MODIPHY: Multimodal Obscured Detection for IoT using PHantom Convolution-Enabled Faster YOLO

0
🔎
Sign in to get full access
Overview
- Tackles the challenge of object detection in low-light and occluded real-world IoT applications
- Introduces "YOLO Phantom," a compact YOLO model that achieves comparable accuracy to the latest YOLOv8n while reducing parameters and model size by 43% and GFLOPs by 19%
- Leverages transfer learning on a multimodal RGB-infrared dataset to address low-light and occlusion issues
- Demonstrates real-world efficacy on an IoT platform with advanced low-light and RGB cameras, connecting to an AWS-based notification endpoint
Plain English Explanation
Object detection, the ability to identify and locate objects in images or videos, is a critical capability for many real-world applications like self-driving cars and security systems. However, these applications often face challenges in low-light conditions and when objects are partially obscured or blocked from view, known as occlusion.
To address these challenges, researchers have developed a new object detection model called "YOLO Phantom." YOLO Phantom is one of the smallest versions of the popular YOLO (You Only Look Once) object detection models, but it still maintains comparable accuracy to the latest YOLOv8n model.
The key innovation in YOLO Phantom is the use of a novel "Phantom Convolution" block, which allows the model to be significantly smaller and more efficient, reducing the overall model size by 43% and the number of calculations (GFLOPs) by 19%. This makes YOLO Phantom well-suited for running on resource-constrained devices like those found in many IoT (Internet of Things) applications.
To further enhance its performance in challenging real-world conditions, the researchers trained YOLO Phantom using a multimodal dataset that combines regular RGB (red, green, blue) camera images with infrared images. This transfer learning approach helps the model learn to detect objects accurately even in low-light settings or when they are partially obscured.
The researchers tested YOLO Phantom on an IoT platform with advanced low-light and RGB cameras, and found that it was able to achieve a substantial boost in frames per second (FPS) compared to the baseline YOLOv8n model - 17% faster for thermal (infrared) detection and 14% faster for RGB detection. This demonstrates the real-world effectiveness of YOLO Phantom for applications that require fast, reliable object detection in challenging environments.
Technical Explanation
The paper introduces "YOLO Phantom," a compact YOLO-based object detection model that aims to address the limitations of existing models in resource-constrained IoT applications. YOLO Phantom utilizes a novel "Phantom Convolution" block, which helps reduce the model's parameter count and overall size by 43% compared to YOLOv8n, while maintaining comparable accuracy.
The researchers also leveraged transfer learning on a multimodal RGB-infrared dataset to enhance YOLO Phantom's performance in low-light and occluded scenarios. This dataset, which combines regular RGB camera images with infrared images, helps the model learn robust visual features that are effective under adverse conditions.
In their experiments, the researchers deployed YOLO Phantom on an IoT platform with advanced low-light and RGB cameras, and integrated it with an AWS-based notification endpoint for real-time object detection. Benchmarks showed that YOLO Phantom achieved a 17% boost in frames per second (FPS) for thermal (infrared) detection and a 14% boost for RGB detection, compared to the baseline YOLOv8n model.
The researchers made the code and multimodal dataset available on GitHub, contributing to the broader research community.
Critical Analysis
The paper presents a promising approach to addressing the challenges of object detection in low-light and occluded scenarios for IoT applications. The introduction of the Phantom Convolution block and the use of a multimodal dataset are innovative strategies that help improve the model's efficiency and robustness.
However, the paper does not provide a detailed analysis of the Phantom Convolution block's architecture or the specific design choices that led to the significant reduction in parameters and GFLOPs. Additionally, the researchers could have explored the tradeoffs between the model's size, accuracy, and inference speed, as well as the potential limitations of the multimodal dataset in terms of its diversity and coverage of real-world scenarios.
Furthermore, the paper does not discuss the impact of the model's reduced computational requirements on the power consumption and thermal management of the target IoT devices. This information would be valuable for understanding the practical implications of YOLO Phantom in real-world deployments.
Overall, the research presented in this paper is a step forward in addressing the challenges of object detection in low-light and occluded conditions for IoT applications. However, further investigation and experimentation could shed more light on the model's limitations and potential areas for improvement.
Conclusion
The "YOLO Phantom" model introduced in this paper represents a significant advancement in the field of object detection for resource-constrained IoT applications. By leveraging a novel Phantom Convolution block and multimodal transfer learning, the researchers have developed a compact and efficient model that can maintain high accuracy while dramatically improving performance in low-light and occluded scenarios.
