Link Prediction with Untrained Message Passing Layers

0

Sign in to get full access
Overview
• This paper introduces a novel approach to link prediction using untrained message passing layers. • The proposed method aims to improve the performance of graph neural networks (GNNs) for link prediction tasks without the need for extensive training. • The researchers explore the use of untrained message passing layers to capture local structural information in the graph, which can be leveraged for link prediction.
Plain English Explanation
• Link prediction is the task of identifying missing connections or predicting new connections in a graph or network. This is an important problem in various fields, such as social network analysis, recommender systems, and biology. • Traditionally, GNNs have been used for link prediction, but they require extensive training to learn effective representations of the graph structure. • This paper presents an approach that uses untrained message passing layers to capture local structural information without the need for extensive training. • The idea is that even with untrained message passing layers, the model can still learn to identify patterns and features in the graph that are relevant for link prediction, without the need to train the entire network from scratch. • This can be particularly useful in scenarios where training data is limited or when the graph structure is constantly evolving, as the model can adapt more quickly to changes without the need for retraining.
Technical Explanation
• The paper proposes a message passing architecture for link prediction that uses untrained message passing layers to capture local structural information in the graph. • The authors first construct a hypergraph representation of the input graph, which allows them to model higher-order relationships between nodes. • They then use untrained message passing layers to propagate information between the nodes and hyperedges, effectively learning a representation of the local graph structure without the need for extensive training. • The final link prediction is performed by a simple neural network that takes the learned representations as input and outputs the likelihood of a link between two nodes. • The researchers evaluate their approach on several real-world datasets and show that it can outperform traditional GNN-based link prediction methods, especially in scenarios with limited training data.
Critical Analysis
• The paper presents a novel and interesting approach to link prediction that leverages untrained message passing layers to capture local structural information in the graph. • While the results are promising, the authors acknowledge that the performance of the proposed method may be sensitive to the specific graph characteristics and the quality of the hypergraph representation. • Additionally, the paper does not provide a thorough analysis of the computational complexity and scalability of the proposed approach, which could be a concern for large-scale graph datasets. • It would be interesting to see how the method performs compared to other graph rewiring techniques or alternative message passing architectures for link prediction.
Conclusion
• This paper presents a novel approach to link prediction that uses untrained message passing layers to capture local structural information in the graph, without the need for extensive training. • The proposed method shows promising results, particularly in scenarios with limited training data, and could be a valuable tool for various applications that require efficient and adaptable link prediction models. • While the paper raises some interesting questions and avenues for further research, the findings suggest that the use of untrained message passing layers is a promising direction for improving the performance of GNNs in link prediction tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Link Prediction with Untrained Message Passing Layers
Lisi Qarkaxhija, Anatol E. Wegner, Ingo Scholtes
Message passing neural networks (MPNNs) operate on graphs by exchanging information between neigbouring nodes. MPNNs have been successfully applied to various node-, edge-, and graph-level tasks in areas like molecular science, computer vision, natural language processing, and combinatorial optimization. However, most MPNNs require training on large amounts of labeled data, which can be costly and time-consuming. In this work, we explore the use of various untrained message passing layers in graph neural networks, i.e. variants of popular message passing architecture where we remove all trainable parameters that are used to transform node features in the message passing step. Focusing on link prediction, we find that untrained message passing layers can lead to competitive and even superior performance compared to fully trained MPNNs, especially in the presence of high-dimensional features. We provide a theoretical analysis of untrained message passing by relating the inner products of features implicitly produced by untrained message passing layers to path-based topological node similarity measures. As such, untrained message passing architectures can be viewed as a highly efficient and interpretable approach to link prediction.
