LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition

0

Sign in to get full access
Overview
- The paper introduces LipGER, a visually-conditioned generative model that can correct errors in automatic speech recognition (ASR) output by leveraging visual information from lip movements.
- LipGER is designed to improve the robustness of ASR systems, especially in noisy environments where audio quality may be degraded.
- The model is trained to generate corrected text from the original ASR output and synchronized video of the speaker's lips.
Plain English Explanation
LipGER is a new AI system that can help fix mistakes made by speech recognition software. Speech recognition isn't perfect, especially when there's a lot of background noise. That's where LipGER comes in. It uses the video of a person's lips moving while they're speaking to figure out what they actually said, and then it corrects the mistakes in the speech recognition output.
The key idea is that even if the audio is hard to understand, the movement of a person's lips can provide valuable clues about what they're saying. LipGER learns to use this visual information to clean up the mistakes made by the speech recognition system. This builds on previous work on using audio-visual information for speech recognition.
By combining the audio and visual inputs, LipGER can provide more accurate and robust speech transcripts, which could be useful in a variety of applications like voice assistants, automatic captioning, and speech-to-text software. The visual information helps compensate for limitations in the audio-only speech recognition, making the system more reliable.
Technical Explanation
LipGER is a neural network model that takes two inputs - the original speech recognition output and a video of the speaker's lips. It then generates a corrected version of the text, utilizing the visual information from the lip movements to fix mistakes in the speech transcript.
The model architecture includes an encoder to process the speech recognition output, a video encoder to extract features from the lip movements, and a decoder that generates the corrected text. The multi-modal, multi-granularity approach allows LipGER to effectively leverage both audio and visual cues.
During training, the model learns to map the noisy speech recognition output and synchronized lip video to the ground truth, clean transcript. This visually-conditioned generative error correction enables LipGER to robustly handle speech recognition failures, going beyond prior approaches that just re-ranked or post-processed the ASR output.
Critical Analysis
The paper provides a thorough evaluation of LipGER, demonstrating its ability to significantly improve speech recognition accuracy compared to audio-only baselines, especially in noisy conditions. The authors also discuss some of the limitations of their approach, such as the reliance on parallel audio-visual data for training.
One potential concern is the computational cost and latency of running the full LipGER model during inference, which could limit its real-time applications. The authors note that further work is needed to optimize the model for efficiency.
Additionally, the paper does not address potential privacy concerns around the use of video footage, which some users may be hesitant to provide. Exploring more privacy-preserving approaches, such as using lower resolution or anonymized video, could be an interesting area for future research.
Overall, LipGER represents a promising step forward in leveraging multi-modal information to enhance the robustness and accuracy of automatic speech recognition systems.
Conclusion
The LipGER model introduced in this paper demonstrates the value of combining audio and visual cues for improving the performance of automatic speech recognition, particularly in noisy environments. By using lip movements to correct errors in the speech transcript, LipGER can provide more reliable and accurate transcripts, with potential applications in voice assistants, closed captioning, and other speech-to-text systems.
