OwLore: Outlier-weighed Layerwise Sampled Low-Rank Projection for Memory-Efficient LLM Fine-tuning
2405.18380
0
0
Abstract
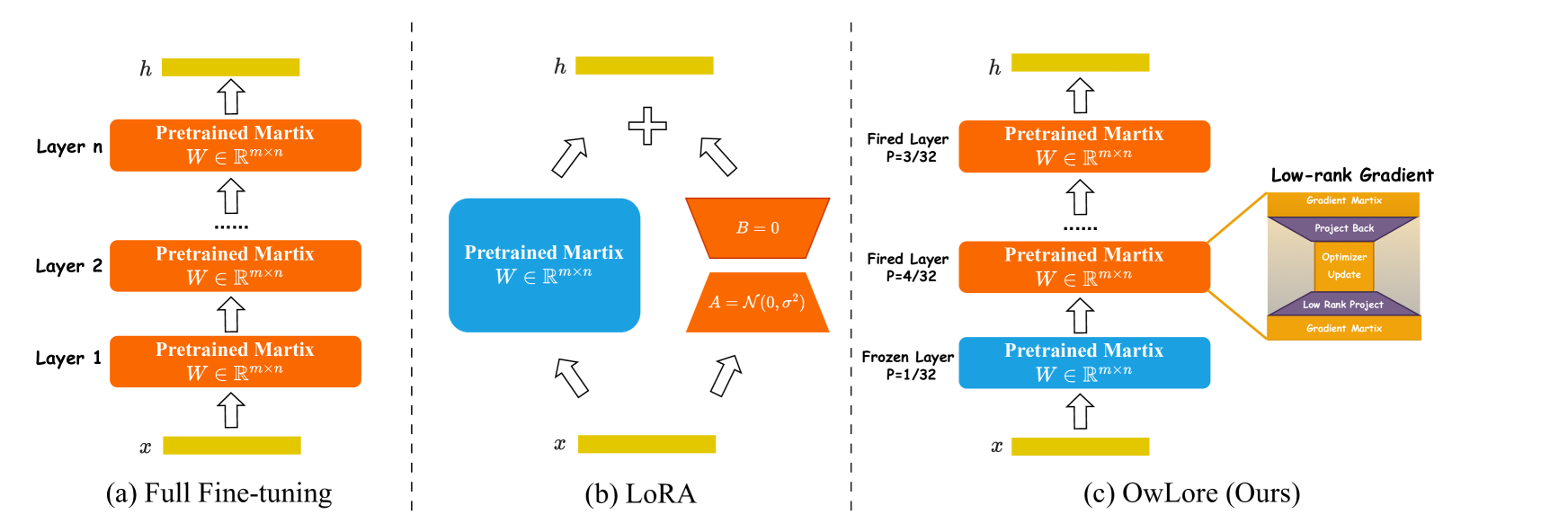
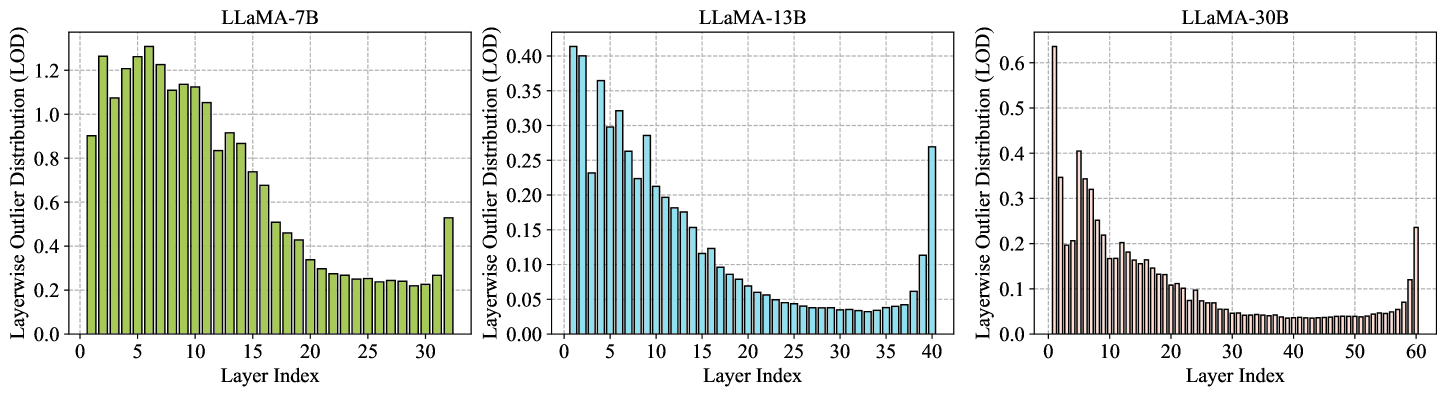
The rapid advancements in Large Language Models (LLMs) have revolutionized various natural language processing tasks. However, the substantial size of LLMs presents significant challenges in training or fine-tuning. While parameter-efficient approaches such as low-rank adaptation (LoRA) have gained popularity, they often compromise performance compared to full-rank fine-tuning. In this paper, we propose Outlier-weighed Layerwise Sampled Low-Rank Projection (OwLore), a new memory-efficient fine-tuning approach, inspired by the layerwise outlier distribution of LLMs, which dynamically samples pre-trained layers to fine-tune instead of adding additional adaptors. We first interpret the outlier phenomenon through the lens of Heavy-Tailed Self-Regularization theory (HT-SR), discovering that layers with more outliers tend to be more heavy-tailed and consequently better trained. Inspired by this finding, OwLore strategically assigns higher sampling probabilities to layers with more outliers to better leverage the knowledge stored in pre-trained LLMs. To further mitigate the memory demands of fine-tuning, we integrate gradient low-rank projection into our approach, which facilitates each layer to be efficiently trained in a low-rank manner. By incorporating the efficient characteristics of low-rank and optimal layerwise sampling, OwLore significantly improves the memory-performance trade-off in LLM pruning. Our extensive experiments across various architectures, including LLaMa2, LLaMa3, and Mistral, demonstrate that OwLore consistently outperforms baseline approaches, including full fine-tuning. Specifically, it achieves up to a 1.1% average accuracy gain on the Commonsense Reasoning benchmark, a 3.0% improvement on MMLU, and a notable 10% boost on MT-Bench, while being more memory efficient. OwLore allows us to fine-tune LLaMa2-7B with only 21GB of memory.
Create account to get full access
Overview
- Introduces a new method called OwLore (Outlier-weighed Layerwise Sampled Low-Rank Projection) for fine-tuning large language models (LLMs) more efficiently
- Aims to address challenges like catastrophic forgetting and high memory/compute requirements in LLM fine-tuning
- Proposes a layerwise importance sampling approach to selectively fine-tune only the most relevant parts of the model
Plain English Explanation
