LISA: Reasoning Segmentation via Large Language Model
2308.00692
0
0
💬
Abstract
Although perception systems have made remarkable advancements in recent years, they still rely on explicit human instruction or pre-defined categories to identify the target objects before executing visual recognition tasks. Such systems cannot actively reason and comprehend implicit user intention. In this work, we propose a new segmentation task -- reasoning segmentation. The task is designed to output a segmentation mask given a complex and implicit query text. Furthermore, we establish a benchmark comprising over one thousand image-instruction-mask data samples, incorporating intricate reasoning and world knowledge for evaluation purposes. Finally, we present LISA: large Language Instructed Segmentation Assistant, which inherits the language generation capabilities of multimodal Large Language Models (LLMs) while also possessing the ability to produce segmentation masks. We expand the original vocabulary with a token and propose the embedding-as-mask paradigm to unlock the segmentation capability. Remarkably, LISA can handle cases involving complex reasoning and world knowledge. Also, it demonstrates robust zero-shot capability when trained exclusively on reasoning-free datasets. In addition, fine-tuning the model with merely 239 reasoning segmentation data samples results in further performance enhancement. Both quantitative and qualitative experiments show our method effectively unlocks new reasoning segmentation capabilities for multimodal LLMs. Code, models, and data are available at https://github.com/dvlab-research/LISA.
Create account to get full access
Overview
- Recent advances in perception systems still rely on explicit human instruction or pre-defined categories to identify target objects.
- These systems cannot actively reason and comprehend implicit user intentions.
- The paper proposes a new "reasoning segmentation" task, which aims to output a segmentation mask given a complex and implicit query text.
- A benchmark dataset with over one thousand image-instruction-mask samples is established for evaluating reasoning and world knowledge.
- The paper introduces LISA: Large Language Instructed Segmentation Assistant, a model that inherits language generation capabilities of multimodal Large Language Models (LLMs) and can produce segmentation masks.
- LISA expands the original vocabulary with a special token and uses an "embedding-as-mask" paradigm to unlock segmentation capabilities.
Plain English Explanation
Existing computer vision systems can recognize objects in images, but they rely on explicit instructions or predefined categories provided by humans. These systems cannot truly understand the user's underlying intention or reasoning behind their requests.
This research paper proposes a new task called "reasoning segmentation," where the goal is to generate a segmentation mask (an outline of an object) based on a complex, implicit query. For example, the system might be asked to "highlight the largest animal in the room that is not a pet." This requires the model to reason about the contents of the image and understand concepts like size and pet classification.
To test this capability, the researchers created a benchmark dataset with over 1,000 examples of images, instructions, and corresponding segmentation masks. They then developed a new model called LISA (Large Language Instructed Segmentation Assistant) that can handle this reasoning-based segmentation task.
LISA builds on the strengths of large language models, which are excellent at understanding and generating human-like text. The researchers added a special token to LISA's vocabulary and used an "embedding-as-mask" approach to give the model the ability to output segmentation masks. This allows LISA to not only understand complex instructions, but also visually highlight the relevant objects in the image.
The paper demonstrates that LISA is surprisingly capable at this reasoning segmentation task, even when trained on simpler datasets without the complex reasoning component. With just a small amount of fine-tuning on the reasoning-focused benchmark, LISA's performance improves even further.
Technical Explanation
The core innovation of this work is the introduction of the "reasoning segmentation" task, where the goal is to generate a segmentation mask (a pixel-level outline of an object) based on a complex, implicit query text. This goes beyond traditional image segmentation, which typically relies on explicit object categories or human-provided annotations.
To support this new task, the researchers established a benchmark dataset called PARIS3D that contains over 1,000 image-instruction-mask samples. The instructions involve intricate reasoning and world knowledge, such as "highlight the largest animal in the room that is not a pet."
The paper then presents LISA, a model that combines the language generation capabilities of multimodal Large Language Models (LLMs) with the ability to produce segmentation masks. LISA achieves this by expanding its vocabulary with a special token and using an "embedding-as-mask" paradigm. This allows LISA to not only understand the complex reasoning-based instructions, but also generate the corresponding segmentation outputs.
Experiments show that LISA can handle a wide range of reasoning-based segmentation tasks, even when trained exclusively on simpler datasets without the reasoning component. Fine-tuning LISA on just 239 reasoning segmentation samples further boosts its performance.
