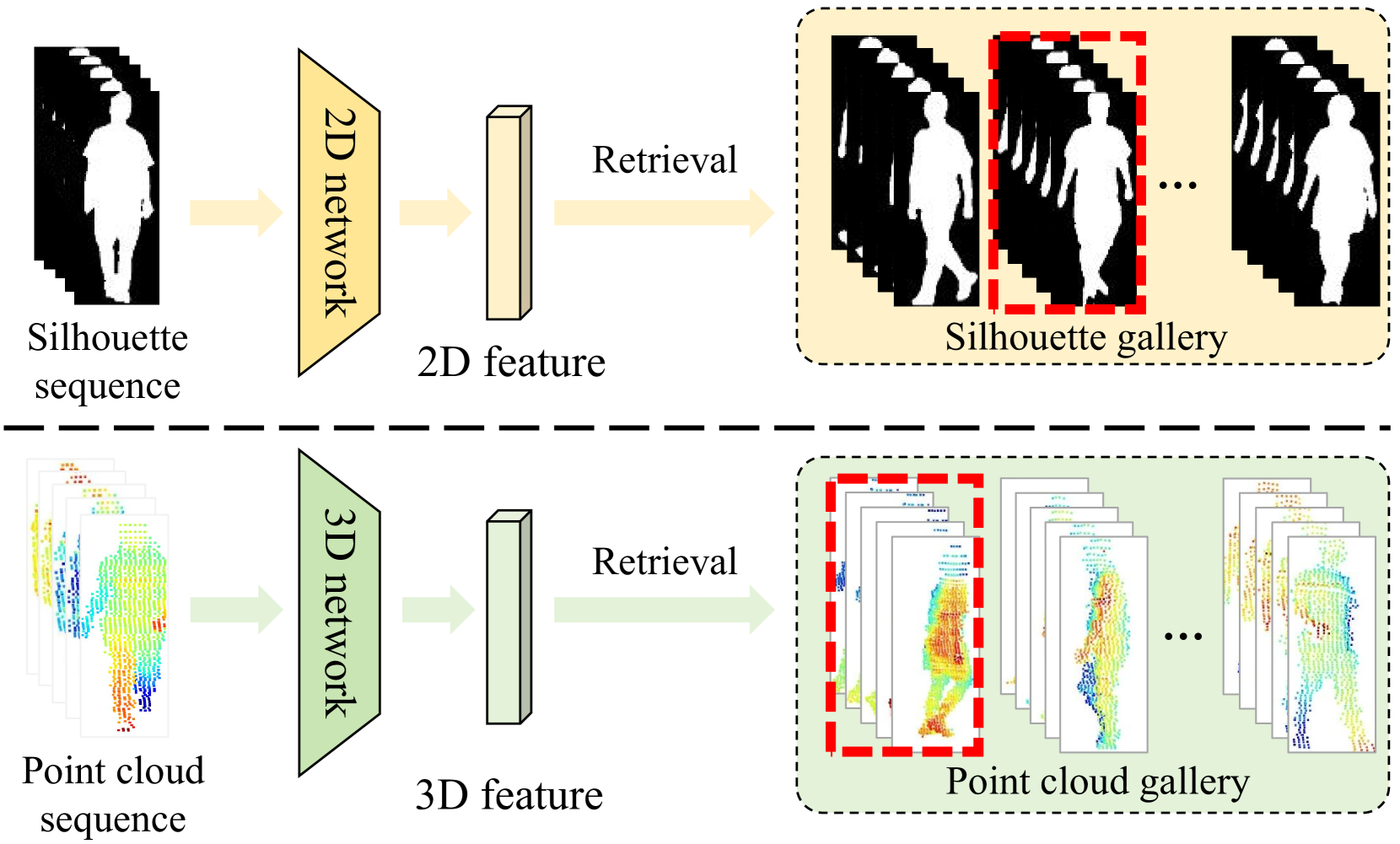
Gait recognition is a biometric technology that identifies individuals by using walking patterns. Due to the significant achievements of multimodal fusion in gait recognition, we consider employing LiDAR-camera fusion to obtain robust gait representations. However, existing methods often overlook intrinsic characteristics of modalities, and lack fine-grained fusion and temporal modeling. In this paper, we introduce a novel modality-sensitive network LiCAF for LiDAR-camera fusion, which employs an asymmetric modeling strategy. Specifically, we propose Asymmetric Cross-modal Channel Attention (ACCA) and Interlaced Cross-modal Temporal Modeling (ICTM) for cross-modal valuable channel information selection and powerful temporal modeling. Our method achieves state-of-the-art performance (93.9% in Rank-1 and 98.8% in Rank-5) on the SUSTech1K dataset, demonstrating its effectiveness.
