A lightweight YOLOv5-FFM model for occlusion pedestrian detection

0
Sign in to get full access
Overview
- This paper proposes a lightweight YOLOv5-based model for detecting occluded pedestrians.
- The model, called YOLOv5-FFM, uses a feature fusion module to enhance detection performance on occluded pedestrians.
- Experiments show that YOLOv5-FFM achieves competitive accuracy on pedestrian detection benchmarks while being more efficient than other state-of-the-art models.
Plain English Explanation
The paper describes a new object detection model called YOLOv5-FFM that is designed to detect pedestrians, even when they are partially occluded or hidden from view.
The key idea is to use a feature fusion module that combines information from different layers of the neural network to improve the model's ability to recognize occluded pedestrians. This helps the model "see through" partial obstructions and identify people who might otherwise be missed.
Compared to other state-of-the-art pedestrian detection models, YOLOv5-FFM maintains high accuracy while being more efficient and lightweight, meaning it can run faster and on less powerful hardware. This makes it potentially useful for real-world applications like autonomous vehicles or surveillance systems where detecting pedestrians accurately and quickly is critical.
Technical Explanation
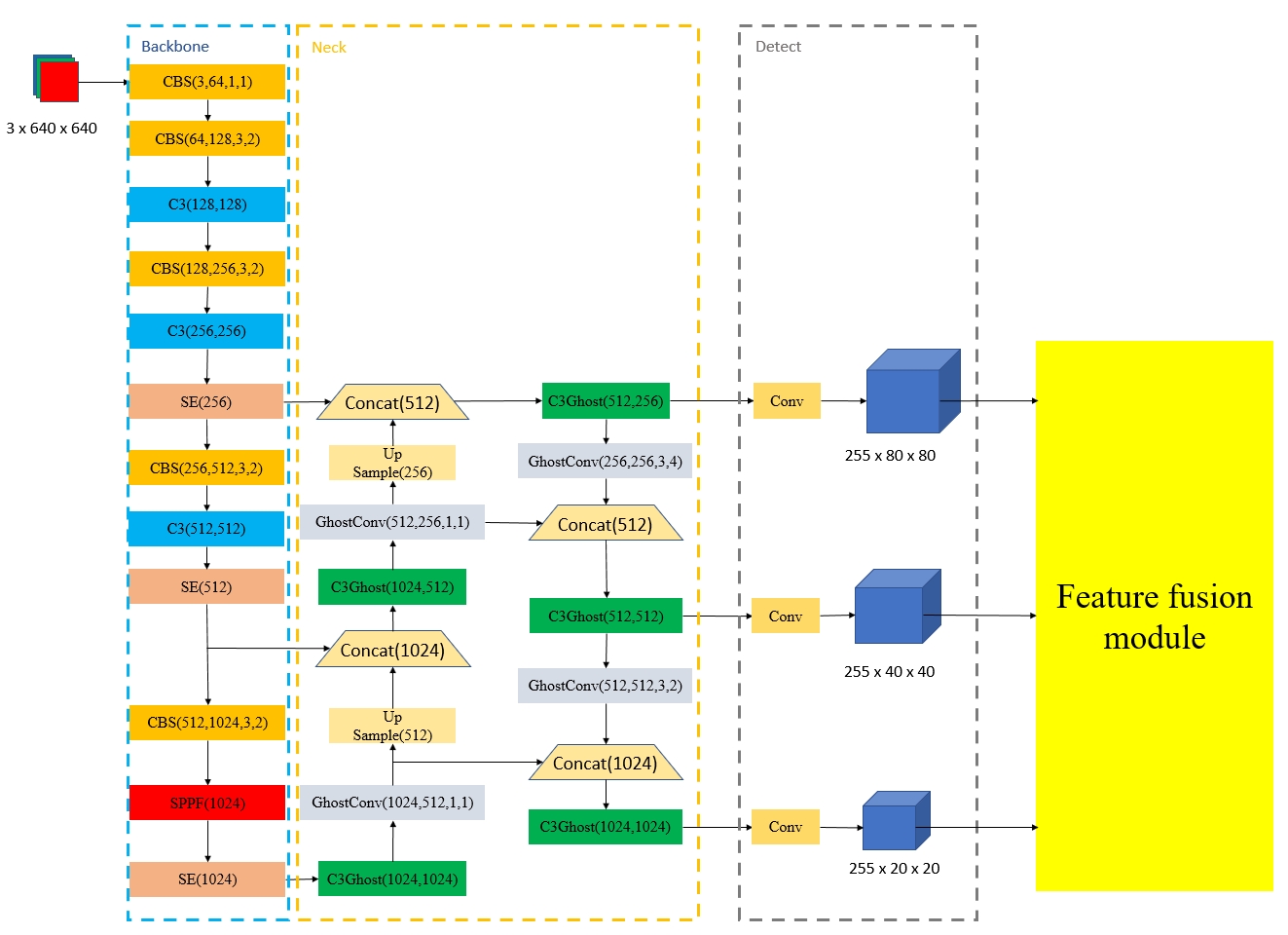
The authors build their model on top of the popular YOLOv5 object detection framework. To enhance the model's ability to detect occluded pedestrians, they introduce a feature fusion module (FFM) that combines features from different layers of the YOLOv5 network.
