Wasserstein Wormhole: Scalable Optimal Transport Distance with Transformers

0
Sign in to get full access
Overview
- This paper proposes a new method called "Wasserstein Wormhole" for efficiently computing the Wasserstein distance between high-dimensional distributions.
- The Wasserstein distance is a widely used metric in machine learning, but computing it can be computationally expensive, especially for large-scale problems.
- The Wasserstein Wormhole method leverages Transformer models to learn a low-dimensional representation of distributions, which enables faster and more scalable Wasserstein distance computation.
Plain English Explanation
The Wasserstein distance is a way of measuring how different two sets of data are from each other. It's a useful metric in machine learning, but it can be slow to calculate, especially when you're working with large, complex datasets.
The researchers behind this paper came up with a new method called the "Wasserstein Wormhole" to make Wasserstein distance calculations faster and more efficient. Their approach uses a type of AI model called a Transformer to learn a low-dimensional (simplified) representation of the datasets you're comparing. Once you have these simplified representations, you can quickly calculate the Wasserstein distance between them.
This is important because being able to efficiently compute Wasserstein distances opens up new possibilities for using this metric in real-world machine learning applications, where speed and scalability are crucial. For example, the Wasserstein distance has been used to compare different types of language models, to test if two datasets come from the same underlying distribution, and to train models in a privacy-preserving way. The Wasserstein Wormhole method could make these types of applications much more practical and widely usable.
Technical Explanation
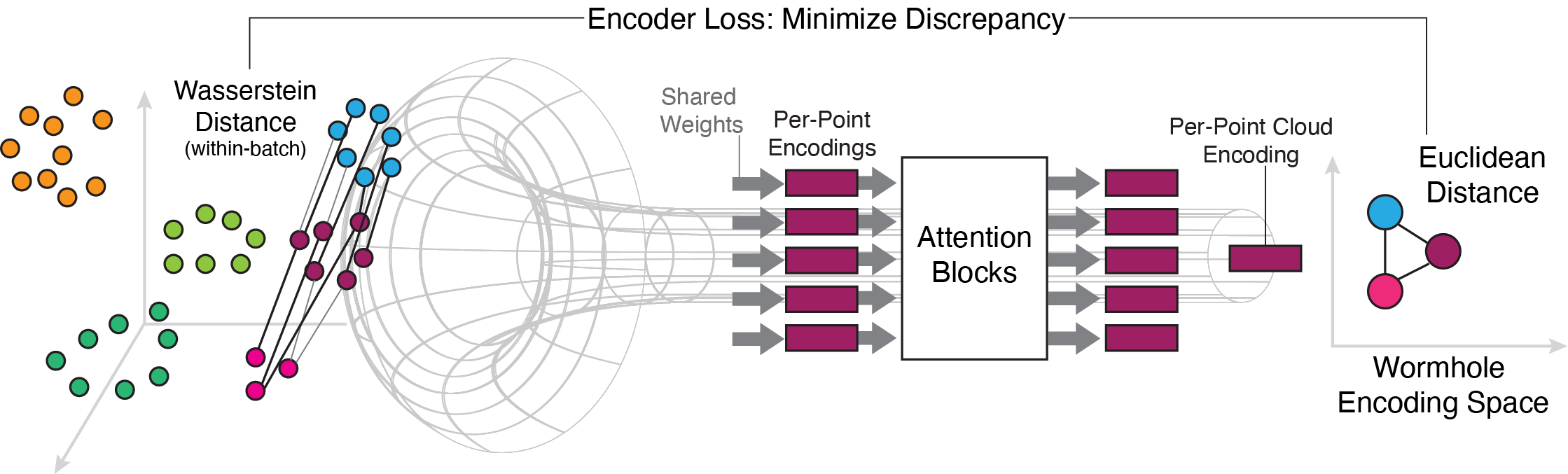
The key idea behind the Wasserstein Wormhole method is to learn a low-dimensional representation of the input distributions using a Transformer-based architecture. Specifically, the authors train a Transformer encoder to map high-dimensional data samples into a low-dimensional latent space. This latent representation can then be used to efficiently compute the Wasserstein distance between the original distributions.
The benefits of this approach are two-fold:
-
Computational Efficiency: By working in the low-dimensional latent space, the Wasserstein distance computation becomes much faster, as it no longer requires solving a computationally expensive optimal transport problem on the original high-dimensional data.
-
Scalability: The Transformer-based encoder can be trained on large-scale datasets, allowing the Wasserstein Wormhole method to scale to real-world, high-dimensional problems that were previously intractable using traditional Wasserstein distance computation methods.
