Does Transformer Interpretability Transfer to RNNs?
2404.05971
3
0
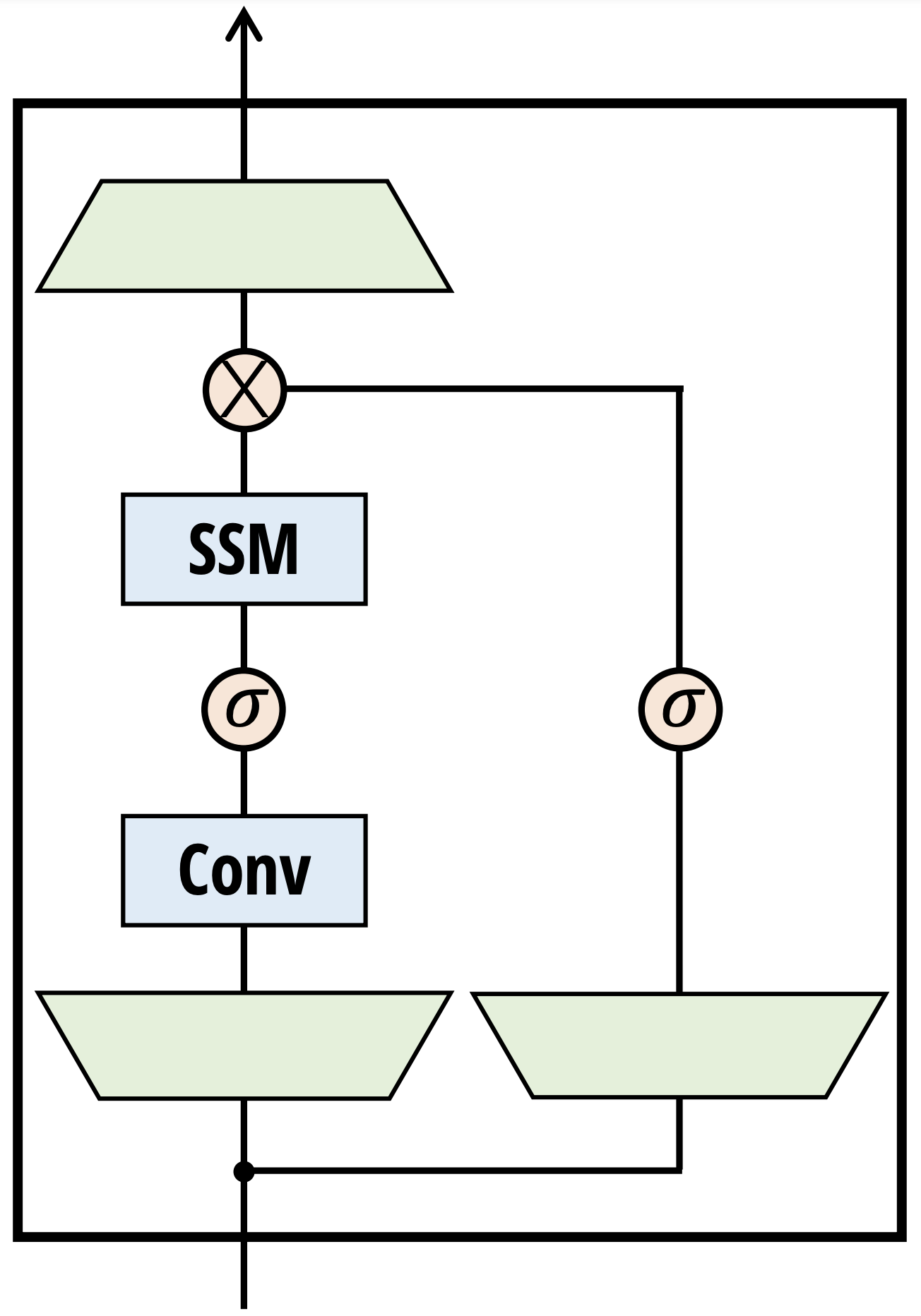
Abstract
Recent advances in recurrent neural network architectures, such as Mamba and RWKV, have enabled RNNs to match or exceed the performance of equal-size transformers in terms of language modeling perplexity and downstream evaluations, suggesting that future systems may be built on completely new architectures. In this paper, we examine if selected interpretability methods originally designed for transformer language models will transfer to these up-and-coming recurrent architectures. Specifically, we focus on steering model outputs via contrastive activation addition, on eliciting latent predictions via the tuned lens, and eliciting latent knowledge from models fine-tuned to produce false outputs under certain conditions. Our results show that most of these techniques are effective when applied to RNNs, and we show that it is possible to improve some of them by taking advantage of RNNs' compressed state.