The FFM takes feature maps from multiple YOLOv5 layers and fuses them through a series of convolutional and pooling operations. This allows the model to aggregate low-level, fine-grained features (useful for detecting small or partially occluded objects) with higher-level, semantic features (useful for robust object classification).
The authors evaluate their YOLOv5-FFM model on standard pedestrian detection benchmarks like CityPersons and CrowdHuman. They show that YOLOv5-FFM achieves competitive accuracy compared to larger and more complex state-of-the-art models, while being more efficient in terms of inference speed and model size.
Critical Analysis
The paper provides a novel and practical solution for improving pedestrian detection, especially in the presence of occlusions. The authors' use of a feature fusion module is a well-established technique in computer vision, and applying it to enhance a YOLOv5 model is a sensible and impactful contribution.
That said, the paper could be strengthened by providing more details on the specific architectural choices and hyperparameter tuning of the FFM. It would also be useful to see an ablation study that isolates the impact of the FFM component versus other factors.
Additionally, while the authors demonstrate strong performance on standard benchmarks, it would be valuable to test the model in more real-world, cluttered environments to fully understand its capabilities and limitations for practical applications.
Conclusion
This paper presents a lightweight YOLOv5-based model, YOLOv5-FFM, that achieves competitive performance on pedestrian detection tasks, particularly when dealing with occluded pedestrians. The key innovation is the feature fusion module, which helps the model better recognize partially obscured people.
The efficiency and accuracy of YOLOv5-FFM make it a promising candidate for deployment in real-world applications like autonomous vehicles and surveillance systems, where rapid and reliable pedestrian detection is crucial for safety and situational awareness. Further research to refine the model and test it in diverse real-world scenarios could unlock even greater practical benefits.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A lightweight YOLOv5-FFM model for occlusion pedestrian detection
Xiangjie Luo, Bo Shao, Zhihao Cai, Yingxun Wang
The development of autonomous driving technology must be inseparable from pedestrian detection. Because of the fast speed of the vehicle, the accuracy and real-time performance of the pedestrian detection algorithm are very important. YOLO, as an efficient and simple one-stage target detection method, is often used for pedestrian detection in various environments. However, this series of detectors face some challenges, such as excessive computation and undesirable detection rate when facing occluded pedestrians. In this paper, we propose an improved lightweight YOLOv5 model to deal with these problems. This model can achieve better pedestrian detection accuracy with fewer floating-point operations (FLOPs), especially for occluded targets. In order to achieve the above goals, we made improvements based on the YOLOv5 model framework and introduced Ghost module and SE block. Furthermore, we designed a local feature fusion module (FFM) to deal with occlusion in pedestrian detection. To verify the validity of our method, two datasets, Citypersons and CUHK Occlusion, were selected for the experiment. The experimental results show that, compared with the original yolov5s model, the average precision (AP) of our method is significantly improved, while the number of parameters is reduced by 27.9% and FLOPs are reduced by 19.0%.
