Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling

0

Sign in to get full access
Overview
- This research paper addresses two key issues in using large language models for topic modeling: topic granularity and hallucination.
- Topic granularity refers to the level of detail or abstractness in the topics identified by the model.
- Hallucination occurs when a language model generates plausible-sounding but factually incorrect information.
- The researchers propose a novel approach to improve topic granularity and mitigate hallucination in large language models for topic modeling tasks.
Plain English Explanation
The paper focuses on improving the performance of large language models, which are powerful AI systems trained on vast amounts of text data, when used for a task called "topic modeling." Topic modeling is the process of identifying the main themes or topics present in a collection of documents.
One challenge the researchers address is topic granularity. This refers to how broad or specific the identified topics are. Large language models can sometimes produce topics that are too broad or too narrow, making them less useful. The researchers develop a way to adjust the level of detail in the topics to make them more informative.
Another issue is hallucination, which occurs when a language model generates text that sounds plausible but is actually made up or factually incorrect. Hallucination is a common problem in large vision-language models and can also occur in language-only models like the ones used for topic modeling. The researchers find a way to reduce hallucination in their topic modeling approach.
By addressing these two challenges, the researchers aim to create a more reliable and useful topic modeling system based on large language models. This could have applications in areas like content summarization, question answering, and video understanding, where accurate and interpretable topic modeling is important.
Technical Explanation
The researchers propose a novel approach called "Constrained Topic Modeling" (CTM) to address topic granularity and hallucination in large language models for topic modeling.
CTM works by incorporating topic-level constraints into the language model's training process. These constraints help the model learn more coherent and interpretable topics, with the desired level of granularity. The researchers also introduce a novel hallucination detection and mitigation technique that identifies and removes hallucinated topic words during the training process.
In their experiments, the researchers compare CTM to several baseline topic modeling approaches, including standard Latent Dirichlet Allocation (LDA) and large language model-based methods. They evaluate the models on various topic modeling metrics, as well as human judgments of topic quality and coherence.
The results show that CTM outperforms the baseline methods in terms of topic granularity and coherence, while also significantly reducing hallucination. The researchers also provide insights into the types of hallucinations that can occur in large language models and how their approach effectively mitigates them.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the topic-level constraints used in CTM may not generalize well to all types of text data or domains. The hallucination detection and mitigation techniques, while effective, could potentially remove some valid topic words if not tuned carefully.
Additionally, the researchers only evaluate their approach on a limited set of datasets and topic modeling tasks. Further research is needed to understand how well CTM performs in a wider range of real-world applications, such as mitigating hallucination in large vision-language models or summarization tasks.
Another potential concern is the computational overhead introduced by the additional training steps and constraints in CTM. This could make the approach less scalable or efficient compared to simpler topic modeling methods, especially for very large language models or datasets.
Overall, the researchers present a promising approach to addressing two important challenges in using large language models for topic modeling. However, further research and validation will be necessary to fully understand the strengths, limitations, and practical implications of their work.
Conclusion
This research paper proposes a novel approach called Constrained Topic Modeling (CTM) to improve the performance of large language models for topic modeling tasks. The key contributions are:
- Addressing the issue of topic granularity by incorporating topic-level constraints into the language model training process.
- Mitigating hallucination in the generated topics through a novel detection and removal technique.
- Demonstrating the effectiveness of CTM in producing more coherent and interpretable topics compared to baseline methods.
The researchers' work has the potential to enhance the reliability and usefulness of large language models in a variety of applications that rely on accurate and interpretable topic modeling, such as content summarization, question answering, and video understanding. Further research is needed to explore the generalizability and scalability of the CTM approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling
Yida Mu, Peizhen Bai, Kalina Bontcheva, Xingyi Song
Large language models (LLMs) with their strong zero-shot topic extraction capabilities offer an alternative to probabilistic topic modelling and closed-set topic classification approaches. As zero-shot topic extractors, LLMs are expected to understand human instructions to generate relevant and non-hallucinated topics based on the given documents. However, LLM-based topic modelling approaches often face difficulties in generating topics with adherence to granularity as specified in human instructions, often resulting in many near-duplicate topics. Furthermore, methods for addressing hallucinated topics generated by LLMs have not yet been investigated. In this paper, we focus on addressing the issues of topic granularity and hallucinations for better LLM-based topic modelling. To this end, we introduce a novel approach that leverages Direct Preference Optimisation (DPO) to fine-tune open-source LLMs, such as Mistral-7B. Our approach does not rely on traditional human annotation to rank preferred answers but employs a reconstruction pipeline to modify raw topics generated by LLMs, thus enabling a fast and efficient training and inference framework. Comparative experiments show that our fine-tuning approach not only significantly improves the LLM's capability to produce more coherent, relevant, and precise topics, but also reduces the number of hallucinated topics.
Read more5/2/2024

0
Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
Read more4/4/2024
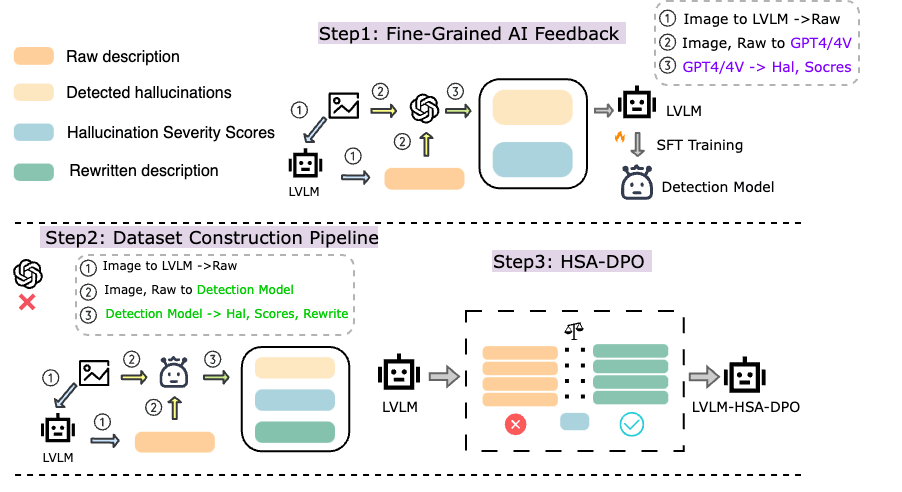
0
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024

0
Fine-grained Hallucination Detection and Editing for Language Models
Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, Hannaneh Hajishirzi
Large language models (LMs) are prone to generate factual errors, which are often called hallucinations. In this paper, we introduce a comprehensive taxonomy of hallucinations and argue that hallucinations manifest in diverse forms, each requiring varying degrees of careful assessments to verify factuality. We propose a novel task of automatic fine-grained hallucination detection and construct a new evaluation benchmark, FavaBench, that includes about one thousand fine-grained human judgments on three LM outputs across various domains. Our analysis reveals that ChatGPT and Llama2-Chat (70B, 7B) exhibit diverse types of hallucinations in the majority of their outputs in information-seeking scenarios. We train FAVA, a retrieval-augmented LM by carefully creating synthetic data to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT and GPT-4 on fine-grained hallucination detection, and edits suggested by FAVA improve the factuality of LM-generated text.
Read more8/14/2024