Linear Optimal Partial Transport Embedding

0
🗣️
Sign in to get full access
Overview
- Optimal transport (OT) is a powerful mathematical framework with applications in various fields, including machine learning, statistics, and signal processing.
- However, the balanced mass requirement of traditional OT limits its performance in practical problems.
- To address these limitations, researchers have proposed variants of the OT problem, such as unbalanced OT, Optimal partial transport (OPT), and Hellinger Kantorovich (HK).
- In this paper, the authors introduce the Linear Optimal Partial Transport (LOPT) embedding, which extends the (local) linearization technique on OT and HK to the OPT problem.
Plain English Explanation
Optimal transport (OT) is a way of comparing and measuring the similarity between different sets of data, like images or audio files. It's been really useful in fields like machine learning and data analysis. But there are some limitations to how OT is typically used - it requires that the total amount of 'stuff' (like the total pixel values in an image) has to be the same in both datasets being compared.
To get around this limitation, researchers have come up with some variations on the OT problem. These include unbalanced OT, which lets the total amounts be different, Optimal partial transport (OPT), which only compares part of the datasets, and Hellinger Kantorovich (HK), which uses a different way of measuring similarity.
In this paper, the researchers propose a new way of doing OPT called the Linear Optimal Partial Transport (LOPT) embedding. This LOPT approach extends some of the techniques used in OT and HK to make OPT faster and more efficient to compute. The authors show how LOPT can be useful for tasks like interpolating between point cloud data and doing principal component analysis (PCA).
Technical Explanation
The paper introduces the Linear Optimal Partial Transport (LOPT) embedding, which extends the (local) linearization technique used in Optimal Transport (OT) and Hellinger Kantorovich (HK) to the Optimal Partial Transport (OPT) problem.
OPT is a variant of the OT problem that relaxes the balanced mass requirement, allowing for partial comparisons between positive measures (e.g., comparing only part of two datasets). The authors demonstrate that the LOPT embedding allows for faster computation of the OPT distance between pairs of positive measures.
Specifically, the LOPT embedding leverages a local linearization approach to approximate the OPT distance. This approximation can be computed efficiently, enabling the LOPT technique to scale better than existing OPT methods. The authors provide theoretical analysis and guarantees for the LOPT embedding.
In the experimental section, the authors showcase the LOPT embedding in two applications: point-cloud interpolation and principal component analysis (PCA). The results demonstrate the effectiveness of the LOPT approach compared to other OPT methods.
Critical Analysis
The paper provides a valuable contribution by introducing the LOPT embedding, which extends the OT and HK linearization techniques to the OPT problem. This allows for faster computation of OPT distances, which is an important advancement given the limitations of traditional OT.
One potential limitation is that the LOPT embedding relies on local linearization, which may not capture global structure as accurately as some other OPT methods. Additionally, the paper does not explore the performance of LOPT on a wider range of applications beyond the two showcased.
Further research could investigate the robustness of LOPT to different types of data and problem settings, as well as explore ways to enhance the global modeling capabilities of the LOPT approach. [Integrating LOPT with other techniques, such as those proposed in the papers on global-local prompts and OTTER, could also be a fruitful direction for future work.]
Conclusion
This paper presents the Linear Optimal Partial Transport (LOPT) embedding, which extends the (local) linearization techniques used in Optimal Transport (OT) and Hellinger Kantorovich (HK) to the Optimal Partial Transport (OPT) problem. The LOPT embedding allows for faster computation of OPT distances, addressing the limitations of traditional OT.
The authors demonstrate the effectiveness of the LOPT approach in two applications: point-cloud interpolation and principal component analysis (PCA). This research represents an important advancement in the field of optimal transport, with potential implications for a wide range of applications in machine learning, data analysis, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Linear Optimal Partial Transport Embedding
Yikun Bai, Ivan Medri, Rocio Diaz Martin, Rana Muhammad Shahroz Khan, Soheil Kolouri
Optimal transport (OT) has gained popularity due to its various applications in fields such as machine learning, statistics, and signal processing. However, the balanced mass requirement limits its performance in practical problems. To address these limitations, variants of the OT problem, including unbalanced OT, Optimal partial transport (OPT), and Hellinger Kantorovich (HK), have been proposed. In this paper, we propose the Linear optimal partial transport (LOPT) embedding, which extends the (local) linearization technique on OT and HK to the OPT problem. The proposed embedding allows for faster computation of OPT distance between pairs of positive measures. Besides our theoretical contributions, we demonstrate the LOPT embedding technique in point-cloud interpolation and PCA analysis.
