Linear Cross-Lingual Mapping of Sentence Embeddings
2305.14256
0
0
✨
Abstract
Semantics of a sentence is defined with much less ambiguity than semantics of a single word, and we assume that it should be better preserved by translation to another language. If multilingual sentence embeddings intend to represent sentence semantics, then the similarity between embeddings of any two sentences must be invariant with respect to translation. Based on this suggestion, we consider a simple linear cross-lingual mapping as a possible improvement of the multilingual embeddings. We also consider deviation from orthogonality conditions as a measure of deficiency of the embeddings.
Create account to get full access
Overview
- The paper explores the idea that sentence semantics are less ambiguous than word semantics, and this should be better preserved when translating a sentence to another language.
- The authors suggest using a simple linear cross-lingual mapping as a potential improvement for multilingual sentence embeddings, which aim to represent sentence semantics.
- They also consider deviation from orthogonality conditions as a measure of deficiency in the embeddings.
Plain English Explanation
The meaning of a full sentence is generally clearer and less ambiguous than the meaning of a single word. The authors of this paper believe that this should be better maintained when translating a sentence from one language to another.
If the goal of multilingual sentence embeddings is to capture the underlying meaning of sentences, then the similarity between the embeddings of any two sentences should stay the same regardless of what language they're in. Building on this idea, the researchers propose using a simple linear transformation to improve how well multilingual sentence embeddings align across languages.
They also look at how much the embeddings deviate from being perfectly orthogonal (perpendicular) to each other as a way to measure how well the embeddings are able to represent sentence semantics.
Technical Explanation
The paper posits that the semantics of a sentence are defined with less ambiguity than the semantics of individual words, and this property should be better preserved when translating a sentence to another language.
The authors suggest that if multilingual sentence embeddings are meant to capture sentence semantics, then the similarity between the embeddings of any two sentences must remain constant regardless of the language they're in. Based on this, they propose using a simple linear cross-lingual mapping as a potential improvement to existing multilingual embeddings.