While there are still some challenges to address, such as computational efficiency and privacy concerns, the core ideas behind LipGER highlight the importance of multi-modal approaches in building more robust and capable artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition
Sreyan Ghosh, Sonal Kumar, Ashish Seth, Purva Chiniya, Utkarsh Tyagi, Ramani Duraiswami, Dinesh Manocha
Visual cues, like lip motion, have been shown to improve the performance of Automatic Speech Recognition (ASR) systems in noisy environments. We propose LipGER (Lip Motion aided Generative Error Correction), a novel framework for leveraging visual cues for noise-robust ASR. Instead of learning the cross-modal correlation between the audio and visual modalities, we make an LLM learn the task of visually-conditioned (generative) ASR error correction. Specifically, we instruct an LLM to predict the transcription from the N-best hypotheses generated using ASR beam-search. This is further conditioned on lip motions. This approach addresses key challenges in traditional AVSR learning, such as the lack of large-scale paired datasets and difficulties in adapting to new domains. We experiment on 4 datasets in various settings and show that LipGER improves the Word Error Rate in the range of 1.1%-49.2%. We also release LipHyp, a large-scale dataset with hypothesis-transcription pairs that is additionally equipped with lip motion cues to promote further research in this space
Read more6/10/2024

0
Listen Again and Choose the Right Answer: A New Paradigm for Automatic Speech Recognition with Large Language Models
Yuchen Hu, Chen Chen, Chengwei Qin, Qiushi Zhu, Eng Siong Chng, Ruizhe Li
Recent advances in large language models (LLMs) have promoted generative error correction (GER) for automatic speech recognition (ASR), which aims to predict the ground-truth transcription from the decoded N-best hypotheses. Thanks to the strong language generation ability of LLMs and rich information in the N-best list, GER shows great effectiveness in enhancing ASR results. However, it still suffers from two limitations: 1) LLMs are unaware of the source speech during GER, which may lead to results that are grammatically correct but violate the source speech content, 2) N-best hypotheses usually only vary in a few tokens, making it redundant to send all of them for GER, which could confuse LLM about which tokens to focus on and thus lead to increased miscorrection. In this paper, we propose ClozeGER, a new paradigm for ASR generative error correction. First, we introduce a multimodal LLM (i.e., SpeechGPT) to receive source speech as extra input to improve the fidelity of correction output. Then, we reformat GER as a cloze test with logits calibration to remove the input information redundancy and simplify GER with clear instructions. Experiments show that ClozeGER achieves a new breakthrough over vanilla GER on 9 popular ASR datasets.
Read more5/17/2024
0
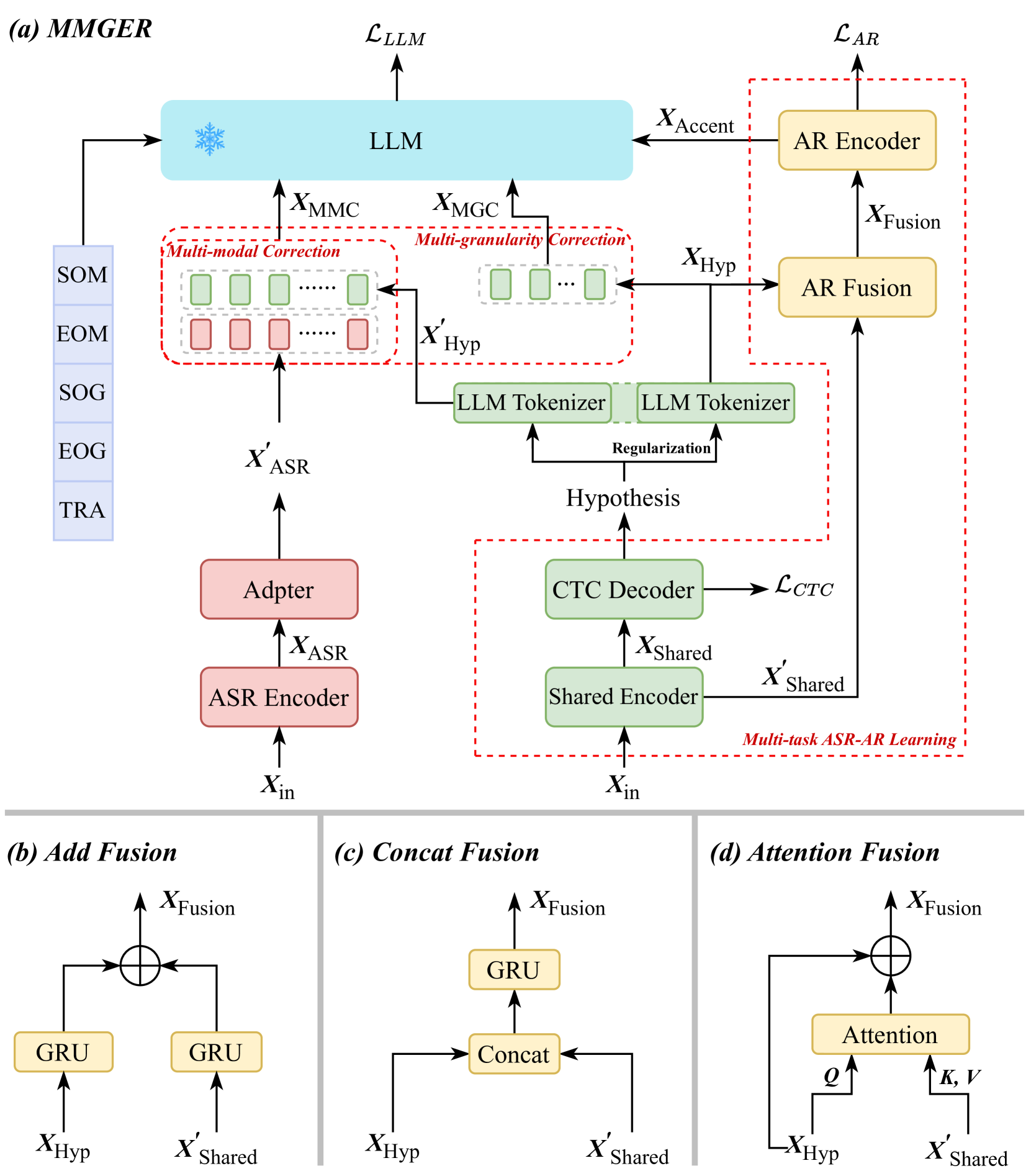
MMGER: Multi-modal and Multi-granularity Generative Error Correction with LLM for Joint Accent and Speech Recognition
Bingshen Mu, Yangze Li, Qijie Shao, Kun Wei, Xucheng Wan, Naijun Zheng, Huan Zhou, Lei Xie
