Listen and Move: Improving GANs Coherency in Agnostic Sound-to-Video Generation
2406.16155
0
0

Abstract
Deep generative models have demonstrated the ability to create realistic audiovisual content, sometimes driven by domains of different nature. However, smooth temporal dynamics in video generation is a challenging problem. This work focuses on generic sound-to-video generation and proposes three main features to enhance both image quality and temporal coherency in generative adversarial models: a triple sound routing scheme, a multi-scale residual and dilated recurrent network for extended sound analysis, and a novel recurrent and directional convolutional layer for video prediction. Each of the proposed features improves, in both quality and coherency, the baseline neural architecture typically used in the SoTA, with the video prediction layer providing an extra temporal refinement.
Create account to get full access
Overview
- This paper proposes a novel approach for generating coherent and natural video from audio input, called "Listen and Move".
- The method aims to improve the coherency of Generative Adversarial Networks (GANs) in the context of agnostic sound-to-video generation.
- The authors introduce a new training strategy that leverages the relationship between audio and video to guide the GAN generator, resulting in more realistic and coherent videos.
Plain English Explanation
The paper presents a new way to create videos based on audio input. The key idea is to use the connection between sound and movement to improve the quality and coherence of the generated videos.
Typically, when you generate videos from audio using Generative Adversarial Networks (GANs), the results can look unnatural or disconnected. The "Listen and Move" method tackles this problem by incorporating the relationship between sound and motion into the training process.
This helps the GAN generator produce videos that are more realistic and synchronized with the input audio. For example, if you have an audio clip of someone speaking, the "Listen and Move" approach would generate a video of a person's mouth and face moving in a way that matches the audio, rather than just creating random movements.
By leveraging the inherent connection between sound and visuals, the method can generate more coherent and natural-looking videos compared to previous approaches. This could have applications in areas like video synthesis, animation, and virtual reality, where realistic audio-video synchronization is important.
Technical Explanation
The paper proposes a novel training strategy for Generative Adversarial Networks (GANs) to improve the coherency of agnostic sound-to-video generation. The key idea is to leverage the relationship between audio and video to guide the GAN generator, resulting in more realistic and synchronized videos.
The authors introduce a new discriminator network, called the "Listen and Move Discriminator" (LMD), which evaluates not only the visual quality of the generated video but also its coherence with the input audio. This is achieved by incorporating an audio-video alignment loss into the GAN training objective.
The LMD discriminator is trained to distinguish between real and fake audio-video pairs, while the generator is trained to produce videos that are both visually realistic and well-aligned with the input audio. This "Listen and Move" training strategy encourages the generator to learn the inherent connections between sound and motion, leading to more coherent and natural-looking video generation.
The authors evaluate their approach on several datasets and compare it to existing sound-to-video generation methods, such as SoundCTM and Discriminator-Guided Cooperative Diffusion. The results demonstrate that the "Listen and Move" method outperforms these baselines in terms of both visual quality and audio-video coherence.
Critical Analysis
The paper presents a compelling approach to improving the coherency of sound-to-video generation using GANs. The authors' key insight of leveraging the audio-visual relationship to guide the GAN generator is a promising direction for the field.
One potential limitation of the work is that it focuses on agnostic sound-to-video generation, where the input audio is not directly tied to the visual content. In real-world applications, there may be more specific constraints or prior knowledge about the audio-video relationship that could be incorporated to further enhance the generation quality.
Additionally, the paper does not explore the generalization capabilities of the "Listen and Move" method to different types of audio and video content, such as music-driven animation or audio-visual interaction in virtual environments. Investigating the robustness and adaptability of the approach to diverse scenarios could be an area for future research.
Overall, the "Listen and Move" method represents a significant advancement in the field of audio-visual generation and could have important implications for applications where realistic and coherent audio-video synchronization is crucial.
Conclusion
The "Listen and Move" paper introduces a novel training strategy for Generative Adversarial Networks (GANs) that improves the coherency of agnostic sound-to-video generation. By incorporating the inherent relationship between audio and video into the GAN training process, the method can generate videos that are more realistic and well-aligned with the input audio.
The key contributions of this work include the "Listen and Move Discriminator" (LMD) architecture and the audio-video alignment loss function, which together guide the GAN generator to learn the connections between sound and motion. The results demonstrate that this approach outperforms existing sound-to-video generation methods in terms of both visual quality and audio-video coherence.
