Audio-Visual Speech Representation Expert for Enhanced Talking Face Video Generation and Evaluation
2405.04327
0
0
🗣️
Abstract
In the task of talking face generation, the objective is to generate a face video with lips synchronized to the corresponding audio while preserving visual details and identity information. Current methods face the challenge of learning accurate lip synchronization while avoiding detrimental effects on visual quality, as well as robustly evaluating such synchronization. To tackle these problems, we propose utilizing an audio-visual speech representation expert (AV-HuBERT) for calculating lip synchronization loss during training. Moreover, leveraging AV-HuBERT's features, we introduce three novel lip synchronization evaluation metrics, aiming to provide a comprehensive assessment of lip synchronization performance. Experimental results, along with a detailed ablation study, demonstrate the effectiveness of our approach and the utility of the proposed evaluation metrics.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The goal of "talking face generation" is to create a video of a face with lips that are synchronized to the corresponding audio, while preserving the person's visual details and identity.
- Current methods struggle to learn accurate lip synchronization without negatively impacting visual quality, and struggle to effectively evaluate such synchronization.
- To address these challenges, the researchers propose using an audio-visual speech representation expert (AV-HuBERT) to calculate lip synchronization loss during training.
- They also introduce three new lip synchronization evaluation metrics that leverage AV-HuBERT's features, aiming to provide a more comprehensive assessment of lip synchronization performance.
- Experimental results and an ablation study demonstrate the effectiveness of their approach and the utility of the proposed evaluation metrics.
Plain English Explanation
The researchers are working on a problem called "talking face generation." The goal is to create a video of a person's face where the movements of the lips are perfectly synchronized with the audio. This is challenging because you need to get the lip movements just right without compromising the overall visual quality or the person's identity.
To tackle this, the researchers use a special AI model called AV-HuBERT to help train their system. AV-HuBERT is an expert at understanding the relationship between audio and lip movements, so the researchers use it to measure how well their system is synchronizing the lips to the audio during training.
Additionally, the researchers developed three new ways to evaluate how well their system is doing at lip synchronization. These new evaluation metrics also use features from AV-HuBERT to provide a more comprehensive assessment.
Through their experiments, the researchers showed that their approach is effective at generating talking faces with accurate lip synchronization without degrading the visual quality. The new evaluation metrics they introduced also prove to be useful tools for assessing lip synchronization performance.
Technical Explanation
The researchers tackle the task of talking face generation, which involves generating a video of a face with lips synchronized to the corresponding audio, while preserving visual details and identity information.
To address the challenge of learning accurate lip synchronization without compromising visual quality, the researchers propose utilizing an audio-visual speech representation expert (AV-HuBERT) to calculate lip synchronization loss during training. AV-HuBERT is a model that has been pre-trained on a large amount of audio-visual speech data, giving it a deep understanding of the relationship between audio and lip movements.
Furthermore, the researchers leverage AV-HuBERT's features to introduce three novel lip synchronization evaluation metrics: TAVG-Bench, VASA-1, and CSTalk. These metrics aim to provide a more comprehensive assessment of lip synchronization performance, going beyond traditional evaluation methods.
The researchers' experimental results, along with a detailed ablation study, demonstrate the effectiveness of their approach and the utility of the proposed evaluation metrics. The use of AV-HuBERT helps the system learn accurate lip synchronization, while the new evaluation metrics provide valuable insights into the system's performance.
Critical Analysis
The researchers acknowledge that their approach has some limitations. For example, they note that their system may struggle with handling emotional expressions or extreme head poses, as these could introduce additional challenges for lip synchronization. Additionally, the researchers suggest that further research is needed to explore the potential of AV-HuBERT for other audio-visual tasks beyond talking face generation.
While the researchers demonstrate the effectiveness of their approach, it would be interesting to see how it compares to other state-of-the-art methods in the field, such as those discussed in the PEAVS paper, which focuses on perceptual evaluation of audio-visual synchrony. A more comprehensive comparison could provide valuable insights into the relative strengths and weaknesses of different approaches.
Overall, the researchers have made a meaningful contribution to the field of talking face generation by leveraging advanced audio-visual representation learning and introducing novel evaluation metrics. Their work highlights the importance of addressing both the technical and perceptual aspects of lip synchronization to achieve high-quality talking face generation.
Conclusion
This paper presents a novel approach to the task of talking face generation, which involves generating a video of a face with lips synchronized to the corresponding audio while preserving visual details and identity information. The researchers utilize an audio-visual speech representation expert (AV-HuBERT) to improve lip synchronization during training and introduce three novel evaluation metrics to provide a more comprehensive assessment of lip synchronization performance.