Read more6/26/2024
0
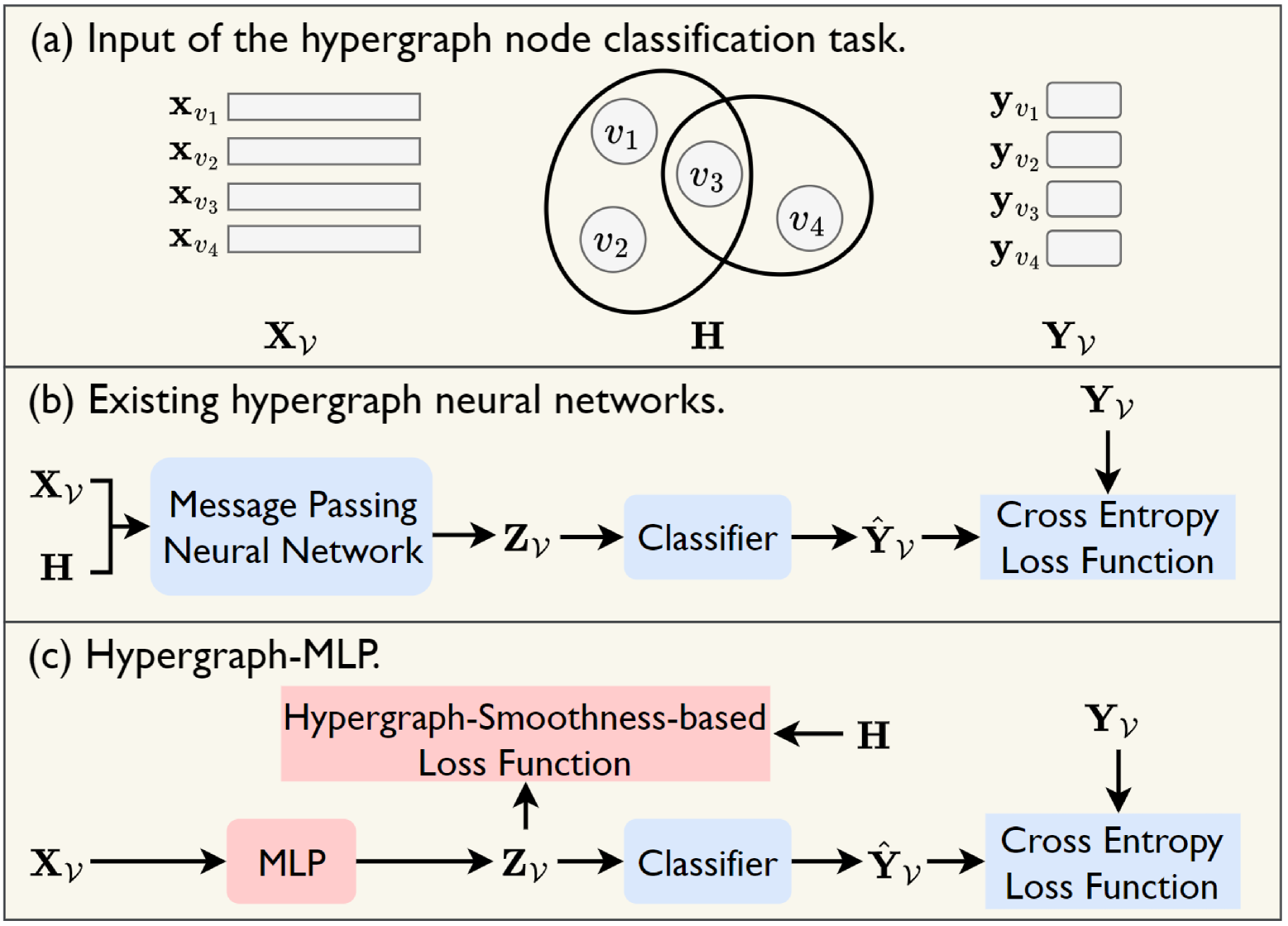
Hypergraph-MLP: Learning on Hypergraphs without Message Passing
Bohan Tang, Siheng Chen, Xiaowen Dong
Hypergraphs are vital in modelling data with higher-order relations containing more than two entities, gaining prominence in machine learning and signal processing. Many hypergraph neural networks leverage message passing over hypergraph structures to enhance node representation learning, yielding impressive performances in tasks like hypergraph node classification. However, these message-passing-based models face several challenges, including oversmoothing as well as high latency and sensitivity to structural perturbations at inference time. To tackle those challenges, we propose an alternative approach where we integrate the information about hypergraph structures into training supervision without explicit message passing, thus also removing the reliance on it at inference. Specifically, we introduce Hypergraph-MLP, a novel learning framework for hypergraph-structured data, where the learning model is a straightforward multilayer perceptron (MLP) supervised by a loss function based on a notion of signal smoothness on hypergraphs. Experiments on hypergraph node classification tasks demonstrate that Hypergraph-MLP achieves competitive performance compared to existing baselines, and is considerably faster and more robust against structural perturbations at inference.