Large language models (LLMs) like GPT-3 are extremely powerful, but fine-tuning them for specific tasks can be challenging. One major issue is "catastrophic forgetting" - when fine-tuning the model on a new task, it can forget important knowledge it had learned previously.
The OwLore method proposed in this paper tries to address this by selectively fine-tuning only the most important parts of the LLM. It does this through a technique called "layerwise importance sampling." The key idea is to identify the most important neurons or features in each layer of the model, and only update those during fine-tuning. This helps the model retain more of its original knowledge while still adapting to the new task.
OwLore also incorporates an "outlier weighting" approach to give more importance to rare but important features during fine-tuning. This can help the model better capture nuanced information that may be critical for certain tasks.
By fine-tuning the model more selectively, OwLore aims to achieve similar performance to full fine-tuning, but with much lower memory and compute requirements. This could make it easier and more practical to adapt large language models to a wide range of applications.
Technical Explanation
The OwLore method builds on prior work like LISA and LoRA, which also explored selective fine-tuning approaches to improve efficiency. However, OwLore introduces some novel components:
-
Layerwise Importance Sampling: The model first identifies the most important neurons/features in each layer of the LLM using a layerwise importance scoring metric. Only the top-ranked features in each layer are then fine-tuned, reducing the overall number of parameters updated.
-
Outlier Weighting: The importance scoring also incorporates an "outlier weighting" factor, giving higher priority to rare but potentially critical features. This helps the model better capture nuanced information.
-
Low-Rank Projection: The fine-tuned updates are applied through a low-rank projection, further reducing the memory footprint compared to full fine-tuning approaches like LoRA.
The authors evaluate OwLore on various benchmark tasks and show it can achieve comparable performance to full fine-tuning, while using much less memory and compute resources. This makes it a promising approach for efficiently adapting large language models to different applications.
Critical Analysis
The paper presents a well-designed study with thorough experiments to validate the OwLore method. The authors provide a clear technical explanation of the approach and situate it within the context of related work.