The researchers' experimental results demonstrate the effectiveness of their approach and the utility of the proposed evaluation metrics. This work contributes to the ongoing efforts in the field of talking face generation, which has important applications in areas such as virtual assistants, film production, and video conferencing. By addressing the challenges of accurate lip synchronization and robust evaluation, the researchers have made progress towards more lifelike and compelling talking face generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
SwapTalk: Audio-Driven Talking Face Generation with One-Shot Customization in Latent Space
Zeren Zhang, Haibo Qin, Jiayu Huang, Yixin Li, Hui Lin, Yitao Duan, Jinwen Ma
0
0
Combining face swapping with lip synchronization technology offers a cost-effective solution for customized talking face generation. However, directly cascading existing models together tends to introduce significant interference between tasks and reduce video clarity because the interaction space is limited to the low-level semantic RGB space. To address this issue, we propose an innovative unified framework, SwapTalk, which accomplishes both face swapping and lip synchronization tasks in the same latent space. Referring to recent work on face generation, we choose the VQ-embedding space due to its excellent editability and fidelity performance. To enhance the framework's generalization capabilities for unseen identities, we incorporate identity loss during the training of the face swapping module. Additionally, we introduce expert discriminator supervision within the latent space during the training of the lip synchronization module to elevate synchronization quality. In the evaluation phase, previous studies primarily focused on the self-reconstruction of lip movements in synchronous audio-visual videos. To better approximate real-world applications, we expand the evaluation scope to asynchronous audio-video scenarios. Furthermore, we introduce a novel identity consistency metric to more comprehensively assess the identity consistency over time series in generated facial videos. Experimental results on the HDTF demonstrate that our method significantly surpasses existing techniques in video quality, lip synchronization accuracy, face swapping fidelity, and identity consistency. Our demo is available at http://swaptalk.cc.
5/10/2024

Learn2Talk: 3D Talking Face Learns from 2D Talking Face
Yixiang Zhuang, Baoping Cheng, Yao Cheng, Yuntao Jin, Renshuai Liu, Chengyang Li, Xuan Cheng, Jing Liao, Juncong Lin
0
0
Speech-driven facial animation methods usually contain two main classes, 3D and 2D talking face, both of which attract considerable research attention in recent years. However, to the best of our knowledge, the research on 3D talking face does not go deeper as 2D talking face, in the aspect of lip-synchronization (lip-sync) and speech perception. To mind the gap between the two sub-fields, we propose a learning framework named Learn2Talk, which can construct a better 3D talking face network by exploiting two expertise points from the field of 2D talking face. Firstly, inspired by the audio-video sync network, a 3D sync-lip expert model is devised for the pursuit of lip-sync between audio and 3D facial motion. Secondly, a teacher model selected from 2D talking face methods is used to guide the training of the audio-to-3D motions regression network to yield more 3D vertex accuracy. Extensive experiments show the advantages of the proposed framework in terms of lip-sync, vertex accuracy and speech perception, compared with state-of-the-arts. Finally, we show two applications of the proposed framework: audio-visual speech recognition and speech-driven 3D Gaussian Splatting based avatar animation.
4/22/2024
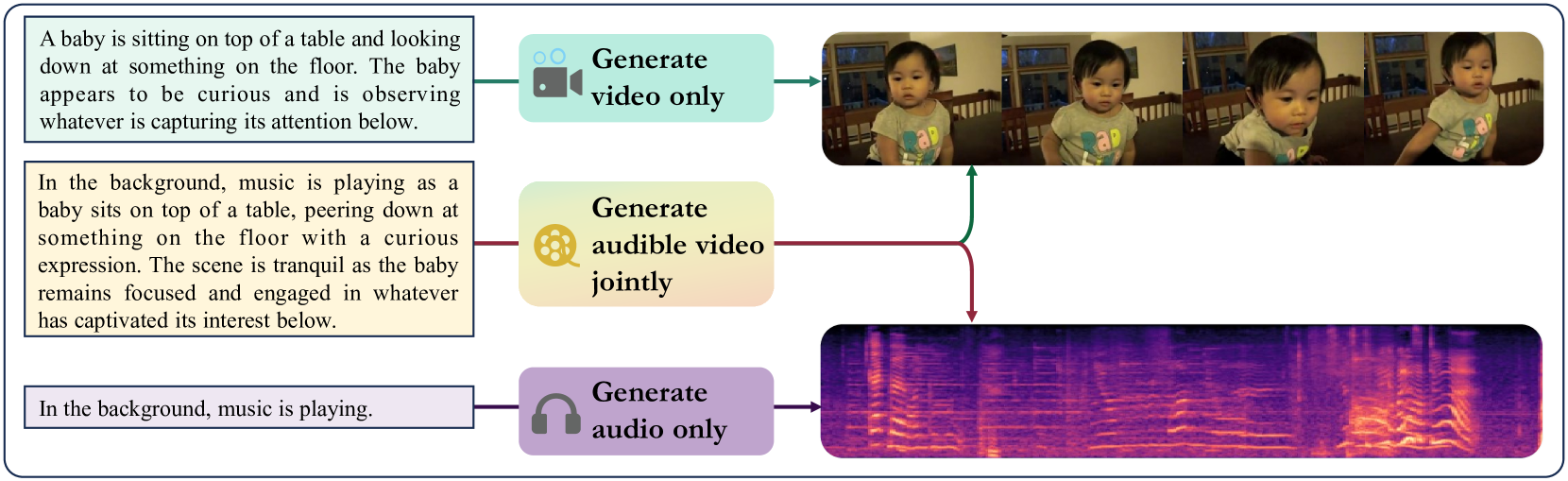
TAVGBench: Benchmarking Text to Audible-Video Generation
Yuxin Mao, Xuyang Shen, Jing Zhang, Zhen Qin, Jinxing Zhou, Mochu Xiang, Yiran Zhong, Yuchao Dai
0
0
The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.
4/23/2024

VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, Baining Guo
0
0
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
4/17/2024