The real-world testing on an IoT platform with advanced cameras and the integration with an AWS-based notification system demonstrate the practical applicability of YOLO Phantom. The substantial boost in frames per second compared to the baseline YOLOv8n model highlights the potential of this approach to enable more reliable and responsive object detection in a wide range of IoT applications, from autonomous vehicles to security systems.
By open-sourcing the code and dataset, the researchers have also made a valuable contribution to the broader research community, enabling further exploration and development in this important area of computer vision and edge computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
MODIPHY: Multimodal Obscured Detection for IoT using PHantom Convolution-Enabled Faster YOLO
Shubhabrata Mukherjee, Cory Beard, Zhu Li
Low-light conditions and occluded scenarios impede object detection in real-world Internet of Things (IoT) applications like autonomous vehicles and security systems. While advanced machine learning models strive for accuracy, their computational demands clash with the limitations of resource-constrained devices, hampering real-time performance. In our current research, we tackle this challenge, by introducing ``YOLO Phantom, one of the smallest YOLO models ever conceived. YOLO Phantom utilizes the novel Phantom Convolution block, achieving comparable accuracy to the latest YOLOv8n model while simultaneously reducing both parameters and model size by 43%, resulting in a significant 19% reduction in Giga Floating-Point Operations (GFLOPs). YOLO Phantom leverages transfer learning on our multimodal RGB-infrared dataset to address low-light and occlusion issues, equipping it with robust vision under adverse conditions. Its real-world efficacy is demonstrated on an IoT platform with advanced low-light and RGB cameras, seamlessly connecting to an AWS-based notification endpoint for efficient real-time object detection. Benchmarks reveal a substantial boost of 17% and 14% in frames per second (FPS) for thermal and RGB detection, respectively, compared to the baseline YOLOv8n model. For community contribution, both the code and the multimodal dataset are available on GitHub.
Read more6/26/2024
0
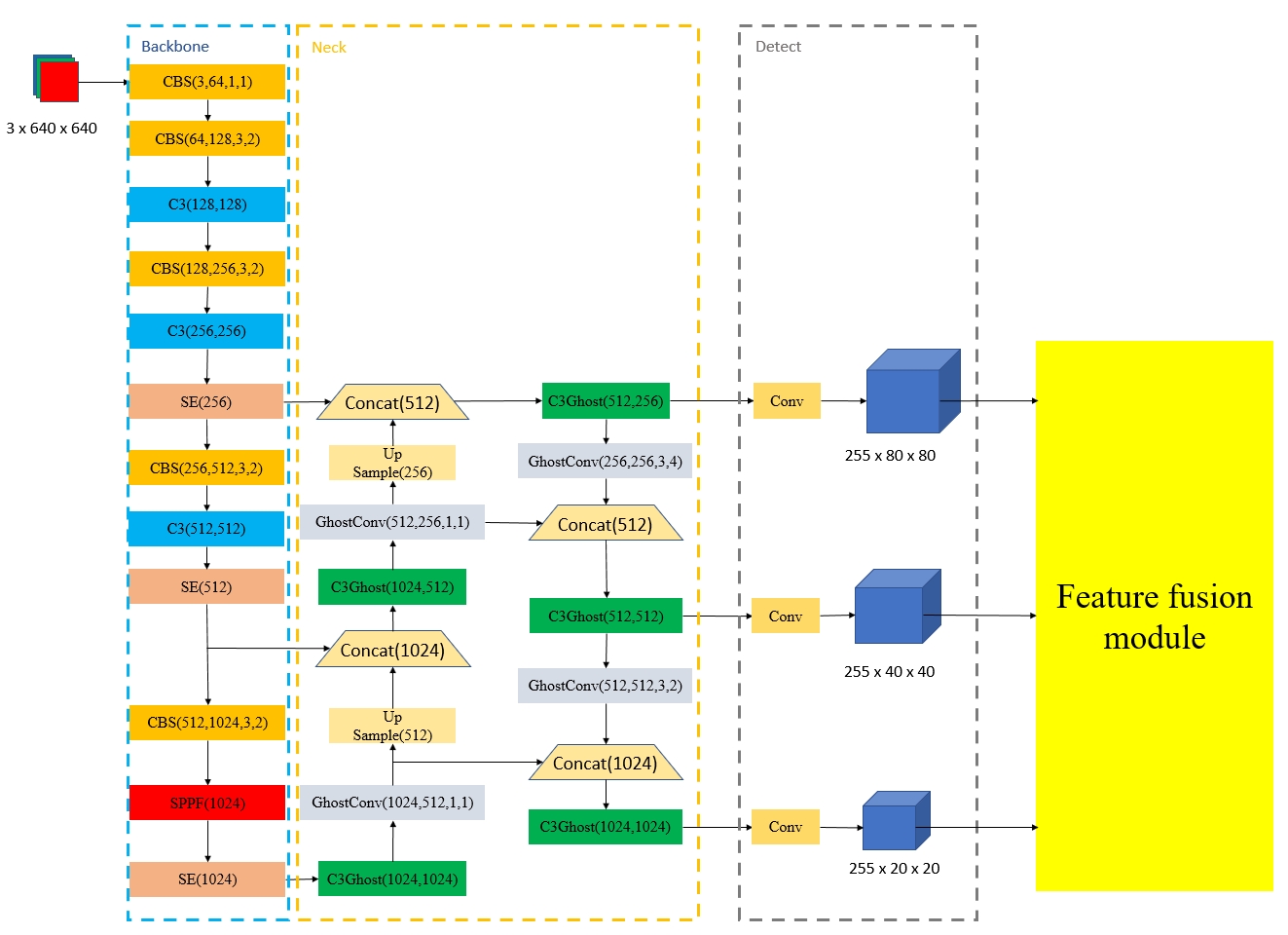
A lightweight YOLOv5-FFM model for occlusion pedestrian detection
Xiangjie Luo, Bo Shao, Zhihao Cai, Yingxun Wang
