On Limitation of Transformer for Learning HMMs
2406.04089
0
0
Abstract
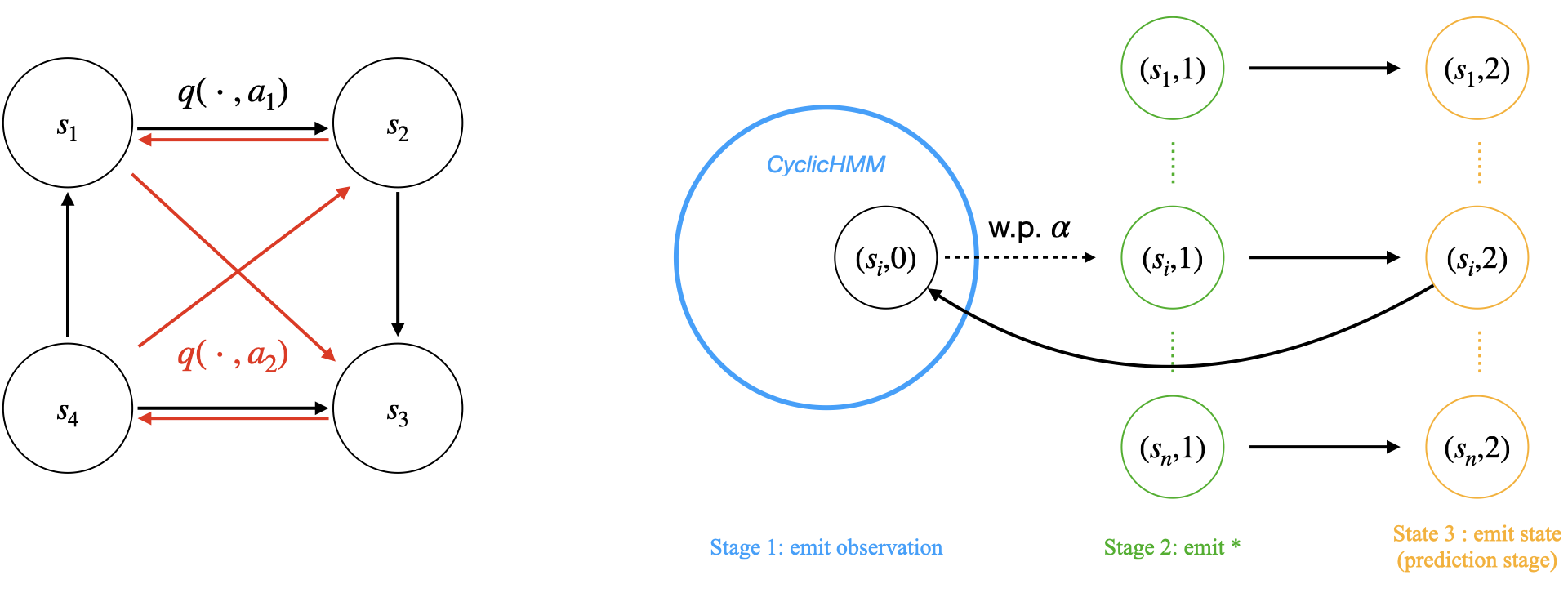
Despite the remarkable success of Transformer-based architectures in various sequential modeling tasks, such as natural language processing, computer vision, and robotics, their ability to learn basic sequential models, like Hidden Markov Models (HMMs), is still unclear. This paper investigates the performance of Transformers in learning HMMs and their variants through extensive experimentation and compares them to Recurrent Neural Networks (RNNs). We show that Transformers consistently underperform RNNs in both training speed and testing accuracy across all tested HMM models. There are even challenging HMM instances where Transformers struggle to learn, while RNNs can successfully do so. Our experiments further reveal the relation between the depth of Transformers and the longest sequence length it can effectively learn, based on the types and the complexity of HMMs. To address the limitation of transformers in modeling HMMs, we demonstrate that a variant of the Chain-of-Thought (CoT), called $textit{block CoT}$ in the training phase, can help transformers to reduce the evaluation error and to learn longer sequences at a cost of increasing the training time. Finally, we complement our empirical findings by theoretical results proving the expressiveness of transformers in approximating HMMs with logarithmic depth.