Read more4/24/2024
0
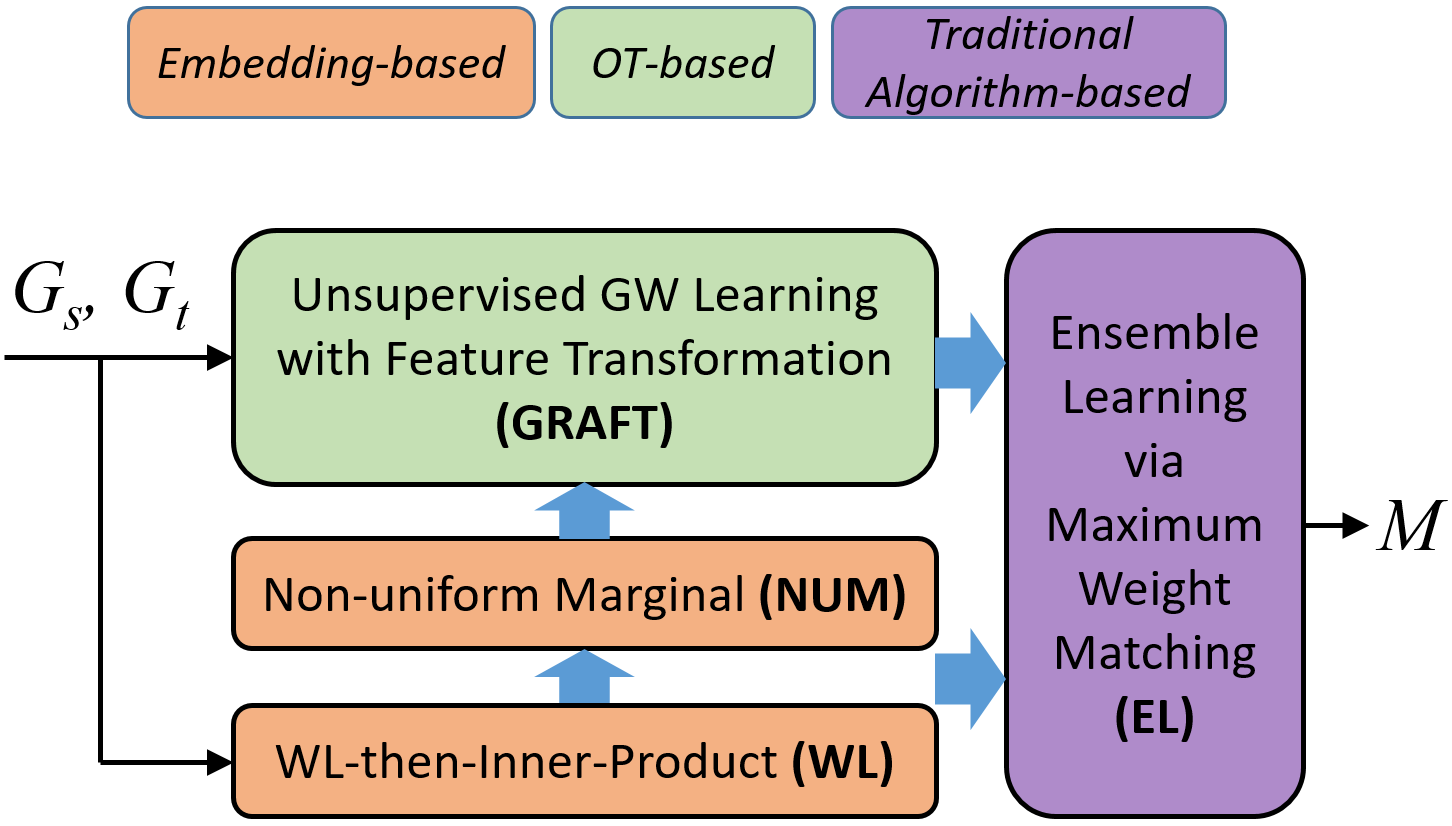
Combining Optimal Transport and Embedding-Based Approaches for More Expressiveness in Unsupervised Graph Alignment
Songyang Chen, Yu Liu, Lei Zou, Zexuan Wang, Youfang Lin, Yuxing Chen, Anqun Pan
Unsupervised graph alignment finds the one-to-one node correspondence between a pair of attributed graphs by only exploiting graph structure and node features. One category of existing works first computes the node representation and then matches nodes with close embeddings, which is intuitive but lacks a clear objective tailored for graph alignment in the unsupervised setting. The other category reduces the problem to optimal transport (OT) via Gromov-Wasserstein (GW) learning with a well-defined objective but leaves a large room for exploring the design of transport cost. We propose a principled approach to combine their advantages motivated by theoretical analysis of model expressiveness. By noticing the limitation of discriminative power in separating matched and unmatched node pairs, we improve the cost design of GW learning with feature transformation, which enables feature interaction across dimensions. Besides, we propose a simple yet effective embedding-based heuristic inspired by the Weisfeiler-Lehman test and add its prior knowledge to OT for more expressiveness when handling non-Euclidean data. Moreover, we are the first to guarantee the one-to-one matching constraint by reducing the problem to maximum weight matching. The algorithm design effectively combines our OT and embedding-based predictions via stacking, an ensemble learning strategy. We propose a model framework named texttt{CombAlign} integrating all the above modules to refine node alignment progressively. Through extensive experiments, we demonstrate significant improvements in alignment accuracy compared to state-of-the-art approaches and validate the effectiveness of the proposed modules.
Read more6/21/2024

0
Progressive Entropic Optimal Transport Solvers
Parnian Kassraie, Aram-Alexandre Pooladian, Michal Klein, James Thornton, Jonathan Niles-Weed, Marco Cuturi
Optimal transport (OT) has profoundly impacted machine learning by providing theoretical and computational tools to realign datasets. In this context, given two large point clouds of sizes $n$ and $m$ in $mathbb{R}^d$, entropic OT (EOT) solvers have emerged as the most reliable tool to either solve the Kantorovich problem and output a $ntimes m$ coupling matrix, or to solve the Monge problem and learn a vector-valued push-forward