The development of autonomous driving technology must be inseparable from pedestrian detection. Because of the fast speed of the vehicle, the accuracy and real-time performance of the pedestrian detection algorithm are very important. YOLO, as an efficient and simple one-stage target detection method, is often used for pedestrian detection in various environments. However, this series of detectors face some challenges, such as excessive computation and undesirable detection rate when facing occluded pedestrians. In this paper, we propose an improved lightweight YOLOv5 model to deal with these problems. This model can achieve better pedestrian detection accuracy with fewer floating-point operations (FLOPs), especially for occluded targets. In order to achieve the above goals, we made improvements based on the YOLOv5 model framework and introduced Ghost module and SE block. Furthermore, we designed a local feature fusion module (FFM) to deal with occlusion in pedestrian detection. To verify the validity of our method, two datasets, Citypersons and CUHK Occlusion, were selected for the experiment. The experimental results show that, compared with the original yolov5s model, the average precision (AP) of our method is significantly improved, while the number of parameters is reduced by 27.9% and FLOPs are reduced by 19.0%.
Read more8/14/2024

0
PowerYOLO: Mixed Precision Model for Hardware Efficient Object Detection with Event Data
Dominika Przewlocka-Rus, Tomasz Kryjak, Marek Gorgon
The performance of object detection systems in automotive solutions must be as high as possible, with minimal response time and, due to the often battery-powered operation, low energy consumption. When designing such solutions, we therefore face challenges typical for embedded vision systems: the problem of fitting algorithms of high memory and computational complexity into small low-power devices. In this paper we propose PowerYOLO - a mixed precision solution, which targets three essential elements of such application. First, we propose a system based on a Dynamic Vision Sensor (DVS), a novel sensor, that offers low power requirements and operates well in conditions with variable illumination. It is these features that may make event cameras a preferential choice over frame cameras in some applications. Second, to ensure high accuracy and low memory and computational complexity, we propose to use 4-bit width Powers-of-Two (PoT) quantisation for convolution weights of the YOLO detector, with all other parameters quantised linearly. Finally, we embrace from PoT scheme and replace multiplication with bit-shifting to increase the efficiency of hardware acceleration of such solution, with a special convolution-batch normalisation fusion scheme. The use of specific sensor with PoT quantisation and special batch normalisation fusion leads to a unique system with almost 8x reduction in memory complexity and vast computational simplifications, with relation to a standard approach. This efficient system achieves high accuracy of mAP 0.301 on the GEN1 DVS dataset, marking the new state-of-the-art for such compressed model.