The paper also discusses potential applications of this technology, such as improving the reasoning behavior of large language models and unlocking new capabilities for multimodal reasoning.
Critical Analysis
The paper presents a compelling approach to expanding the capabilities of perception systems beyond traditional object recognition. By introducing the reasoning segmentation task and the LISA model, the researchers demonstrate the potential for multimodal LLMs to actively reason about complex, implicit user intentions and generate corresponding visual outputs.
However, the paper does not address some potential limitations and areas for further research. For example, the benchmark dataset, while sizeable, may not capture the full breadth of reasoning and world knowledge required for real-world applications. Evaluating LISA's performance on more diverse and challenging datasets would be an important next step.
Additionally, the paper does not delve into the interpretability and transparency of LISA's reasoning process. Understanding how the model arrives at its segmentation outputs, especially for complex queries, would be valuable for building trust and ensuring the safety of such systems.
Finally, the paper focuses on 2D image segmentation, but extending the reasoning segmentation approach to 3D scenes or video could unlock even more powerful applications. Exploring these directions would be an interesting avenue for future research.
Overall, the work presented in this paper represents an important step forward in bridging the gap between language understanding and visual reasoning. By empowering perception systems with the ability to comprehend and act on implicit user intentions, the researchers have laid the groundwork for more intuitive and versatile human-AI interaction.
Conclusion
This research paper introduces a new "reasoning segmentation" task and the LISA model, which can generate segmentation masks based on complex, implicit text instructions. By combining the language understanding capabilities of large language models with the ability to produce visual outputs, LISA demonstrates a significant advancement in the field of multimodal AI.
The establishment of the PARIS3D benchmark dataset and the promising results of LISA's performance, even in zero-shot and few-shot settings, suggest that this approach holds great potential for unlocking new applications in areas like human-robot interaction, image editing, and contextual visual understanding. As the field of multimodal AI continues to evolve, research like this will be crucial in bridging the gap between language and vision, empowering systems to truly comprehend and respond to human intentions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
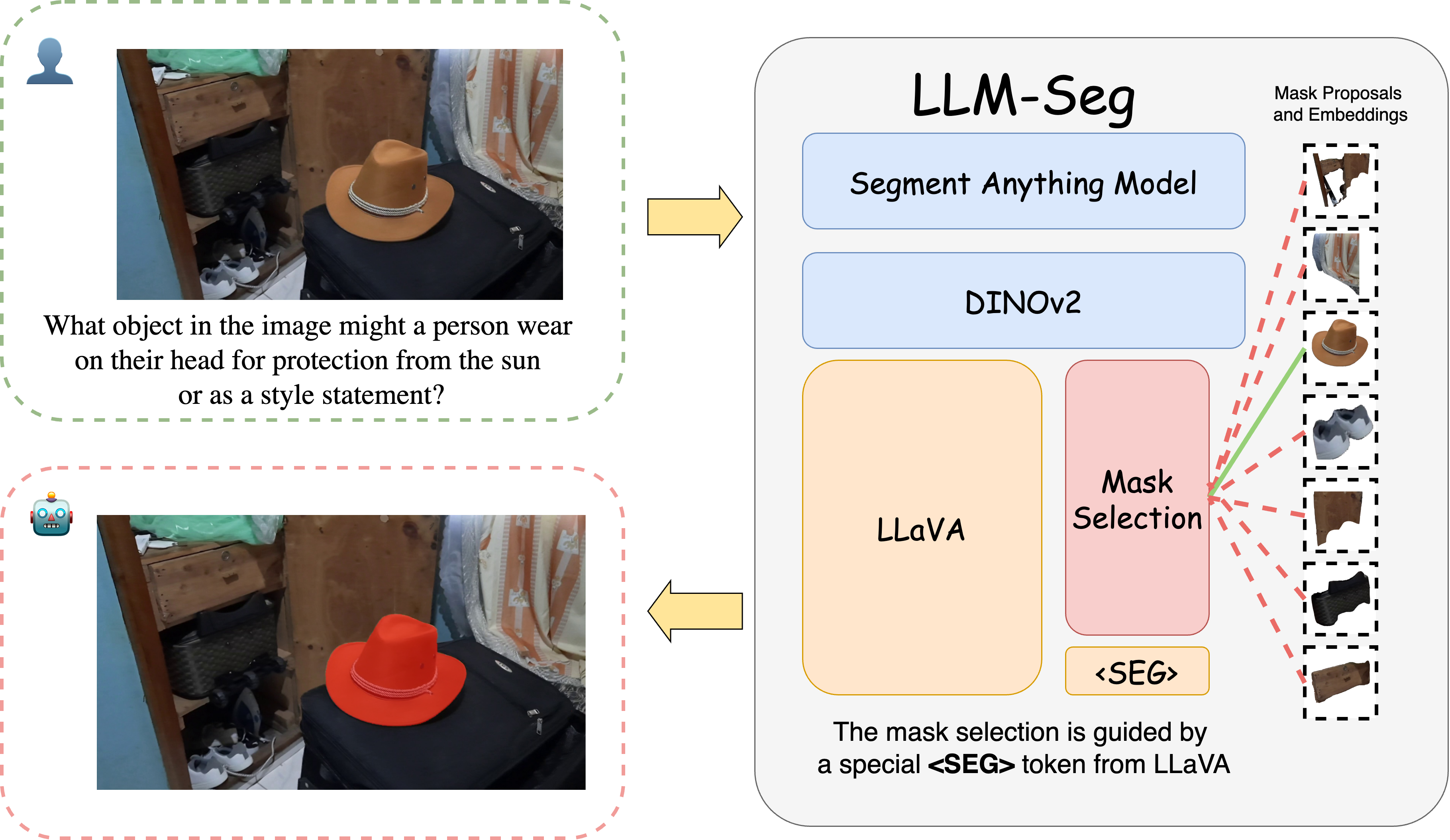
