LIDAO: Towards Limited Interventions for Debiasing (Large) Language Models

0
💬
Sign in to get full access
Overview
- This paper proposes a new method called "LIDAO" (Limited Interventions for Debiasing (Large) Language Models) to debias large language models while using minimal interventions.
- The key idea is to identify and target specific biases in the model's outputs, rather than attempting to fully debias the entire model.
- The authors demonstrate the effectiveness of LIDAO on several language models and datasets, showing that it can mitigate biases while preserving the model's performance on downstream tasks.
Plain English Explanation
The paper introduces a new approach called LIDAO (Limited Interventions for Debiasing (Large) Language Models) to address biases in large language models. These models, such as GPT-3, can sometimes generate text that reflects societal biases, such as gender or racial stereotypes.
Rather than trying to completely remove all biases from the model, the LIDAO method aims to target specific biases that are identified in the model's outputs. The key idea is to make small, targeted changes to the model to mitigate these biases, without drastically altering the model's overall performance on other tasks.
The authors demonstrate that LIDAO can effectively reduce biases in the outputs of several different language models, while still maintaining the models' capabilities on other important tasks. This suggests that LIDAO could be a practical and efficient way to make large language models more fair and unbiased, without having to completely retrain or rebuild them from scratch.
Technical Explanation
The paper proposes the LIDAO (Limited Interventions for Debiasing (Large) Language Models) method to address biases in large language models. The core idea is to identify specific biases in the model's outputs and then make targeted interventions to mitigate those biases, rather than attempting to fully debias the entire model.
The LIDAO method involves three key steps:
- Bias Identification: The authors use a combination of existing bias evaluation metrics and human evaluation to identify specific biases in the model's outputs.
- Intervention Design: Based on the identified biases, the authors design targeted interventions to the model's parameters or training data to reduce those biases.
- Evaluation: The authors evaluate the effectiveness of the interventions by measuring bias reduction and the impact on the model's performance on downstream tasks.
The authors demonstrate the effectiveness of LIDAO on several large language models, including GPT-3 and BERT, and across multiple datasets and bias evaluation tasks. They show that LIDAO can successfully mitigate specific biases while preserving the model's overall performance.
This approach of limited, targeted interventions contrasts with more sweeping debiasing techniques that aim to fully debias the entire model. The authors argue that LIDAO is a more practical and efficient solution, as it avoids the potential drawbacks of more aggressive debiasing methods, such as significant performance degradation.
Critical Analysis
The LIDAO method represents a promising approach to addressing biases in large language models. By focusing on targeted interventions rather than full debiasing, the authors demonstrate an efficient way to mitigate specific biases while maintaining model performance.
However, the paper also acknowledges some limitations of the LIDAO method. The success of the interventions is dependent on accurately identifying the relevant biases in the model's outputs, which can be challenging. Additionally, the paper does not explore the long-term stability of the debiasing interventions or whether the biases could resurface over time.
Furthermore, the paper does not delve into the potential societal implications of deploying language models with partially mitigated biases. There may be concerns around the residual biases that remain or the potential for users to misinterpret the model's outputs as being completely unbiased.
Debiasing algorithm through model adaptation and Evaluating & Mitigating Linguistic Discrimination in Large Language Models provide additional perspectives on the challenges and trade-offs involved in debiasing language models.
Conclusion
The LIDAO method proposed in this paper represents a promising approach to addressing biases in large language models. By focusing on targeted interventions to mitigate specific biases, the authors demonstrate a practical and efficient way to improve the fairness of these powerful AI systems without significantly compromising their overall performance.
While the LIDAO method has some limitations, it contributes to the ongoing efforts to create more equitable and inclusive language models that can be safely deployed in real-world applications. As the field of AI continues to grapple with the challenges of bias and fairness, the insights from this paper can inform future research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
LIDAO: Towards Limited Interventions for Debiasing (Large) Language Models
Tianci Liu, Haoyu Wang, Shiyang Wang, Yu Cheng, Jing Gao
Large language models (LLMs) have achieved impressive performance on various natural language generation tasks. Nonetheless, they suffer from generating negative and harmful contents that are biased against certain demographic groups (e.g., female), raising severe fairness concerns. As remedies, prior works intervened the generation by removing attitude or demographic information, inevitably degrading the generation quality and resulting in notable textit{fairness-fluency} trade-offs. However, it is still under-explored to what extent the fluency textit{has to} be affected in order to achieve a desired level of fairness. In this work, we conduct the first formal study from an information-theoretic perspective. We show that previous approaches are excessive for debiasing and propose LIDAO, a general framework to debias a (L)LM at a better fluency provably. We further robustify LIDAO in adversarial scenarios, where a carefully-crafted prompt may stimulate LLMs exhibiting instruction-following abilities to generate texts with fairness issue appears only when the prompt is also taken into account. Experiments on three LMs ranging from 0.7B to 7B parameters demonstrate the superiority of our method.
