Editable Fairness: Fine-Grained Bias Mitigation in Language Models

0

Sign in to get full access
Overview
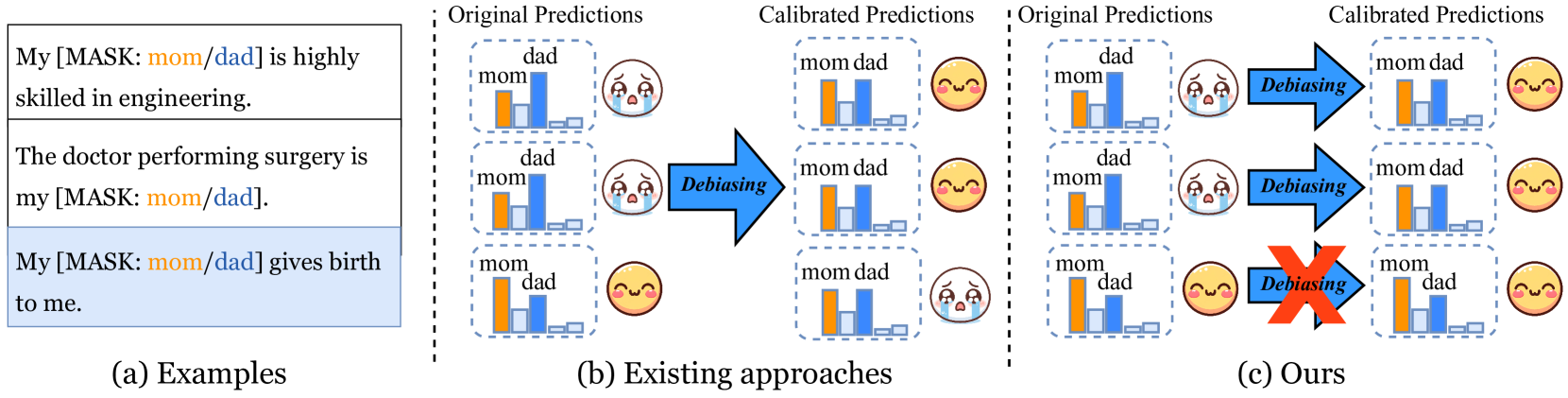
- The paper presents a method for fine-grained bias mitigation in language models.
- It introduces "Editable Fairness", a framework that allows users to interactively edit and refine the fairness of language model outputs.
- The key idea is to give users control over the fairness criteria they want to optimize for, enabling more customized and contextual bias mitigation.
Plain English Explanation
The paper proposes a way to make language models more fair and unbiased. Typically, these models can pick up on and amplify biases present in their training data. The researchers developed a system called "Editable Fairness" that lets users fine-tune the model to reduce specific biases that matter to them.
Instead of a one-size-fits-all approach to bias mitigation, Editable Fairness allows users to customize the fairness criteria based on their needs and preferences. For example, a user could instruct the model to be less biased against a certain gender or race when generating text. This gives people more control over the fairness of the model's outputs in a flexible, contextual way.
The goal is to make language models more useful and trustworthy by giving users the ability to interactively "edit" the model's biases. This could be especially helpful in applications like content moderation, job recommendation systems, or language assistants, where minimizing harmful biases is crucial.
Technical Explanation
The core of the Editable Fairness framework is a set of fine-grained fairness constraints that users can specify. These constraints define the fairness criteria the model should optimize for, such as reducing gender or racial biases in the generated text.
The researchers introduce a novel model architecture that incorporates these user-defined fairness constraints directly into the language model's training process. This allows the model to learn to generate text that satisfies the specified fairness criteria, while still maintaining high performance on the primary task.
Experiments on several benchmark datasets show that Editable Fairness can effectively mitigate a range of biases in the model's outputs, with only a small impact on the model's overall performance. The paper also demonstrates the flexibility of the approach, allowing users to prioritize different fairness objectives depending on their needs.
Critical Analysis
The Editable Fairness framework represents an important step towards making language models more controllable and transparent with respect to fairness. By giving users the ability to directly specify the fairness criteria they care about, it addresses a key limitation of previous bias mitigation techniques that relied on more generic, one-size-fits-all approaches.
However, the paper acknowledges that the proposed method may not fully eliminate all biases, and there may be challenges in scaling the approach to extremely large language models. Additionally, the framework still requires users to have a good understanding of the relevant fairness concepts and how to define appropriate constraints.
Further research could explore ways to make the fairness specification process more intuitive and accessible for non-expert users. Investigating the long-term sustainability of the Editable Fairness approach, as well as its generalization to other AI systems beyond language models, could also be valuable areas for future work.
Conclusion
The Editable Fairness framework represents an important advance in the field of bias mitigation for language models. By empowering users to customize the fairness criteria according to their needs, it moves towards a more contextual and interactive approach to addressing biases in AI systems.
If successfully adopted, this technology could help improve the trustworthiness and fairness of language models in a wide range of real-world applications, from content moderation to personalized recommendations. As AI systems become increasingly influential in our lives, tools like Editable Fairness will be crucial for ensuring these technologies are aligned with our values and serve the needs of diverse communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Editable Fairness: Fine-Grained Bias Mitigation in Language Models
Ruizhe Chen, Yichen Li, Jianfei Yang, Joey Tianyi Zhou, Zuozhu Liu
Generating fair and accurate predictions plays a pivotal role in deploying large language models (LLMs) in the real world. However, existing debiasing methods inevitably generate unfair or incorrect predictions as they are designed and evaluated to achieve parity across different social groups but leave aside individual commonsense facts, resulting in modified knowledge that elicits unreasonable or undesired predictions. In this paper, we first establish a new bias mitigation benchmark, BiaScope, which systematically assesses performance by leveraging newly constructed datasets and metrics on knowledge retention and generalization. Then, we propose a novel debiasing approach, Fairness Stamp (FAST), which enables fine-grained calibration of individual social biases. FAST identifies the decisive layer responsible for storing social biases and then calibrates its outputs by integrating a small modular network, considering both bias mitigation and knowledge-preserving demands. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with superior debiasing performance while not compromising the overall model capability for knowledge retention and downstream predictions. This highlights the potential of fine-grained debiasing strategies to achieve fairness in LLMs. Code will be publicly available.
Read more8/23/2024
0
Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
Ruizhe Chen, Yichen Li, Zikai Xiao, Zuozhu Liu
Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.
Read more7/2/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
💬
0
LIDAO: Towards Limited Interventions for Debiasing (Large) Language Models
Tianci Liu, Haoyu Wang, Shiyang Wang, Yu Cheng, Jing Gao
Large language models (LLMs) have achieved impressive performance on various natural language generation tasks. Nonetheless, they suffer from generating negative and harmful contents that are biased against certain demographic groups (e.g., female), raising severe fairness concerns. As remedies, prior works intervened the generation by removing attitude or demographic information, inevitably degrading the generation quality and resulting in notable textit{fairness-fluency} trade-offs. However, it is still under-explored to what extent the fluency textit{has to} be affected in order to achieve a desired level of fairness. In this work, we conduct the first formal study from an information-theoretic perspective. We show that previous approaches are excessive for debiasing and propose LIDAO, a general framework to debias a (L)LM at a better fluency provably. We further robustify LIDAO in adversarial scenarios, where a carefully-crafted prompt may stimulate LLMs exhibiting instruction-following abilities to generate texts with fairness issue appears only when the prompt is also taken into account. Experiments on three LMs ranging from 0.7B to 7B parameters demonstrate the superiority of our method.
Read more6/4/2024