LLM-Seg: Bridging Image Segmentation and Large Language Model Reasoning
Junchi Wang, Lei Ke
0
0
Understanding human instructions to identify the target objects is vital for perception systems. In recent years, the advancements of Large Language Models (LLMs) have introduced new possibilities for image segmentation. In this work, we delve into reasoning segmentation, a novel task that enables segmentation system to reason and interpret implicit user intention via large language model reasoning and then segment the corresponding target. Our work on reasoning segmentation contributes on both the methodological design and dataset labeling. For the model, we propose a new framework named LLM-Seg. LLM-Seg effectively connects the current foundational Segmentation Anything Model and the LLM by mask proposals selection. For the dataset, we propose an automatic data generation pipeline and construct a new reasoning segmentation dataset named LLM-Seg40K. Experiments demonstrate that our LLM-Seg exhibits competitive performance compared with existing methods. Furthermore, our proposed pipeline can efficiently produce high-quality reasoning segmentation datasets. The LLM-Seg40K dataset, developed through this pipeline, serves as a new benchmark for training and evaluating various reasoning segmentation approaches. Our code, models and dataset are at https://github.com/wangjunchi/LLMSeg.
4/16/2024

Reason3D: Searching and Reasoning 3D Segmentation via Large Language Model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, Ming-Hsuan Yang
0
0
Recent advancements in multimodal large language models (LLMs) have shown their potential in various domains, especially concept reasoning. Despite these developments, applications in understanding 3D environments remain limited. This paper introduces Reason3D, a novel LLM designed for comprehensive 3D understanding. Reason3D takes point cloud data and text prompts as input to produce textual responses and segmentation masks, facilitating advanced tasks like 3D reasoning segmentation, hierarchical searching, express referring, and question answering with detailed mask outputs. Specifically, we propose a hierarchical mask decoder to locate small objects within expansive scenes. This decoder initially generates a coarse location estimate covering the object's general area. This foundational estimation facilitates a detailed, coarse-to-fine segmentation strategy that significantly enhances the precision of object identification and segmentation. Experiments validate that Reason3D achieves remarkable results on large-scale ScanNet and Matterport3D datasets for 3D express referring, 3D question answering, and 3D reasoning segmentation tasks. Code and models are available at: https://github.com/KuanchihHuang/Reason3D.