Additionally, the paper considers the deviation from orthogonality conditions as a way to measure the "deficiency" of the embeddings - i.e., how well they are able to represent distinct sentence semantics.
Critical Analysis
The paper presents a straightforward and logical approach to improving multilingual sentence embeddings by focusing on preserving semantic similarity across translations. However, the authors acknowledge that their proposed linear mapping is a simplistic solution, and more complex techniques may be required to fully address the challenges of cross-lingual alignment.
It would be valuable to see the authors explore more sophisticated cross-lingual mapping techniques and evaluate their performance compared to the linear approach. Additionally, the paper does not provide a detailed analysis of the potential limitations or edge cases of their proposed method, which would be helpful for understanding its practical applicability.
Conclusion
This paper suggests that the semantic similarity of sentences should be better preserved when translating between languages, and proposes a simple linear cross-lingual mapping as a potential approach to improving multilingual sentence embeddings. The authors also introduce the idea of using deviation from orthogonality as a way to measure the quality of these embeddings.
While the proposed solution is straightforward, the paper highlights an important consideration for developing high-quality multilingual language models that can accurately represent and align the semantics of sentences across languages. Further research in this area could lead to more robust and versatile language understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
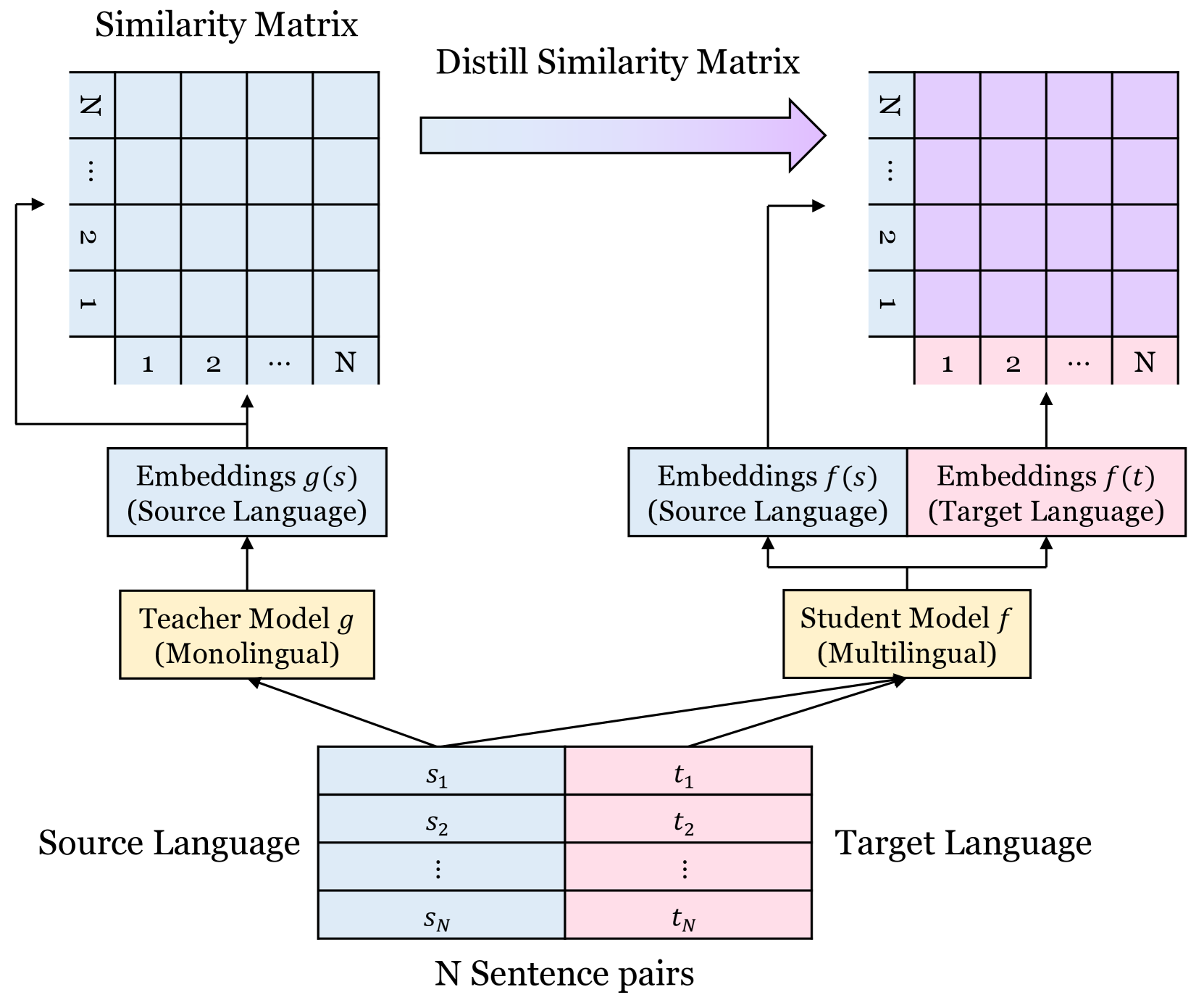
Improving Multi-lingual Alignment Through Soft Contrastive Learning
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
0
0
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
5/29/2024
Cross-lingual paraphrase identification
Inessa Fedorova, Aleksei Musatow
0
0
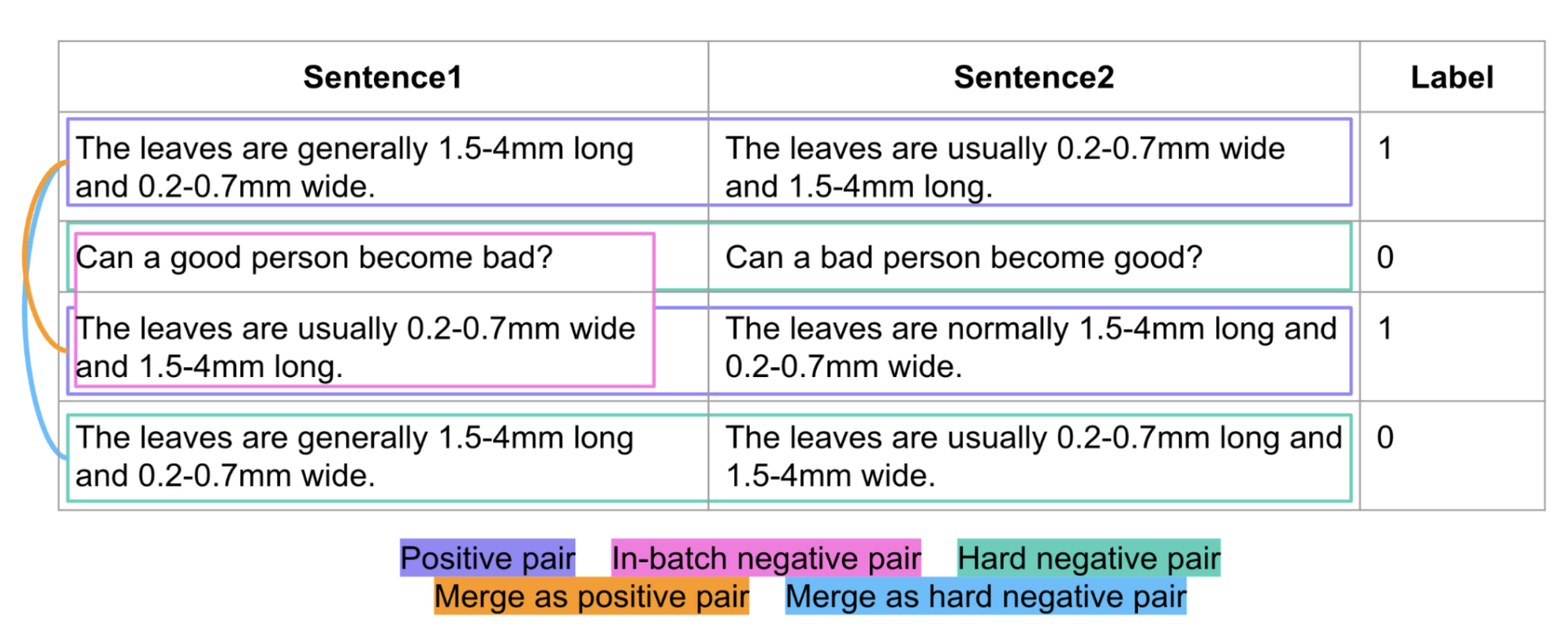
The paraphrase identification task involves measuring semantic similarity between two short sentences. It is a tricky task, and multilingual paraphrase identification is even more challenging. In this work, we train a bi-encoder model in a contrastive manner to detect hard paraphrases across multiple languages. This approach allows us to use model-produced embeddings for various tasks, such as semantic search. We evaluate our model on downstream tasks and also assess embedding space quality. Our performance is comparable to state-of-the-art cross-encoders, with only a minimal relative drop of 7-10% on the chosen dataset, while keeping decent quality of embeddings.