map. While the robustness of EOT couplings/maps makes them a go-to choice in practical applications, EOT solvers remain difficult to tune because of a small but influential set of hyperparameters, notably the omnipresent entropic regularization strength $varepsilon$. Setting $varepsilon$ can be difficult, as it simultaneously impacts various performance metrics, such as compute speed, statistical performance, generalization, and bias. In this work, we propose a new class of EOT solvers (ProgOT), that can estimate both plans and transport maps. We take advantage of several opportunities to optimize the computation of EOT solutions by dividing mass displacement using a time discretization, borrowing inspiration from dynamic OT formulations, and conquering each of these steps using EOT with properly scheduled parameters. We provide experimental evidence demonstrating that ProgOT is a faster and more robust alternative to standard solvers when computing couplings at large scales, even outperforming neural network-based approaches. We also prove statistical consistency of our approach for estimating optimal transport maps.
Read more9/18/2024

0
Distributional Preference Alignment of LLMs via Optimal Transport
Igor Melnyk, Youssef Mroueh, Brian Belgodere, Mattia Rigotti, Apoorva Nitsure, Mikhail Yurochkin, Kristjan Greenewald, Jiri Navratil, Jerret Ross
Current LLM alignment techniques use pairwise human preferences at a sample level, and as such, they do not imply an alignment on the distributional level. We propose in this paper Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT aligns LLMs on unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. We introduce a convex relaxation of this first-order stochastic dominance and cast it as an optimal transport problem with a smooth and convex cost. Thanks to the one-dimensional nature of the resulting optimal transport problem and the convexity of the cost, it has a closed-form solution via sorting on empirical measures. We fine-tune LLMs with this AOT objective, which enables alignment by penalizing the violation of the stochastic dominance of the reward distribution of the positive samples on the reward distribution of the negative samples. We analyze the sample complexity of AOT by considering the dual of the OT problem and show that it converges at the parametric rate. Empirically, we show on a diverse set of alignment datasets and LLMs that AOT leads to state-of-the-art models in the 7B family of models when evaluated with Open LLM Benchmarks and AlpacaEval.
Read more6/11/2024