The authors demonstrate the effectiveness of their approach through extensive experiments on synthetic and real-world datasets, showing that the Wasserstein Wormhole method can achieve significant speedups (up to 100x) compared to baseline Wasserstein distance computation methods, while maintaining comparable or even superior performance on various tasks, such as two-sample testing and semantic regularized optimal transport.
Critical Analysis
The Wasserstein Wormhole method proposed in this paper is a promising approach to addressing the computational challenges of Wasserstein distance calculation. However, there are a few potential limitations and areas for further research:
-
Representation Quality: The performance of the Wasserstein Wormhole method ultimately depends on the quality of the latent representations learned by the Transformer encoder. If the encoder fails to capture the essential features of the input distributions, the computed Wasserstein distance may not accurately reflect the true dissimilarity between the distributions.
-
Interpretability: As with many deep learning models, the internal workings of the Transformer encoder used in the Wasserstein Wormhole method may be difficult to interpret. This could make it challenging to understand the specific reasons for the method's success or failure in certain applications.
-
Generalization: The authors primarily evaluate the Wasserstein Wormhole method on synthetic and relatively simple real-world datasets. More research is needed to assess its performance and robustness on more complex, high-dimensional real-world problems, such as those encountered in natural language processing or computer vision.
Despite these potential limitations, the Wasserstein Wormhole method represents a significant step forward in making Wasserstein distance computation more scalable and practical for real-world applications. As the authors note, further research on improving the representation learning and interpretability of the method could lead to even more powerful and versatile tools for working with high-dimensional data distributions.
Conclusion
The Wasserstein Wormhole method proposed in this paper offers a novel and efficient approach to computing the Wasserstein distance between high-dimensional data distributions. By leveraging Transformer models to learn low-dimensional representations of the input data, the method can significantly speed up Wasserstein distance calculations while maintaining comparable or better performance on a variety of tasks.
This advance is important because the Wasserstein distance is a widely used and powerful metric in machine learning, with applications ranging from two-sample testing to privacy-preserving model training. The Wasserstein Wormhole method could help make these applications more practical and accessible, opening up new possibilities for working with complex, high-dimensional data in fields like natural language processing, computer vision, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Wasserstein Wormhole: Scalable Optimal Transport Distance with Transformers
Doron Haviv, Russell Zhang Kunes, Thomas Dougherty, Cassandra Burdziak, Tal Nawy, Anna Gilbert, Dana Pe'er
Optimal transport (OT) and the related Wasserstein metric (W) are powerful and ubiquitous tools for comparing distributions. However, computing pairwise Wasserstein distances rapidly becomes intractable as cohort size grows. An attractive alternative would be to find an embedding space in which pairwise Euclidean distances map to OT distances, akin to standard multidimensional scaling (MDS). We present Wasserstein Wormhole, a transformer-based autoencoder that embeds empirical distributions into a latent space wherein Euclidean distances approximate OT distances. Extending MDS theory, we show that our objective function implies a bound on the error incurred when embedding non-Euclidean distances. Empirically, distances between Wormhole embeddings closely match Wasserstein distances, enabling linear time computation of OT distances. Along with an encoder that maps distributions to embeddings, Wasserstein Wormhole includes a decoder that maps embeddings back to distributions, allowing for operations in the embedding space to generalize to OT spaces, such as Wasserstein barycenter estimation and OT interpolation. By lending scalability and interpretability to OT approaches, Wasserstein Wormhole unlocks new avenues for data analysis in the fields of computational geometry and single-cell biology.
Read more6/5/2024

0
Strongly Isomorphic Neural Optimal Transport Across Incomparable Spaces
Athina Sotiropoulou, David Alvarez-Melis
Optimal Transport (OT) has recently emerged as a powerful framework for learning minimal-displacement maps between distributions. The predominant approach involves a neural parametrization of the Monge formulation of OT, typically assuming the same space for both distributions. However, the setting across ``incomparable spaces'' (e.g., of different dimensionality), corresponding to the Gromov- Wasserstein distance, remains underexplored, with existing methods often imposing restrictive assumptions on the cost function. In this paper, we present a novel neural formulation of the Gromov-Monge (GM) problem rooted in one of its fundamental properties: invariance to strong isomorphisms. We operationalize this property by decomposing the learnable OT map into two components: (i) an approximate strong isomorphism between the source distribution and an intermediate reference distribution, and (ii) a GM-optimal map between this reference and the target distribution. Our formulation leverages and extends the Monge gap regularizer of Uscidda & Cuturi (2023) to eliminate the need for complex architectural requirements of other neural OT methods, yielding a simple but practical method that enjoys favorable theoretical guarantees. Our preliminary empirical results show that our framework provides a promising approach to learn OT maps across diverse spaces.
