LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
2403.17919
3
0

Abstract
The machine learning community has witnessed impressive advancements since large language models (LLMs) first appeared. Yet, their massive memory consumption has become a significant roadblock to large-scale training. For instance, a 7B model typically requires at least 60 GB of GPU memory with full parameter training, which presents challenges for researchers without access to high-resource environments. Parameter Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA) have been proposed to alleviate this problem. However, in most large-scale fine-tuning settings, their performance does not reach the level of full parameter training because they confine the parameter search to a low-rank subspace. Attempting to complement this deficiency, we investigate the layerwise properties of LoRA on fine-tuning tasks and observe an unexpected but consistent skewness of weight norms across different layers. Utilizing this key observation, a surprisingly simple training strategy is discovered, which outperforms both LoRA and full parameter training in a wide range of settings with memory costs as low as LoRA. We name it Layerwise Importance Sampled AdamW (LISA), a promising alternative for LoRA, which applies the idea of importance sampling to different layers in LLMs and randomly freezes most middle layers during optimization. Experimental results show that with similar or less GPU memory consumption, LISA surpasses LoRA or even full parameter tuning in downstream fine-tuning tasks, where LISA consistently outperforms LoRA by over 10%-35% in terms of MT-Bench score while achieving on-par or better performance in MMLU, AGIEval and WinoGrande. On large models, specifically LLaMA-2-70B, LISA surpasses LoRA on MT-Bench, GSM8K, and PubMedQA, demonstrating its effectiveness across different domains.
Create account to get full access
Overview
- This paper introduces LISA (Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning), a novel technique for fine-tuning large language models in a more memory-efficient manner.
- LISA leverages the concept of layerwise importance sampling to selectively update the most important parameters during fine-tuning, reducing the memory footprint and enabling the fine-tuning of larger models on constrained hardware.
- The authors demonstrate the effectiveness of LISA on a range of language tasks, showing that it can match the performance of traditional fine-tuning approaches while using significantly less memory.
Plain English Explanation
Large language models like LORA, LORA-Learns, and MixLORA have become powerful tools for a wide range of natural language processing tasks. However, fine-tuning these models can be memory-intensive, often requiring powerful hardware that may not be accessible to all researchers and developers.
LISA addresses this challenge by using a technique called "layerwise importance sampling" to selectively update the most important parameters during fine-tuning. This means that instead of updating all the parameters in the model, LISA focuses on updating only the most crucial ones, reducing the overall memory footprint.
The key idea behind LISA is to analyze the model's layers and identify the ones that are most important for the specific task at hand. This information is then used to guide the fine-tuning process, ensuring that the most critical parameters are updated while the less important ones are left unchanged. As a result, LISA can achieve similar performance to traditional fine-tuning methods, but with significantly less memory usage, making it possible to fine-tune larger models on constrained hardware.
Technical Explanation
LISA builds on the concept of layerwise importance sampling, which has been shown to be an effective way to reduce the memory footprint of large language model fine-tuning. The main idea behind LISA is to selectively update the most important parameters in the model during the fine-tuning process, rather than updating all parameters equally.
To achieve this, LISA first analyzes the importance of each layer in the model with respect to the target task. This is done by computing a layerwise importance score, which captures the sensitivity of the model's output to changes in the parameters of each layer. The layers with the highest importance scores are then selected for fine-tuning, while the remaining layers are left unchanged.
During the fine-tuning process, LISA only updates the parameters of the selected layers, significantly reducing the memory required for the operation. The authors demonstrate that this approach can match the performance of traditional fine-tuning methods while using up to 75% less memory, enabling the fine-tuning of larger language models on constrained hardware.
The authors evaluate LISA on a range of language tasks, including text classification, sequence labeling, and natural language inference. The results show that LISA can achieve comparable or even superior performance to traditional fine-tuning approaches, while requiring significantly less memory. Additionally, the authors provide LORA-XS, a further extension of LISA that enables the fine-tuning of extremely small language models, opening up new possibilities for deploying large language models on edge devices and other resource-constrained environments.
Critical Analysis
The LISA approach presented in this paper is a promising step towards more memory-efficient fine-tuning of large language models. By selectively updating the most important parameters, LISA can significantly reduce the memory footprint of the fine-tuning process, making it possible to work with larger models on constrained hardware.
One potential limitation of LISA is that the layerwise importance scoring mechanism may not always accurately capture the true importance of each layer for a given task. The authors acknowledge this and suggest that further research is needed to explore more sophisticated importance scoring methods, potentially incorporating task-specific information or leveraging gradient-based techniques.
Additionally, the paper does not address the potential for the LISA approach to introduce unwanted biases or performance degradation in certain scenarios. It would be valuable to explore the robustness of LISA-based fine-tuning, particularly in sensitive domains or when dealing with underrepresented data.
Overall, the LISA technique represents an important contribution to the field of large language model optimization, and the authors' efforts to reduce the memory footprint of fine-tuning are commendable. As the size and complexity of these models continue to grow, techniques like LISA will become increasingly important for enabling their widespread adoption and deployment.