Read more7/12/2024
0
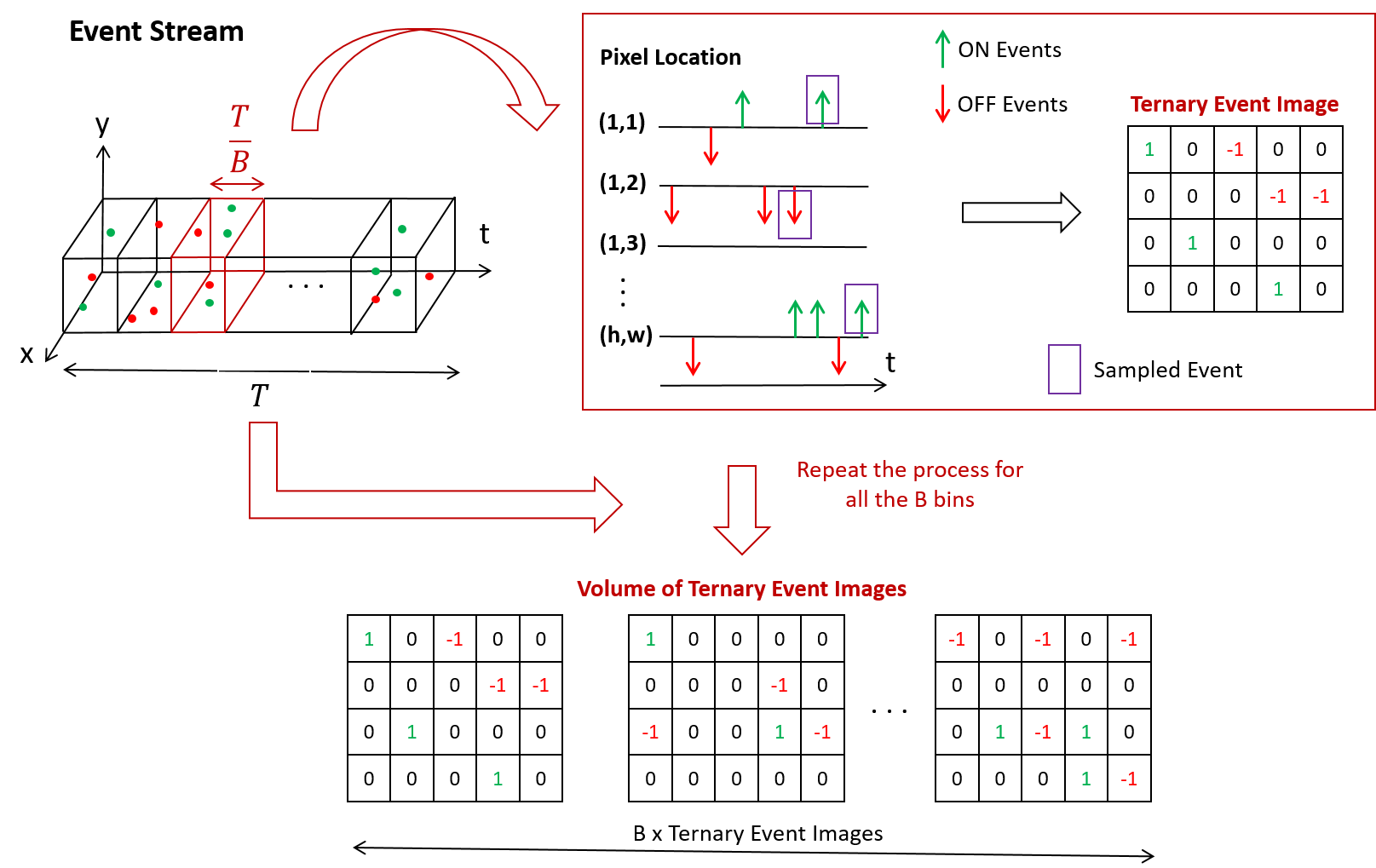
A Recurrent YOLOv8-based framework for Event-Based Object Detection
Diego A. Silva, Kamilya Smagulova, Ahmed Elsheikh, Mohammed E. Fouda, Ahmed M. Eltawil
Object detection is crucial in various cutting-edge applications, such as autonomous vehicles and advanced robotics systems, primarily relying on data from conventional frame-based RGB sensors. However, these sensors often struggle with issues like motion blur and poor performance in challenging lighting conditions. In response to these challenges, event-based cameras have emerged as an innovative paradigm. These cameras, mimicking the human eye, demonstrate superior performance in environments with fast motion and extreme lighting conditions while consuming less power. This study introduces ReYOLOv8, an advanced object detection framework that enhances a leading frame-based detection system with spatiotemporal modeling capabilities. We implemented a low-latency, memory-efficient method for encoding event data to boost the system's performance. We also developed a novel data augmentation technique tailored to leverage the unique attributes of event data, thus improving detection accuracy. Our models outperformed all comparable approaches in the GEN1 dataset, focusing on automotive applications, achieving mean Average Precision (mAP) improvements of 5%, 2.8%, and 2.5% across nano, small, and medium scales, respectively.These enhancements were achieved while reducing the number of trainable parameters by an average of 4.43% and maintaining real-time processing speeds between 9.2ms and 15.5ms. On the PEDRo dataset, which targets robotics applications, our models showed mAP improvements ranging from 9% to 18%, with 14.5x and 3.8x smaller models and an average speed enhancement of 1.67x.
Read more8/13/2024