Create account to get full access
Overview
- This paper examines the limitations of Transformer models in learning Hidden Markov Models (HMMs), a widely used class of probabilistic models.
- The researchers found that Transformer models struggle to learn HMMs, particularly when the state transition probabilities in the HMM are non-uniform.
- The paper provides insights into the inductive biases and architectural limitations of Transformer models that make them less suitable for learning certain types of sequential dynamics.
Plain English Explanation
In this paper, the researchers looked at how well Transformer models, a type of machine learning model that has become very popular in recent years, can learn to understand a specific kind of mathematical model called a Hidden Markov Model (HMM). HMMs are used to represent sequences of events where the underlying state of the system is hidden or unknown, but can be inferred from the observed sequence.
The researchers found that Transformer models have a hard time learning HMMs, especially when the probability of transitioning between different states in the HMM is not uniform. This suggests that Transformers may not be well-suited for modeling certain types of sequential dynamics and patterns that are captured by HMMs.
The paper provides insights into the inherent limitations and biases of Transformer models that make them struggle with this task. These findings are important for understanding the strengths and weaknesses of Transformer models, and could help guide the development of new machine learning architectures that are better equipped to handle a wider range of sequential modeling problems.
Technical Explanation
The paper explores the limitations of Transformer models in learning Hidden Markov Models (HMMs), a widely used class of probabilistic models for sequential data. The researchers conducted experiments to assess the performance of Transformer models in learning HMMs with varying state transition probability distributions.
Their results show that Transformer models struggle to learn HMMs, particularly when the state transition probabilities are non-uniform. This is in contrast to Recurrent Neural Network (RNN) models, which have been shown to be more effective at learning HMMs link to "RNNs are not Transformers yet: Key Bottleneck".
The authors hypothesize that the architectural differences between Transformers and RNNs, such as the lack of a recurrent state in Transformers, contribute to this limitation. They suggest that the inductive biases and architectural choices of Transformer models may make them less suitable for learning certain types of sequential dynamics link to "Limits of Deep Learning for Sequence Modeling Through the Lens".
The paper also discusses the challenges of interpreting the internal representations of Transformer models, which may further hinder their ability to learn HMMs link to "Does Transformer Interpretability Transfer to RNNs?". Additionally, the authors explore the potential of using Transformer architectures to solve partially observable Markov decision processes (POMDPs), which are closely related to HMMs link to "Rethinking Transformers: Solving POMDPs".
Critical Analysis
The paper provides valuable insights into the limitations of Transformer models in learning certain types of sequential dynamics, specifically HMMs with non-uniform state transition probabilities. The researchers acknowledge that their findings are specific to the HMM task and may not generalize to all sequential modeling problems.
It would be interesting to see further research exploring the underlying reasons for Transformers' struggles with HMMs, potentially drawing on insights from the literature on the inductive biases and architectural properties of Transformer models link to "Chain of Thought Empowers Transformers to Solve Inherently". Additionally, investigating the performance of hybrid models that combine Transformer and RNN components could shed light on how to address the limitations identified in this paper.
While the paper's findings are limited to the specific HMM task, they highlight the importance of understanding the strengths and weaknesses of different machine learning architectures and their suitability for various types of sequential modeling problems.
Conclusion
This paper sheds light on the limitations of Transformer models in learning Hidden Markov Models, a widely used class of probabilistic models for sequential data. The researchers found that Transformer models struggle to learn HMMs, particularly when the state transition probabilities are non-uniform, in contrast to the relatively stronger performance of Recurrent Neural Networks.