Read more7/23/2024
🧠
0
GeONet: a neural operator for learning the Wasserstein geodesic
Andrew Gracyk, Xiaohui Chen
Optimal transport (OT) offers a versatile framework to compare complex data distributions in a geometrically meaningful way. Traditional methods for computing the Wasserstein distance and geodesic between probability measures require mesh-specific domain discretization and suffer from the curse-of-dimensionality. We present GeONet, a mesh-invariant deep neural operator network that learns the non-linear mapping from the input pair of initial and terminal distributions to the Wasserstein geodesic connecting the two endpoint distributions. In the offline training stage, GeONet learns the saddle point optimality conditions for the dynamic formulation of the OT problem in the primal and dual spaces that are characterized by a coupled PDE system. The subsequent inference stage is instantaneous and can be deployed for real-time predictions in the online learning setting. We demonstrate that GeONet achieves comparable testing accuracy to the standard OT solvers on simulation examples and the MNIST dataset with considerably reduced inference-stage computational cost by orders of magnitude.
Read more5/24/2024
0
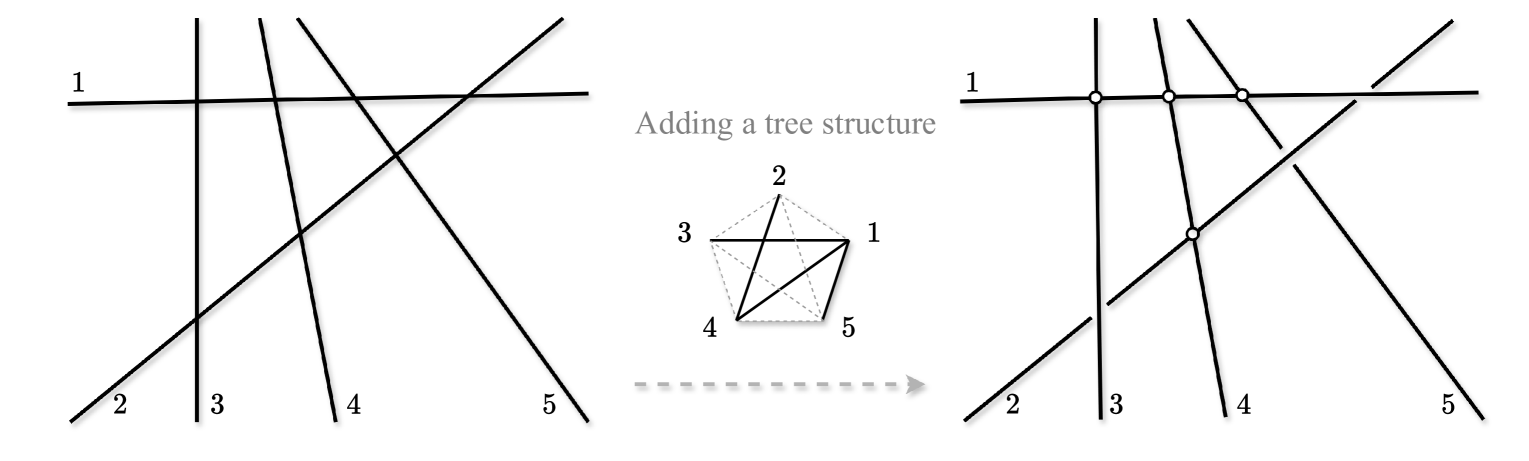
Tree-Sliced Wasserstein Distance on a System of Lines
Viet-Hoang Tran, Trang Pham, Tho Tran, Tam Le, Tan M. Nguyen
Sliced Wasserstein (SW) distance in Optimal Transport (OT) is widely used in various applications thanks to its statistical effectiveness and computational efficiency. On the other hand, Tree Wassenstein (TW) and Tree-sliced Wassenstein (TSW) are instances of OT for probability measures where its ground cost is a tree metric. TSW also has a low computational complexity, i.e. linear to the number of edges in the tree. Especially, TSW is identical to SW when the tree is a chain. While SW is prone to loss of topological information of input measures due to relying on one-dimensional projection, TSW is more flexible and has a higher degree of freedom by choosing a tree rather than a line to alleviate the curse of dimensionality in SW. However, for practical applications, popular tree metric sampling methods are heavily built upon given supports, which limits their capacity to adapt to new supports. In this paper, we propose the Tree-Sliced Wasserstein distance on a System of Lines (TSW-SL), which brings a connection between SW and TSW. Compared to SW and TSW, our TSW-SL benefits from the higher degree of freedom of TSW while being suitable to dynamic settings as SW. In TSW-SL, we use a variant of the Radon Transform to project measures onto a system of lines, resulting in measures on a space with a tree metric, then leverage TW to efficiently compute distances between them. We empirically verify the advantages of TSW-SL over the traditional SW by conducting a variety of experiments on gradient flows, image style transfer, and generative models.
Read more6/21/2024