Read more6/4/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
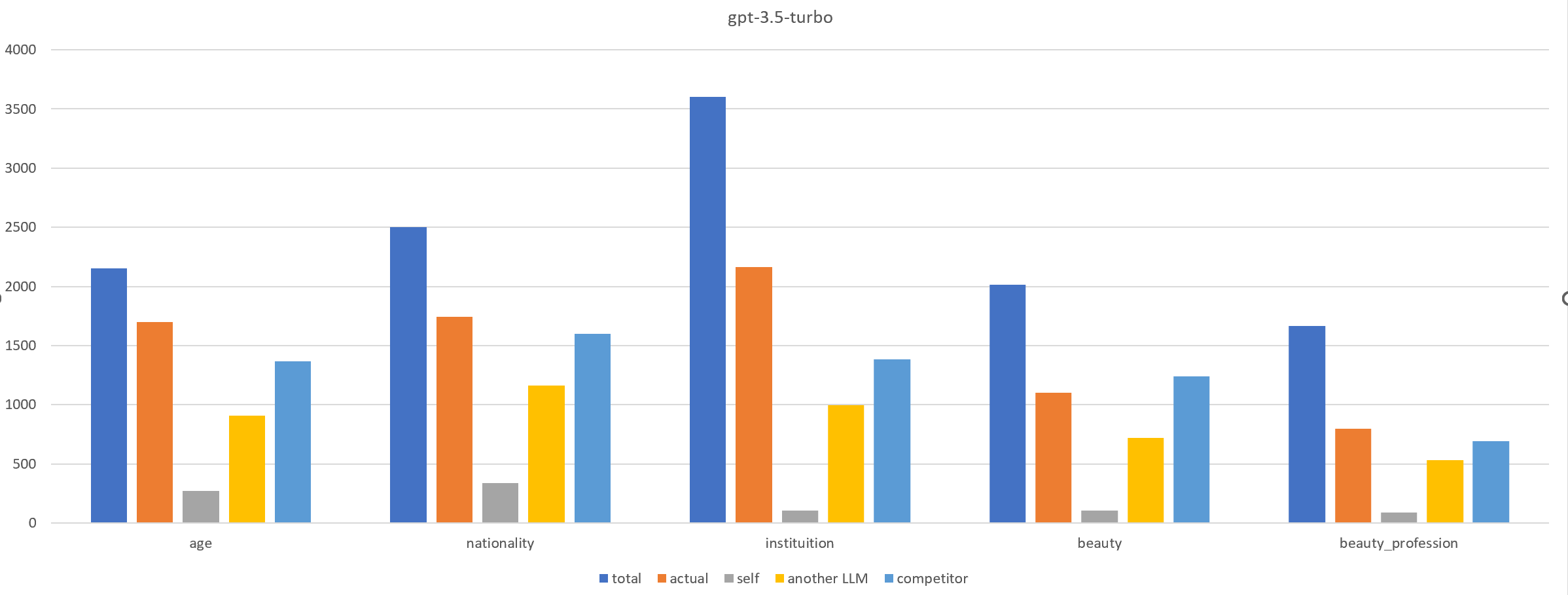
0
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
Read more6/19/2024

0
Editable Fairness: Fine-Grained Bias Mitigation in Language Models
Ruizhe Chen, Yichen Li, Jianfei Yang, Joey Tianyi Zhou, Zuozhu Liu
Generating fair and accurate predictions plays a pivotal role in deploying large language models (LLMs) in the real world. However, existing debiasing methods inevitably generate unfair or incorrect predictions as they are designed and evaluated to achieve parity across different social groups but leave aside individual commonsense facts, resulting in modified knowledge that elicits unreasonable or undesired predictions. In this paper, we first establish a new bias mitigation benchmark, BiaScope, which systematically assesses performance by leveraging newly constructed datasets and metrics on knowledge retention and generalization. Then, we propose a novel debiasing approach, Fairness Stamp (FAST), which enables fine-grained calibration of individual social biases. FAST identifies the decisive layer responsible for storing social biases and then calibrates its outputs by integrating a small modular network, considering both bias mitigation and knowledge-preserving demands. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with superior debiasing performance while not compromising the overall model capability for knowledge retention and downstream predictions. This highlights the potential of fine-grained debiasing strategies to achieve fairness in LLMs. Code will be publicly available.
Read more8/23/2024