Conclusion
The LISA paper presents a novel approach for fine-tuning large language models in a more memory-efficient manner. By leveraging layerwise importance sampling, LISA can selectively update the most critical parameters during fine-tuning, significantly reducing the memory footprint while maintaining comparable or even superior performance to traditional fine-tuning methods.
The authors' work on LISA and the related LORA-XS extension demonstrates the potential for optimizing the deployment of large language models on constrained hardware, opening up new opportunities for applying these powerful AI systems in a wider range of real-world applications. As the field of natural language processing continues to evolve, techniques like LISA will likely play an increasingly important role in enabling the scalable and efficient use of large language models across a diverse set of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
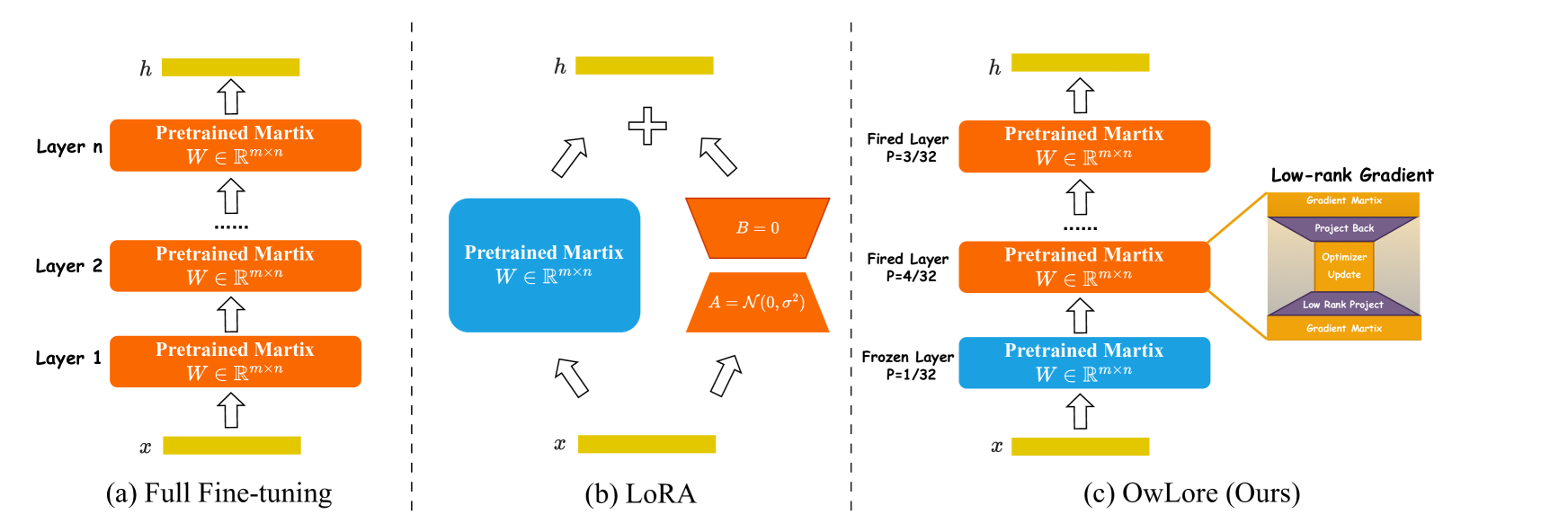
OwLore: Outlier-weighed Layerwise Sampled Low-Rank Projection for Memory-Efficient LLM Fine-tuning
Pengxiang Li, Lu Yin, Xiaowei Gao, Shiwei Liu
0
0
The rapid advancements in Large Language Models (LLMs) have revolutionized various natural language processing tasks. However, the substantial size of LLMs presents significant challenges in training or fine-tuning. While parameter-efficient approaches such as low-rank adaptation (LoRA) have gained popularity, they often compromise performance compared to full-rank fine-tuning. In this paper, we propose Outlier-weighed Layerwise Sampled Low-Rank Projection (OwLore), a new memory-efficient fine-tuning approach, inspired by the layerwise outlier distribution of LLMs, which dynamically samples pre-trained layers to fine-tune instead of adding additional adaptors. We first interpret the outlier phenomenon through the lens of Heavy-Tailed Self-Regularization theory (HT-SR), discovering that layers with more outliers tend to be more heavy-tailed and consequently better trained. Inspired by this finding, OwLore strategically assigns higher sampling probabilities to layers with more outliers to better leverage the knowledge stored in pre-trained LLMs. To further mitigate the memory demands of fine-tuning, we integrate gradient low-rank projection into our approach, which facilitates each layer to be efficiently trained in a low-rank manner. By incorporating the efficient characteristics of low-rank and optimal layerwise sampling, OwLore significantly improves the memory-performance trade-off in LLM pruning. Our extensive experiments across various architectures, including LLaMa2, LLaMa3, and Mistral, demonstrate that OwLore consistently outperforms baseline approaches, including full fine-tuning. Specifically, it achieves up to a 1.1% average accuracy gain on the Commonsense Reasoning benchmark, a 3.0% improvement on MMLU, and a notable 10% boost on MT-Bench, while being more memory efficient. OwLore allows us to fine-tune LLaMa2-7B with only 21GB of memory.