Read more8/14/2024
🔎
0
MODIPHY: Multimodal Obscured Detection for IoT using PHantom Convolution-Enabled Faster YOLO
Shubhabrata Mukherjee, Cory Beard, Zhu Li
Low-light conditions and occluded scenarios impede object detection in real-world Internet of Things (IoT) applications like autonomous vehicles and security systems. While advanced machine learning models strive for accuracy, their computational demands clash with the limitations of resource-constrained devices, hampering real-time performance. In our current research, we tackle this challenge, by introducing ``YOLO Phantom, one of the smallest YOLO models ever conceived. YOLO Phantom utilizes the novel Phantom Convolution block, achieving comparable accuracy to the latest YOLOv8n model while simultaneously reducing both parameters and model size by 43%, resulting in a significant 19% reduction in Giga Floating-Point Operations (GFLOPs). YOLO Phantom leverages transfer learning on our multimodal RGB-infrared dataset to address low-light and occlusion issues, equipping it with robust vision under adverse conditions. Its real-world efficacy is demonstrated on an IoT platform with advanced low-light and RGB cameras, seamlessly connecting to an AWS-based notification endpoint for efficient real-time object detection. Benchmarks reveal a substantial boost of 17% and 14% in frames per second (FPS) for thermal and RGB detection, respectively, compared to the baseline YOLOv8n model. For community contribution, both the code and the multimodal dataset are available on GitHub.
Read more6/26/2024

0
Real-Time Detection and Analysis of Vehicles and Pedestrians using Deep Learning
Md Nahid Sadik, Tahmim Hossain, Faisal Sayeed
Computer vision, particularly vehicle and pedestrian identification is critical to the evolution of autonomous driving, artificial intelligence, and video surveillance. Current traffic monitoring systems confront major difficulty in recognizing small objects and pedestrians effectively in real-time, posing a serious risk to public safety and contributing to traffic inefficiency. Recognizing these difficulties, our project focuses on the creation and validation of an advanced deep-learning framework capable of processing complex visual input for precise, real-time recognition of cars and people in a variety of environmental situations. On a dataset representing complicated urban settings, we trained and evaluated different versions of the YOLOv8 and RT-DETR models. The YOLOv8 Large version proved to be the most effective, especially in pedestrian recognition, with great precision and robustness. The results, which include Mean Average Precision and recall rates, demonstrate the model's ability to dramatically improve traffic monitoring and safety. This study makes an important addition to real-time, reliable detection in computer vision, establishing new benchmarks for traffic management systems.
Read more4/15/2024

0
SOD-YOLOv8 -- Enhancing YOLOv8 for Small Object Detection in Traffic Scenes
Boshra Khalili, Andrew W. Smyth
Object detection as part of computer vision can be crucial for traffic management, emergency response, autonomous vehicles, and smart cities. Despite significant advances in object detection, detecting small objects in images captured by distant cameras remains challenging due to their size, distance from the camera, varied shapes, and cluttered backgrounds. To address these challenges, we propose Small Object Detection YOLOv8 (SOD-YOLOv8), a novel model specifically designed for scenarios involving numerous small objects. Inspired by Efficient Generalized Feature Pyramid Networks (GFPN), we enhance multi-path fusion within YOLOv8 to integrate features across different levels, preserving details from shallower layers and improving small object detection accuracy. Also, A fourth detection layer is added to leverage high-resolution spatial information effectively. The Efficient Multi-Scale Attention Module (EMA) in the C2f-EMA module enhances feature extraction by redistributing weights and prioritizing relevant features. We introduce Powerful-IoU (PIoU) as a replacement for CIoU, focusing on moderate-quality anchor boxes and adding a penalty based on differences between predicted and ground truth bounding box corners. This approach simplifies calculations, speeds up convergence, and enhances detection accuracy. SOD-YOLOv8 significantly improves small object detection, surpassing widely used models in various metrics, without substantially increasing computational cost or latency compared to YOLOv8s. Specifically, it increases recall from 40.1% to 43.9%, precision from 51.2% to 53.9%, $text{mAP}_{0.5}$ from 40.6% to 45.1%, and $text{mAP}_{0.5:0.95}$ from 24% to 26.6%. In dynamic real-world traffic scenes, SOD-YOLOv8 demonstrated notable improvements in diverse conditions, proving its reliability and effectiveness in detecting small objects even in challenging environments.
Read more8/12/2024