Read more6/4/2024

0
All Against Some: Efficient Integration of Large Language Models for Message Passing in Graph Neural Networks
Ajay Jaiswal, Nurendra Choudhary, Ravinarayana Adkathimar, Muthu P. Alagappan, Gaurush Hiranandani, Ying Ding, Zhangyang Wang, Edward W Huang, Karthik Subbian
Graph Neural Networks (GNNs) have attracted immense attention in the past decade due to their numerous real-world applications built around graph-structured data. On the other hand, Large Language Models (LLMs) with extensive pretrained knowledge and powerful semantic comprehension abilities have recently shown a remarkable ability to benefit applications using vision and text data. In this paper, we investigate how LLMs can be leveraged in a computationally efficient fashion to benefit rich graph-structured data, a modality relatively unexplored in LLM literature. Prior works in this area exploit LLMs to augment every node features in an ad-hoc fashion (not scalable for large graphs), use natural language to describe the complex structural information of graphs, or perform computationally expensive finetuning of LLMs in conjunction with GNNs. We propose E-LLaGNN (Efficient LLMs augmented GNNs), a framework with an on-demand LLM service that enriches message passing procedure of graph learning by enhancing a limited fraction of nodes from the graph. More specifically, E-LLaGNN relies on sampling high-quality neighborhoods using LLMs, followed by on-demand neighborhood feature enhancement using diverse prompts from our prompt catalog, and finally information aggregation using message passing from conventional GNN architectures. We explore several heuristics-based active node selection strategies to limit the computational and memory footprint of LLMs when handling millions of nodes. Through extensive experiments & ablation on popular graph benchmarks of varying scales (Cora, PubMed, ArXiv, & Products), we illustrate the effectiveness of our E-LLaGNN framework and reveal many interesting capabilities such as improved gradient flow in deep GNNs, LLM-free inference ability etc.
Read more7/23/2024

0
Probabilistic Graph Rewiring via Virtual Nodes
Chendi Qian, Andrei Manolache, Christopher Morris, Mathias Niepert
Message-passing graph neural networks (MPNNs) have emerged as a powerful paradigm for graph-based machine learning. Despite their effectiveness, MPNNs face challenges such as under-reaching and over-squashing, where limited receptive fields and structural bottlenecks hinder information flow in the graph. While graph transformers hold promise in addressing these issues, their scalability is limited due to quadratic complexity regarding the number of nodes, rendering them impractical for larger graphs. Here, we propose implicitly rewired message-passing neural networks (IPR-MPNNs), a novel approach that integrates implicit probabilistic graph rewiring into MPNNs. By introducing a small number of virtual nodes, i.e., adding additional nodes to a given graph and connecting them to existing nodes, in a differentiable, end-to-end manner, IPR-MPNNs enable long-distance message propagation, circumventing quadratic complexity. Theoretically, we demonstrate that IPR-MPNNs surpass the expressiveness of traditional MPNNs. Empirically, we validate our approach by showcasing its ability to mitigate under-reaching and over-squashing effects, achieving state-of-the-art performance across multiple graph datasets. Notably, IPR-MPNNs outperform graph transformers while maintaining significantly faster computational efficiency.
Read more6/10/2024