On the Limitations of Large Language Models (LLMs): False Attribution
2404.04631
0
0

Abstract
In this work, we provide insight into one important limitation of large language models (LLMs), i.e. false attribution, and introduce a new hallucination metric - Simple Hallucination Index (SHI). The task of automatic author attribution for relatively small chunks of text is an important NLP task but can be challenging. We empirically evaluate the power of 3 open SotA LLMs in zero-shot setting (LLaMA-2-13B, Mixtral 8x7B, and Gemma-7B), especially as human annotation can be costly. We collected the top 10 most popular books, according to Project Gutenberg, divided each one into equal chunks of 400 words, and asked each LLM to predict the author. We then randomly sampled 162 chunks for human evaluation from each of the annotated books, based on the error margin of 7% and a confidence level of 95% for the book with the most chunks (Great Expectations by Charles Dickens, having 922 chunks). The average results show that Mixtral 8x7B has the highest prediction accuracy, the lowest SHI, and a Pearson's correlation (r) of 0.737, 0.249, and -0.9996, respectively, followed by LLaMA-2-13B and Gemma-7B. However, Mixtral 8x7B suffers from high hallucinations for 3 books, rising as high as an SHI of 0.87 (in the range 0-1, where 1 is the worst). The strong negative correlation of accuracy and SHI, given by r, demonstrates the fidelity of the new hallucination metric, which is generalizable to other tasks. We publicly release the annotated chunks of data and our codes to aid the reproducibility and evaluation of other models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the limitations of large language models (LLMs) with a focus on the issue of false attribution.
- The researchers examine how LLMs can incorrectly attribute text to specific individuals or sources, leading to potential misinformation and trust issues.
- The paper proposes a methodology to investigate this problem and presents insights from their findings.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, this research suggests that LLMs can sometimes attribute text to the wrong person or source, a problem known as "false attribution."
For example, an LLM might generate a passage and claim it was written by a famous author, when in reality, the LLM itself created the text. This could lead to the spread of misinformation and a breakdown of trust in the technology. The researchers in this paper set out to better understand this issue and explore ways to address it.
Technical Explanation
The researchers used a methodology that involved collecting a dataset of books from various authors. They then used LLMs to generate text that was similar in style to each author's writing. By comparing the generated text to the actual books, the researchers were able to identify instances where the LLM incorrectly attributed the generated text to the wrong author.
The findings from this research provide valuable insights into the limitations of LLMs and the potential risks of false attribution. The researchers suggest that addressing this issue will be crucial as LLMs become more widely adopted and integrated into various applications, such as text summarization and content generation.
Critical Analysis
While the researchers' methodology provides a valuable framework for studying false attribution, the paper acknowledges that the problem is complex and multifaceted. For example, the researchers note that the accuracy of their findings may be influenced by factors such as the quality and diversity of the training data used by the LLMs.
Additionally, the paper does not explore the potential societal implications of false attribution in depth. As LLMs become more prevalent, the spread of misinformation could have serious consequences, particularly in areas like journalism or content moderation. Further research is needed to fully understand and address these broader challenges.
Conclusion
This paper provides a valuable contribution to the ongoing discussion around the limitations of large language models. By highlighting the issue of false attribution, the researchers have shed light on an important challenge that must be addressed as these technologies continue to evolve. While the findings are preliminary, they underscore the need for rigorous testing, transparency, and careful deployment of LLMs to ensure their safe and responsible use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024

Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling
Yida Mu, Peizhen Bai, Kalina Bontcheva, Xingyi Song
0
0
Large language models (LLMs) with their strong zero-shot topic extraction capabilities offer an alternative to probabilistic topic modelling and closed-set topic classification approaches. As zero-shot topic extractors, LLMs are expected to understand human instructions to generate relevant and non-hallucinated topics based on the given documents. However, LLM-based topic modelling approaches often face difficulties in generating topics with adherence to granularity as specified in human instructions, often resulting in many near-duplicate topics. Furthermore, methods for addressing hallucinated topics generated by LLMs have not yet been investigated. In this paper, we focus on addressing the issues of topic granularity and hallucinations for better LLM-based topic modelling. To this end, we introduce a novel approach that leverages Direct Preference Optimisation (DPO) to fine-tune open-source LLMs, such as Mistral-7B. Our approach does not rely on traditional human annotation to rank preferred answers but employs a reconstruction pipeline to modify raw topics generated by LLMs, thus enabling a fast and efficient training and inference framework. Comparative experiments show that our fine-tuning approach not only significantly improves the LLM's capability to produce more coherent, relevant, and precise topics, but also reduces the number of hallucinated topics.
5/2/2024
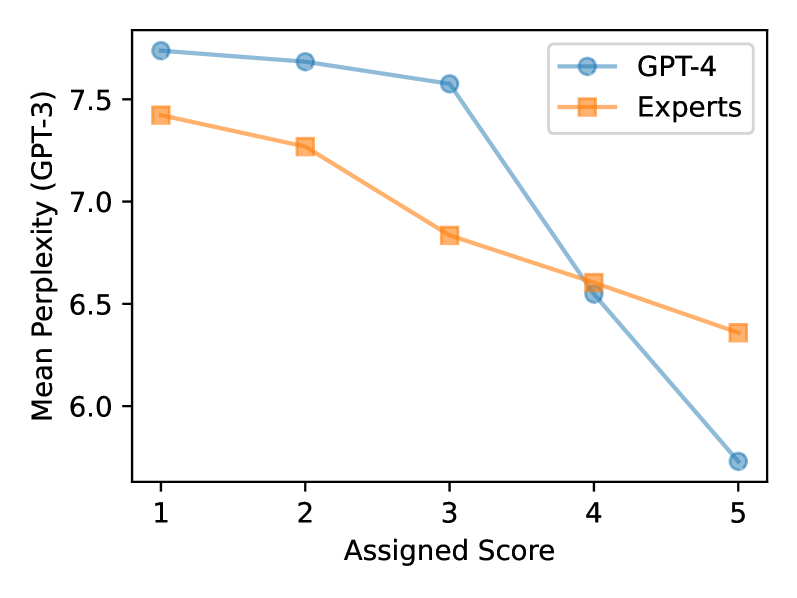
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024