5/28/2024

PARIS3D: Reasoning-based 3D Part Segmentation Using Large Multimodal Model
Amrin Kareem, Jean Lahoud, Hisham Cholakkal
0
0
Recent advancements in 3D perception systems have significantly improved their ability to perform visual recognition tasks such as segmentation. However, these systems still heavily rely on explicit human instruction to identify target objects or categories, lacking the capability to actively reason and comprehend implicit user intentions. We introduce a novel segmentation task known as reasoning part segmentation for 3D objects, aiming to output a segmentation mask based on complex and implicit textual queries about specific parts of a 3D object. To facilitate evaluation and benchmarking, we present a large 3D dataset comprising over 60k instructions paired with corresponding ground-truth part segmentation annotations specifically curated for reasoning-based 3D part segmentation. We propose a model that is capable of segmenting parts of 3D objects based on implicit textual queries and generating natural language explanations corresponding to 3D object segmentation requests. Experiments show that our method achieves competitive performance to models that use explicit queries, with the additional abilities to identify part concepts, reason about them, and complement them with world knowledge. Our source code, dataset, and trained models are available at https://github.com/AmrinKareem/PARIS3D.
4/8/2024
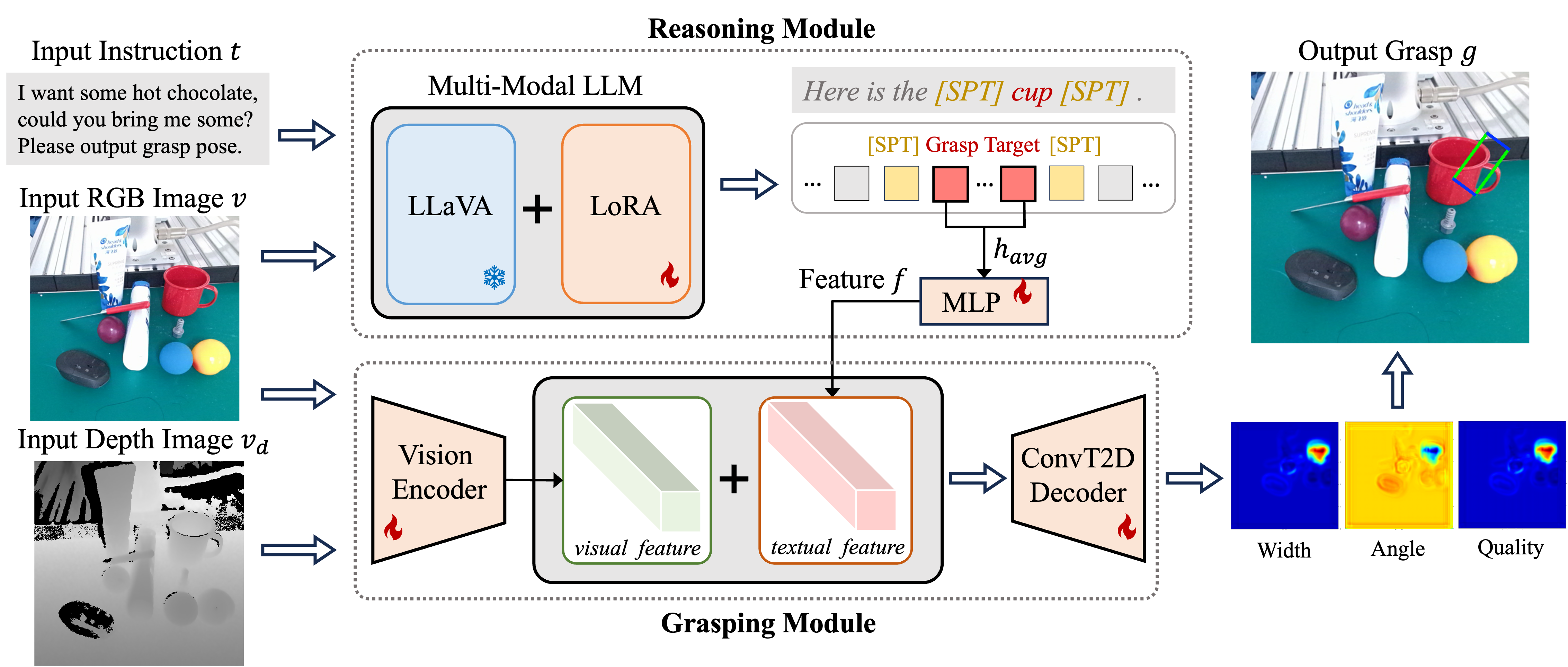
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
0
0
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
4/29/2024