Create account to get full access
Overview
- Explores the transferability of interpretability techniques from Transformer models to Recurrent Neural Network (RNN) models
- Focuses on the popular Mamba architecture, a type of RNN model
- Evaluates whether the insights gained from interpreting Transformer models can be applied to understand the inner workings of Mamba models
Plain English Explanation
This research paper investigates whether the techniques used to interpret and understand Transformer models, a type of deep learning architecture, can be effectively applied to Recurrent Neural Network (RNN) models, another common deep learning approach. The researchers specifically focus on the Mamba architecture, a specific type of RNN model.
Transformer models have become increasingly popular in recent years due to their strong performance on a variety of language-related tasks. Researchers have also developed techniques to better understand how these models work under the hood, shedding light on the inner workings and decision-making processes. The main question this paper explores is whether the insights gained from interpreting Transformer models can be transferred to interpret RNN models like Mamba, which have a different underlying architecture.
By understanding the similarities and differences in how these two model types operate, researchers can gain a more comprehensive understanding of deep learning for language tasks and potentially apply interpretability techniques more broadly across different model architectures.
Technical Explanation
The paper examines the transferability of interpretability techniques from Transformer models to the Mamba architecture, a type of Recurrent Neural Network (RNN) model. The authors investigate whether the interpretability insights gained from studying Transformer models can be effectively applied to understand the inner workings of Mamba models.
The researchers first provide an overview of the Mamba architecture, which is a specific type of RNN model designed for language tasks. They then review the interpretability techniques that have been developed for Transformer models, such as attention visualization and layer-wise relevance propagation.
The core of the paper focuses on experiments that apply these interpretability techniques to Mamba models, exploring whether the insights gained transfer across the two model architectures. The authors analyze the similarities and differences in how Transformers and Mamba models process and represent linguistic information, shedding light on the strengths and limitations of each approach.
Critical Analysis
The paper acknowledges that while Transformer models have become widely adopted, RNN models like Mamba still offer unique capabilities and continue to be an active area of research. By exploring the transferability of interpretability techniques, the authors aim to provide a more comprehensive understanding of deep learning for language tasks.
One potential limitation of the study is that it focuses solely on the Mamba architecture, which may not be representative of all RNN models. Additionally, the paper does not delve into the potential reasons why certain interpretability techniques may or may not transfer effectively between Transformer and Mamba models. Further research could explore a wider range of RNN architectures and investigate the underlying factors that influence the transferability of interpretability methods.
Overall, this paper offers a valuable contribution by bridging the gap between the understanding of Transformer and RNN models, and encourages readers to think critically about the strengths, limitations, and nuances of different deep learning approaches for language-related tasks.
Conclusion
This research paper investigates the transferability of interpretability techniques from Transformer models to the Mamba architecture, a type of Recurrent Neural Network (RNN) model. The authors explore whether the insights gained from interpreting Transformer models can be effectively applied to understand the inner workings of Mamba models, which have a different underlying architecture.
By evaluating the similarities and differences in how these two model types process and represent linguistic information, the researchers aim to provide a more comprehensive understanding of deep learning for language tasks. The findings of this study can help researchers and practitioners make more informed decisions when choosing and interpreting deep learning models for various language-related applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Revenge of the Fallen? Recurrent Models Match Transformers at Predicting Human Language Comprehension Metrics
James A. Michaelov, Catherine Arnett, Benjamin K. Bergen
0
0
Transformers have supplanted Recurrent Neural Networks as the dominant architecture for both natural language processing tasks and, despite criticisms of cognitive implausibility, for modelling the effect of predictability on online human language comprehension. However, two recently developed recurrent neural network architectures, RWKV and Mamba, appear to perform natural language tasks comparably to or better than transformers of equivalent scale. In this paper, we show that contemporary recurrent models are now also able to match - and in some cases, exceed - performance of comparably sized transformers at modeling online human language comprehension. This suggests that transformer language models are not uniquely suited to this task, and opens up new directions for debates about the extent to which architectural features of language models make them better or worse models of human language comprehension.