5/29/2024
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
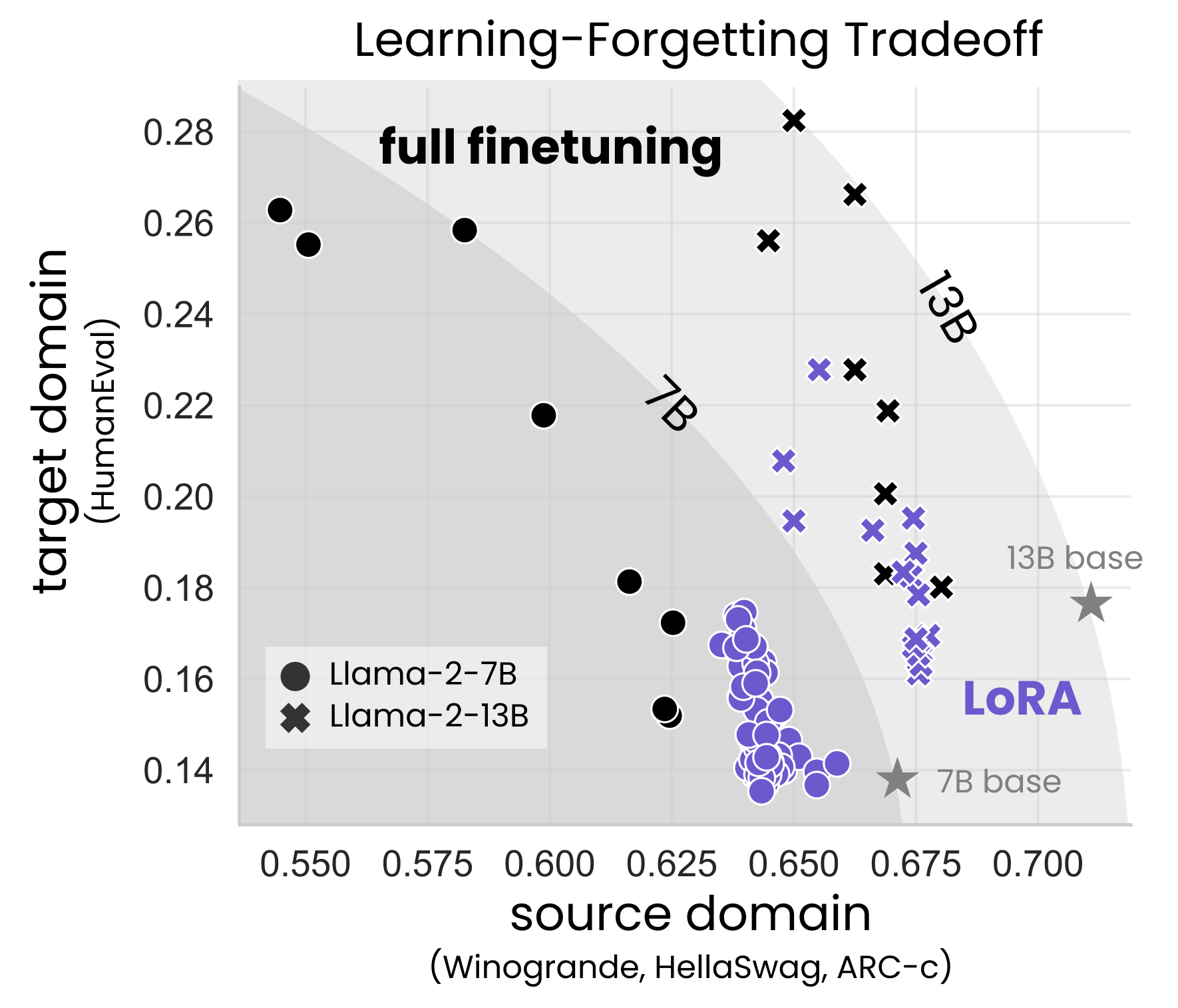
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
0
0
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
5/17/2024
💬
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal Yang, Mingjie Tang
0
0
Fine-tuning Large Language Models (LLMs) is a common practice to adapt pre-trained models for specific applications. While methods like LoRA have effectively addressed GPU memory constraints during fine-tuning, their performance often falls short, especially in multi-task scenarios. In contrast, Mixture-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance in multi-task learning scenarios while maintaining a reduced parameter count. However, the resource requirements of these MoEs remain challenging, particularly for consumer-grade GPUs with less than 24GB memory. To tackle these challenges, we propose MixLoRA, an approach to construct a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model and employs a commonly used top-k router. Unlike other LoRA-based MoE methods, MixLoRA enhances model performance by utilizing independent attention-layer LoRA adapters. Additionally, an auxiliary load balance loss is employed to address the imbalance problem of the router. Our evaluations show that MixLoRA improves about 9% accuracy compared to state-of-the-art PEFT methods in multi-task learning scenarios. We also propose a new high-throughput framework to alleviate the computation and memory bottlenecks during the training and inference of MOE models. This framework reduces GPU memory consumption by 40% and token computation latency by 30% during both training and inference.
5/24/2024