One potential limitation is that the evaluation is primarily focused on standard NLP benchmarks. It would be interesting to see how OwLore performs on more specialized or domain-specific tasks, where the ability to capture nuanced information could be particularly important.
Additionally, the paper does not explore the potential for negative societal impacts of these types of efficient fine-tuning techniques. As LLMs become more widely deployed, it will be crucial to consider issues of fairness and responsible AI development.
Overall, the OwLore method appears to be a valuable contribution to the ongoing research on making large language models more flexible and practical to deploy. However, as with any powerful AI technology, careful consideration of its implications and limitations will be essential.
Conclusion
The OwLore paper presents an innovative approach to fine-tuning large language models more efficiently. By selectively updating only the most important parts of the model using layerwise importance sampling and outlier weighting, OwLore can achieve similar performance to full fine-tuning while using much less memory and compute resources.
This type of selective fine-tuning technique could make it more practical to adapt powerful LLMs to a wide range of applications, from language generation to task-specific AI assistants. As the field of large language models continues to evolve, methods like OwLore will likely play an important role in unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning
Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, Tong Zhang
0
0
The machine learning community has witnessed impressive advancements since large language models (LLMs) first appeared. Yet, their massive memory consumption has become a significant roadblock to large-scale training. For instance, a 7B model typically requires at least 60 GB of GPU memory with full parameter training, which presents challenges for researchers without access to high-resource environments. Parameter Efficient Fine-Tuning techniques such as Low-Rank Adaptation (LoRA) have been proposed to alleviate this problem. However, in most large-scale fine-tuning settings, their performance does not reach the level of full parameter training because they confine the parameter search to a low-rank subspace. Attempting to complement this deficiency, we investigate the layerwise properties of LoRA on fine-tuning tasks and observe an unexpected but consistent skewness of weight norms across different layers. Utilizing this key observation, a surprisingly simple training strategy is discovered, which outperforms both LoRA and full parameter training in a wide range of settings with memory costs as low as LoRA. We name it Layerwise Importance Sampled AdamW (LISA), a promising alternative for LoRA, which applies the idea of importance sampling to different layers in LLMs and randomly freezes most middle layers during optimization. Experimental results show that with similar or less GPU memory consumption, LISA surpasses LoRA or even full parameter tuning in downstream fine-tuning tasks, where LISA consistently outperforms LoRA by over 10%-35% in terms of MT-Bench score while achieving on-par or better performance in MMLU, AGIEval and WinoGrande. On large models, specifically LLaMA-2-70B, LISA surpasses LoRA on MT-Bench, GSM8K, and PubMedQA, demonstrating its effectiveness across different domains.
5/28/2024

GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, Yuandong Tian
0
0
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
6/4/2024
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity
Lu Yin, You Wu, Zhenyu Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Gen Li, Ajay Jaiswal, Mykola Pechenizkiy, Yi Liang, Michael Bendersky, Zhangyang Wang, Shiwei Liu
0
0
Large Language Models (LLMs), renowned for their remarkable performance across diverse domains, present a challenge when it comes to practical deployment due to their colossal model size. In response to this challenge, efforts have been directed toward the application of traditional network pruning techniques to LLMs, uncovering a massive number of parameters that can be pruned in one-shot without hurting performance. Prevailing LLM pruning strategies have consistently adhered to the practice of uniformly pruning all layers at equivalent sparsity, resulting in robust performance. However, this observation stands in contrast to the prevailing trends observed in the field of vision models, where non-uniform layerwise sparsity typically yields stronger results. To understand the underlying reasons for this disparity, we conduct a comprehensive study and discover a strong correlation with the emergence of activation outliers in LLMs. Inspired by this finding, we introduce a novel LLM pruning methodology that incorporates a tailored set of non-uniform layerwise sparsity ratios, termed as Outlier Weighed Layerwise sparsity (OWL). The sparsity ratio of OWL is proportional to the outlier ratio observed within each layer, facilitating a more effective alignment between layerwise weight sparsity and outlier ratios. Our empirical evaluation, conducted across the LLaMA-V1 family and OPT, spanning various benchmarks, demonstrates the distinct advantages offered by OWL over previous methods. For instance, OWL exhibits a remarkable performance gain, surpassing the state-of-the-art Wanda and SparseGPT by 61.22 and 6.80 perplexity at a high sparsity level of 70%, respectively, while delivering 2.6x end-to-end inference speed-up in the DeepSparse inference engine. Codes are available at https://github.com/luuyin/OWL.
5/7/2024