Despite notable advancements in automatic speech recognition (ASR), performance tends to degrade when faced with adverse conditions. Generative error correction (GER) leverages the exceptional text comprehension capabilities of large language models (LLM), delivering impressive performance in ASR error correction, where N-best hypotheses provide valuable information for transcription prediction. However, GER encounters challenges such as fixed N-best hypotheses, insufficient utilization of acoustic information, and limited specificity to multi-accent scenarios. In this paper, we explore the application of GER in multi-accent scenarios. Accents represent deviations from standard pronunciation norms, and the multi-task learning framework for simultaneous ASR and accent recognition (AR) has effectively addressed the multi-accent scenarios, making it a prominent solution. In this work, we propose a unified ASR-AR GER model, named MMGER, leveraging multi-modal correction, and multi-granularity correction. Multi-task ASR-AR learning is employed to provide dynamic 1-best hypotheses and accent embeddings. Multi-modal correction accomplishes fine-grained frame-level correction by force-aligning the acoustic features of speech with the corresponding character-level 1-best hypothesis sequence. Multi-granularity correction supplements the global linguistic information by incorporating regular 1-best hypotheses atop fine-grained multi-modal correction to achieve coarse-grained utterance-level correction. MMGER effectively mitigates the limitations of GER and tailors LLM-based ASR error correction for the multi-accent scenarios. Experiments conducted on the multi-accent Mandarin KeSpeech dataset demonstrate the efficacy of MMGER, achieving a 26.72% relative improvement in AR accuracy and a 27.55% relative reduction in ASR character error rate, compared to a well-established standard baseline.
Read more5/8/2024

0
Benchmarking Japanese Speech Recognition on ASR-LLM Setups with Multi-Pass Augmented Generative Error Correction
Yuka Ko, Sheng Li, Chao-Han Huck Yang, Tatsuya Kawahara
With the strong representational power of large language models (LLMs), generative error correction (GER) for automatic speech recognition (ASR) aims to provide semantic and phonetic refinements to address ASR errors. This work explores how LLM-based GER can enhance and expand the capabilities of Japanese language processing, presenting the first GER benchmark for Japanese ASR with 0.9-2.6k text utterances. We also introduce a new multi-pass augmented generative error correction (MPA GER) by integrating multiple system hypotheses on the input side with corrections from multiple LLMs on the output side and then merging them. To the best of our knowledge, this is the first investigation of the use of LLMs for Japanese GER, which involves second-pass language modeling on the output transcriptions generated by the ASR system (e.g., N-best hypotheses). Our experiments demonstrated performance improvement in the proposed methods of ASR quality and generalization both in SPREDS-U1-ja and CSJ data.
Read more8/30/2024