5/1/2024

Separations in the Representational Capabilities of Transformers and Recurrent Architectures
Satwik Bhattamishra, Michael Hahn, Phil Blunsom, Varun Kanade
0
0
Transformer architectures have been widely adopted in foundation models. Due to their high inference costs, there is renewed interest in exploring the potential of efficient recurrent architectures (RNNs). In this paper, we analyze the differences in the representational capabilities of Transformers and RNNs across several tasks of practical relevance, including index lookup, nearest neighbor, recognizing bounded Dyck languages, and string equality. For the tasks considered, our results show separations based on the size of the model required for different architectures. For example, we show that a one-layer Transformer of logarithmic width can perform index lookup, whereas an RNN requires a hidden state of linear size. Conversely, while constant-size RNNs can recognize bounded Dyck languages, we show that one-layer Transformers require a linear size for this task. Furthermore, we show that two-layer Transformers of logarithmic size can perform decision tasks such as string equality or disjointness, whereas both one-layer Transformers and recurrent models require linear size for these tasks. We also show that a log-size two-layer Transformer can implement the nearest neighbor algorithm in its forward pass; on the other hand recurrent models require linear size. Our constructions are based on the existence of $N$ nearly orthogonal vectors in $O(log N)$ dimensional space and our lower bounds are based on reductions from communication complexity problems. We supplement our theoretical results with experiments that highlight the differences in the performance of these architectures on practical-size sequences.
6/14/2024

Modeling Bilingual Sentence Processing: Evaluating RNN and Transformer Architectures for Cross-Language Structural Priming
Bushi Xiao, Chao Gao, Demi Zhang
0
0
This study evaluates the performance of Recurrent Neural Network (RNN) and Transformer in replicating cross-language structural priming: a key indicator of abstract grammatical representations in human language processing. Focusing on Chinese-English priming, which involves two typologically distinct languages, we examine how these models handle the robust phenomenon of structural priming, where exposure to a particular sentence structure increases the likelihood of selecting a similar structure subsequently. Additionally, we utilize large language models (LLM) to measure the cross-lingual structural priming effect. Our findings indicate that Transformer outperform RNN in generating primed sentence structures, challenging the conventional belief that human sentence processing primarily involves recurrent and immediate processing and suggesting a role for cue-based retrieval mechanisms. Overall, this work contributes to our understanding of how computational models may reflect human cognitive processes in multilingual contexts.
5/16/2024

Transformers meet Neural Algorithmic Reasoners
Wilfried Bounsi, Borja Ibarz, Andrew Dudzik, Jessica B. Hamrick, Larisa Markeeva, Alex Vitvitskyi, Razvan Pascanu, Petar Veliv{c}kovi'c
0
0
Transformers have revolutionized machine learning with their simple yet effective architecture. Pre-training Transformers on massive text datasets from the Internet has led to unmatched generalization for natural language understanding (NLU) tasks. However, such language models remain fragile when tasked with algorithmic forms of reasoning, where computations must be precise and robust. To address this limitation, we propose a novel approach that combines the Transformer's language understanding with the robustness of graph neural network (GNN)-based neural algorithmic reasoners (NARs). Such NARs proved effective as generic solvers for algorithmic tasks, when specified in graph form. To make their embeddings accessible to a Transformer, we propose a hybrid architecture with a two-phase training procedure, allowing the tokens in the language model to cross-attend to the node embeddings from the NAR. We evaluate our resulting TransNAR model on CLRS-Text, the text-based version of the CLRS-30 benchmark, and demonstrate significant gains over Transformer-only models for algorithmic reasoning, both in and out of distribution.
6/14/2024