These findings contribute to our understanding of the inductive biases and architectural properties of Transformer models, which may make them less suitable for certain types of sequential modeling tasks. The insights from this paper could inform the development of new machine learning architectures that are better equipped to handle a wider range of sequential dynamics and patterns, with potential applications in areas such as natural language processing, speech recognition, and time series analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
Kaiyue Wen, Xingyu Dang, Kaifeng Lyu
0
0
This paper investigates the gap in representation powers of Recurrent Neural Networks (RNNs) and Transformers in the context of solving algorithmic problems. We focus on understanding whether RNNs, known for their memory efficiency in handling long sequences, can match the performance of Transformers, particularly when enhanced with Chain-of-Thought (CoT) prompting. Our theoretical analysis reveals that CoT improves RNNs but is insufficient to close the gap with Transformers. A key bottleneck lies in the inability of RNNs to perfectly retrieve information from the context, even with CoT: for several tasks that explicitly or implicitly require this capability, such as associative recall and determining if a graph is a tree, we prove that RNNs are not expressive enough to solve the tasks while Transformers can solve them with ease. Conversely, we prove that adopting techniques to enhance the in-context retrieval capability of RNNs, including Retrieval-Augmented Generation (RAG) and adding a single Transformer layer, can elevate RNNs to be capable of solving all polynomial-time solvable problems with CoT, hence closing the representation gap with Transformers.
5/13/2024
🤿
Limits of Deep Learning: Sequence Modeling through the Lens of Complexity Theory
Nikola Zubi'c, Federico Sold'a, Aurelio Sulser, Davide Scaramuzza
0
0
Deep learning models have achieved significant success across various applications but continue to struggle with tasks requiring complex reasoning over sequences, such as function composition and compositional tasks. Despite advancements, models like Structured State Space Models (SSMs) and Transformers underperform in deep compositionality tasks due to inherent architectural and training limitations. Maintaining accuracy over multiple reasoning steps remains a primary challenge, as current models often rely on shortcuts rather than genuine multi-step reasoning, leading to performance degradation as task complexity increases. Existing research highlights these shortcomings but lacks comprehensive theoretical and empirical analysis for SSMs. Our contributions address this gap by providing a theoretical framework based on complexity theory to explain SSMs' limitations. Moreover, we present extensive empirical evidence demonstrating how these limitations impair function composition and algorithmic task performance. Our experiments reveal significant performance drops as task complexity increases, even with Chain-of-Thought (CoT) prompting. Models frequently resort to shortcuts, leading to errors in multi-step reasoning. This underscores the need for innovative solutions beyond current deep learning paradigms to achieve reliable multi-step reasoning and compositional task-solving in practical applications.
5/28/2024
Does Transformer Interpretability Transfer to RNNs?
Gonc{c}alo Paulo, Thomas Marshall, Nora Belrose
0
0
Recent advances in recurrent neural network architectures, such as Mamba and RWKV, have enabled RNNs to match or exceed the performance of equal-size transformers in terms of language modeling perplexity and downstream evaluations, suggesting that future systems may be built on completely new architectures. In this paper, we examine if selected interpretability methods originally designed for transformer language models will transfer to these up-and-coming recurrent architectures. Specifically, we focus on steering model outputs via contrastive activation addition, on eliciting latent predictions via the tuned lens, and eliciting latent knowledge from models fine-tuned to produce false outputs under certain conditions. Our results show that most of these techniques are effective when applied to RNNs, and we show that it is possible to improve some of them by taking advantage of RNNs' compressed state.
4/10/2024

Rethinking Transformers in Solving POMDPs
Chenhao Lu, Ruizhe Shi, Yuyao Liu, Kaizhe Hu, Simon S. Du, Huazhe Xu
0
0
Sequential decision-making algorithms such as reinforcement learning (RL) in real-world scenarios inevitably face environments with partial observability. This paper scrutinizes the effectiveness of a popular architecture, namely Transformers, in Partially Observable Markov Decision Processes (POMDPs) and reveals its theoretical limitations. We establish that regular languages, which Transformers struggle to model, are reducible to POMDPs. This poses a significant challenge for Transformers in learning POMDP-specific inductive biases, due to their lack of inherent recurrence found in other models like RNNs. This paper casts doubt on the prevalent belief in Transformers as sequence models for RL and proposes to introduce a point-wise recurrent structure. The Deep Linear Recurrent Unit (LRU) emerges as a well-suited alternative for Partially Observable RL, with empirical results highlighting the sub-optimal performance of the Transformer and considerable strength of LRU.
5/31/2024