6/24/2024
🌿
Exploring Alignment in Shared Cross-lingual Spaces
Basel Mousi, Nadir Durrani, Fahim Dalvi, Majd Hawasly, Ahmed Abdelali
0
0
Despite their remarkable ability to capture linguistic nuances across diverse languages, questions persist regarding the degree of alignment between languages in multilingual embeddings. Drawing inspiration from research on high-dimensional representations in neural language models, we employ clustering to uncover latent concepts within multilingual models. Our analysis focuses on quantifying the textit{alignment} and textit{overlap} of these concepts across various languages within the latent space. To this end, we introduce two metrics CA{} and CO{} aimed at quantifying these aspects, enabling a deeper exploration of multilingual embeddings. Our study encompasses three multilingual models (texttt{mT5}, texttt{mBERT}, and texttt{XLM-R}) and three downstream tasks (Machine Translation, Named Entity Recognition, and Sentiment Analysis). Key findings from our analysis include: i) deeper layers in the network demonstrate increased cross-lingual textit{alignment} due to the presence of language-agnostic concepts, ii) fine-tuning of the models enhances textit{alignment} within the latent space, and iii) such task-specific calibration helps in explaining the emergence of zero-shot capabilities in the models.footnote{The code is available at url{https://github.com/baselmousi/multilingual-latent-concepts}}
5/24/2024
🤔
Understanding Cross-Lingual Alignment -- A Survey
Katharina Hammerl, Jindv{r}ich Libovick'y, Alexander Fraser
0
0
Cross-lingual alignment, the meaningful similarity of representations across languages in multilingual language models, has been an active field of research in recent years. We survey the literature of techniques to improve cross-lingual alignment, providing a taxonomy of methods and summarising insights from throughout the field. We present different understandings of cross-lingual alignment and their limitations. We provide a qualitative summary of results from a large number of surveyed papers. Finally, we discuss how these insights may be applied not only to encoder models, where this topic has been heavily studied, but also to encoder-decoder or even decoder-only models, and argue that an effective trade-off between language-neutral and language-specific information is key.
6/12/2024