Probing the Emergence of Cross-lingual Alignment during LLM Training
2406.13229
0
0
Abstract
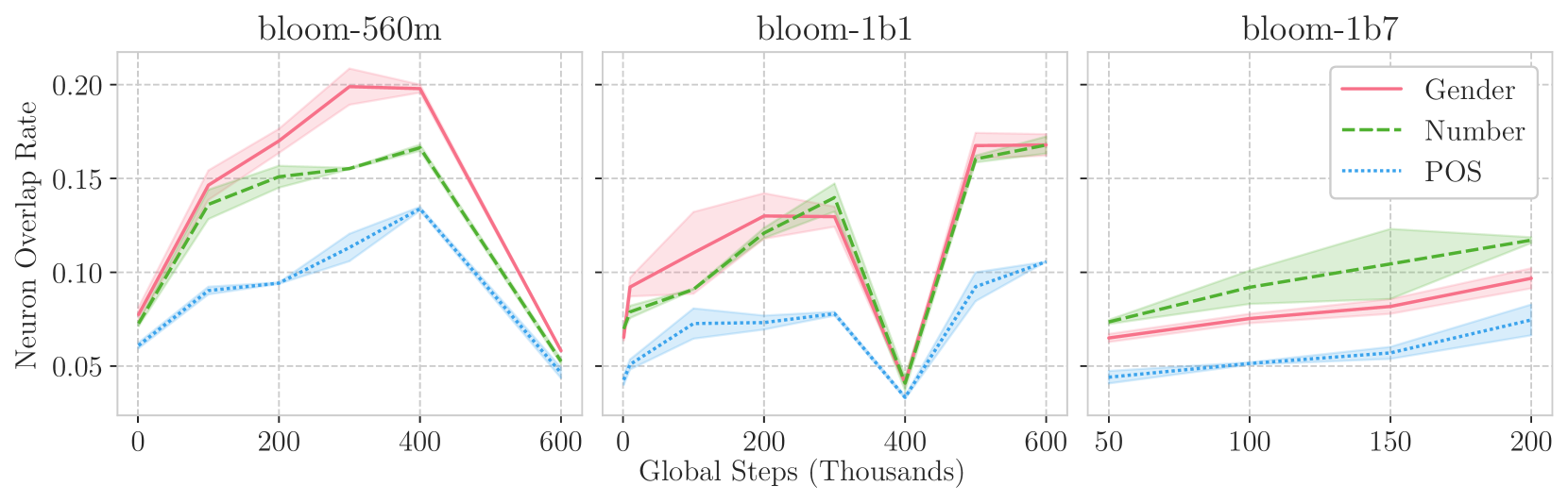
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
Create account to get full access
Overview
- This paper investigates the emergence of cross-lingual alignment during the training of large language models (LLMs).
- The researchers use intrinsic probing techniques to analyze how LLMs develop the ability to align representations across languages as training progresses.
- The findings provide insights into the underlying mechanisms that enable LLMs to learn cross-lingual capabilities.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human language across multiple languages. But how do these models develop the ability to align, or match up, the representations of words and concepts across different languages during the training process?
The researchers in this paper used a technique called "intrinsic probing" to investigate this question. They looked at how the internal representations of the LLM evolved over the course of training, and how these representations became aligned between different languages. This helps us understand the core mechanisms that allow LLMs to become multilingual and transfer knowledge across languages.
The insights from this research could lead to improvements in the way we develop and align cross-lingual representations in LLMs, ultimately leading to more robust and effective multilingual AI systems that can transfer knowledge across languages with greater accuracy.
Technical Explanation
The researchers used a series of intrinsic probes to analyze how the internal representations of LLMs evolve during training to enable cross-lingual alignment. These probes included:
- Cosine Similarity: Measuring the cosine similarity between representations of words/concepts across languages to quantify the degree of cross-lingual alignment.
- Linear Mapping: Learning a linear transformation to map representations between languages and evaluating the quality of the mapping.
- Clustering: Analyzing how well semantically related words from different languages cluster together in the representation space.
The experiments were conducted on several multilingual LLMs, including mBERT, XLM-R, and mT5, trained on large multilingual corpora. The results showed that cross-lingual alignment emerges gradually during training, with representations becoming increasingly aligned as training progresses.
The researchers also found that the degree of alignment varies across different linguistic phenomena, with some aspects like cognates and named entities aligning more easily than others. Additionally, they observed that the representations of lower-resource languages tend to align less well with higher-resource languages, highlighting the challenges of achieving robust cross-lingual transfer.
Critical Analysis
The paper provides valuable insights into the inner workings of LLMs and how they develop cross-lingual capabilities. However, the research is limited to intrinsic probing, and the authors acknowledge that further work is needed to understand the practical implications for downstream tasks and applications.
Additionally, the paper does not address potential biases or limitations that may arise from the multilingual training data or the probing methodologies used. There could be concerns around the representativeness of the evaluated languages or the sensitivity of the probes to certain linguistic phenomena.
Further research could explore the role of specific architectural choices, training strategies, or fine-tuning approaches in enhancing cross-lingual alignment. Exploring alignment in shared cross-lingual spaces and improving context learning in multilingual generative language models could also provide additional insights.
Conclusion
This paper offers a deep dive into the emergence of cross-lingual alignment in large language models, shedding light on the underlying mechanisms that enable LLMs to develop multilingual capabilities. The findings have implications for improving the robustness and cross-lingual transfer of these models, ultimately leading to more effective and versatile multilingual AI systems that can better understand and communicate across languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, Chulin Xie, Chiyuan Zhang
0
0
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
6/26/2024
💬
Improving In-context Learning of Multilingual Generative Language Models with Cross-lingual Alignment
Chong Li, Shaonan Wang, Jiajun Zhang, Chengqing Zong
0
0
Multilingual generative models obtain remarkable cross-lingual in-context learning capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages and learn isolated distributions of multilingual sentence representations, which may hinder knowledge transfer across languages. To bridge this gap, we propose a simple yet effective cross-lingual alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns outputs by following cross-lingual instructions in the target language. Experimental results show that even with less than 0.1 {textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative language models and mitigates the performance gap. Further analyses reveal that it results in a better internal multilingual representation distribution of multilingual models.
6/13/2024

mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Tianze Hua, Tian Yun, Ellie Pavlick
0
0
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of anchor tokens (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
4/22/2024

New!Cross-Lingual Transfer Learning for Speech Translation
Rao Ma, Yassir Fathullah, Mengjie Qian, Siyuan Tang, Mark Gales, Kate Knill
0
0
There has been increasing interest in building multilingual foundation models for NLP and speech research. Zero-shot cross-lingual transfer has been demonstrated on a range of NLP tasks where a model fine-tuned on task-specific data in one language yields performance gains in other languages. Here, we explore whether speech-based models exhibit the same transfer capability. Using Whisper as an example of a multilingual speech foundation model, we examine the utterance representation generated by the speech encoder. Despite some language-sensitive information being preserved in the audio embedding, words from different languages are mapped to a similar semantic space, as evidenced by a high recall rate in a speech-to-speech retrieval task. Leveraging this shared embedding space, zero-shot cross-lingual transfer is demonstrated in speech translation. When the Whisper model is fine-tuned solely on English-to-Chinese translation data, performance improvements are observed for input utterances in other languages. Additionally, experiments on low-resource languages show that Whisper can perform speech translation for utterances from languages unseen during pre-training by utilizing cross-lingual representations.
7/2/2024