Read more6/19/2024
0
Camera-LiDAR Cross-modality Gait Recognition
Wenxuan Guo, Yingping Liang, Zhiyu Pan, Ziheng Xi, Jianjiang Feng, Jie Zhou
Gait recognition is a crucial biometric identification technique. Camera-based gait recognition has been widely applied in both research and industrial fields. LiDAR-based gait recognition has also begun to evolve most recently, due to the provision of 3D structural information. However, in certain applications, cameras fail to recognize persons, such as in low-light environments and long-distance recognition scenarios, where LiDARs work well. On the other hand, the deployment cost and complexity of LiDAR systems limit its wider application. Therefore, it is essential to consider cross-modality gait recognition between cameras and LiDARs for a broader range of applications. In this work, we propose the first cross-modality gait recognition framework between Camera and LiDAR, namely CL-Gait. It employs a two-stream network for feature embedding of both modalities. This poses a challenging recognition task due to the inherent matching between 3D and 2D data, exhibiting significant modality discrepancy. To align the feature spaces of the two modalities, i.e., camera silhouettes and LiDAR points, we propose a contrastive pre-training strategy to mitigate modality discrepancy. To make up for the absence of paired camera-LiDAR data for pre-training, we also introduce a strategy for generating data on a large scale. This strategy utilizes monocular depth estimated from single RGB images and virtual cameras to generate pseudo point clouds for contrastive pre-training. Extensive experiments show that the cross-modality gait recognition is very challenging but still contains potential and feasibility with our proposed model and pre-training strategy. To the best of our knowledge, this is the first work to address cross-modality gait recognition.
Read more7/8/2024
🤯
0
Cross-Modality Gait Recognition: Bridging LiDAR and Camera Modalities for Human Identification
Rui Wang, Chuanfu Shen, Manuel J. Marin-Jimenez, George Q. Huang, Shiqi Yu
Current gait recognition research mainly focuses on identifying pedestrians captured by the same type of sensor, neglecting the fact that individuals may be captured by different sensors in order to adapt to various environments. A more practical approach should involve cross-modality matching across different sensors. Hence, this paper focuses on investigating the problem of cross-modality gait recognition, with the objective of accurately identifying pedestrians across diverse vision sensors. We present CrossGait inspired by the feature alignment strategy, capable of cross retrieving diverse data modalities. Specifically, we investigate the cross-modality recognition task by initially extracting features within each modality and subsequently aligning these features across modalities. To further enhance the cross-modality performance, we propose a Prototypical Modality-shared Attention Module that learns modality-shared features from two modality-specific features. Additionally, we design a Cross-modality Feature Adapter that transforms the learned modality-specific features into a unified feature space. Extensive experiments conducted on the SUSTech1K dataset demonstrate the effectiveness of CrossGait: (1) it exhibits promising cross-modality ability in retrieving pedestrians across various modalities from different sensors in diverse scenes, and (2) CrossGait not only learns modality-shared features for cross-modality gait recognition but also maintains modality-specific features for single-modality recognition.
Read more4/8/2024

0
GaitMA: Pose-guided Multi-modal Feature Fusion for Gait Recognition
Fanxu Min, Shaoxiang Guo, Fan Hao, Junyu Dong
Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Existing appearance-based methods utilize CNN or Transformer to extract spatial and temporal features from silhouettes, while model-based methods employ GCN to focus on the special topological structure of skeleton points. However, the quality of silhouettes is limited by complex occlusions, and skeletons lack dense semantic features of the human body. To tackle these problems, we propose a novel gait recognition framework, dubbed Gait Multi-model Aggregation Network (GaitMA), which effectively combines two modalities to obtain a more robust and comprehensive gait representation for recognition. First, skeletons are represented by joint/limb-based heatmaps, and features from silhouettes and skeletons are respectively extracted using two CNN-based feature extractors. Second, a co-attention alignment module is proposed to align the features by element-wise attention. Finally, we propose a mutual learning module, which achieves feature fusion through cross-attention, Wasserstein loss is further introduced to ensure the effective fusion of two modalities. Extensive experimental results demonstrate the superiority of our model on Gait3D, OU-MVLP, and CASIA-B.
Read more7/23/2024