This research has the potential to unlock new possibilities in areas such as video synthesis, animation, and virtual reality, where realistic and synchronized audio-visual content is essential. Further exploration of the method's adaptability to diverse audio-video scenarios and its integration with other generative techniques could lead to even more advanced and versatile audio-visual generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
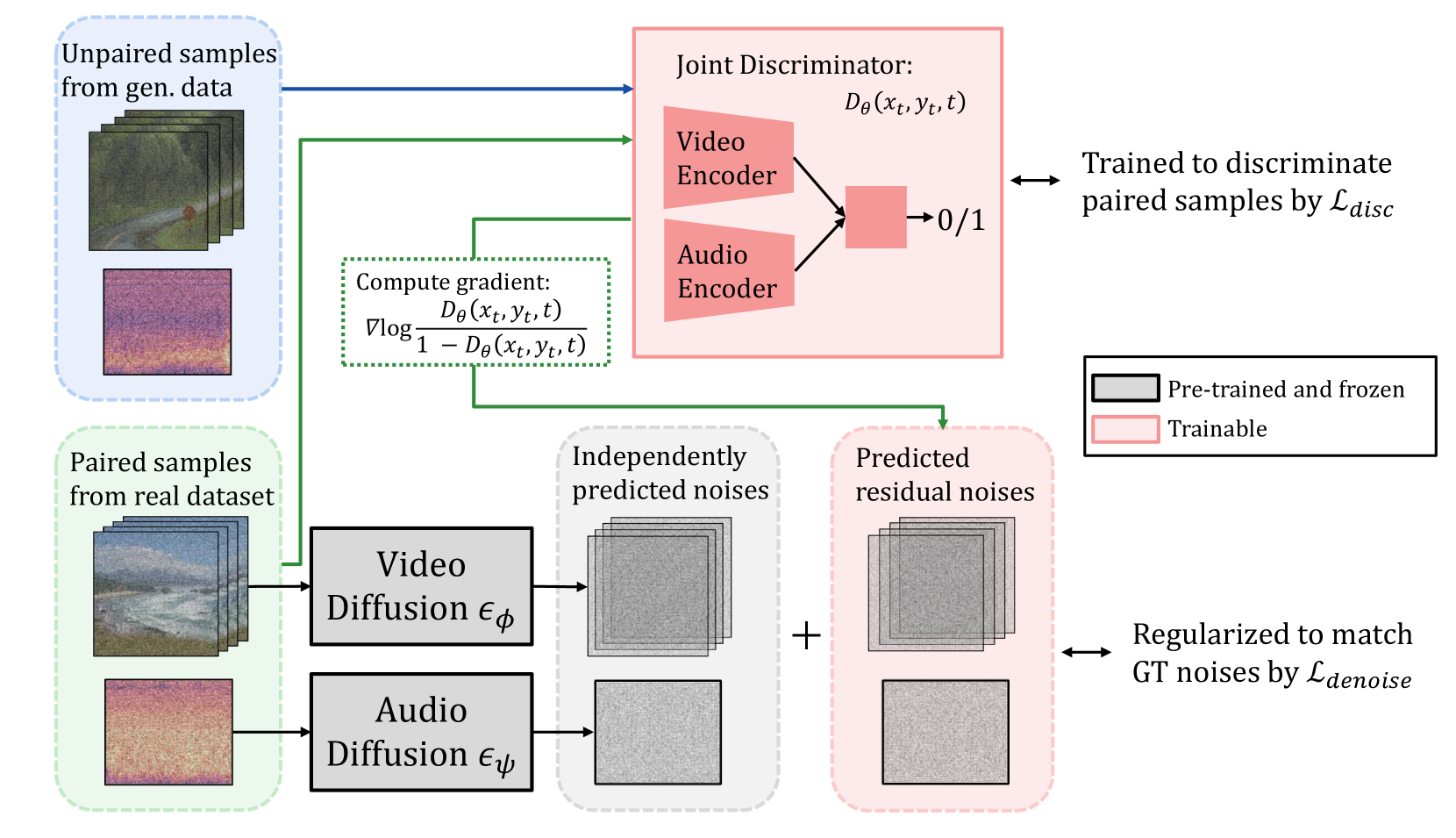
Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
Akio Hayakawa, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In this study, we aim to construct an audio-video generative model with minimal computational cost by leveraging pre-trained single-modal generative models for audio and video. To achieve this, we propose a novel method that guides each single-modal model to cooperatively generate well-aligned samples across modalities. Specifically, given two pre-trained base diffusion models, we train a lightweight joint guidance module to adjust scores separately estimated by the base models to match the score of joint distribution over audio and video. We theoretically show that this guidance can be computed through the gradient of the optimal discriminator distinguishing real audio-video pairs from fake ones independently generated by the base models. On the basis of this analysis, we construct the joint guidance module by training this discriminator. Additionally, we adopt a loss function to make the gradient of the discriminator work as a noise estimator, as in standard diffusion models, stabilizing the gradient of the discriminator. Empirical evaluations on several benchmark datasets demonstrate that our method improves both single-modal fidelity and multi-modal alignment with a relatively small number of parameters.
5/29/2024

SoundCTM: Uniting Score-based and Consistency Models for Text-to-Sound Generation
Koichi Saito, Dongjun Kim, Takashi Shibuya, Chieh-Hsin Lai, Zhi Zhong, Yuhta Takida, Yuki Mitsufuji
0
0
Sound content is an indispensable element for multimedia works such as video games, music, and films. Recent high-quality diffusion-based sound generation models can serve as valuable tools for the creators. However, despite producing high-quality sounds, these models often suffer from slow inference speeds. This drawback burdens creators, who typically refine their sounds through trial and error to align them with their artistic intentions. To address this issue, we introduce Sound Consistency Trajectory Models (SoundCTM). Our model enables flexible transitioning between high-quality 1-step sound generation and superior sound quality through multi-step generation. This allows creators to initially control sounds with 1-step samples before refining them through multi-step generation. While CTM fundamentally achieves flexible 1-step and multi-step generation, its impressive performance heavily depends on an additional pretrained feature extractor and an adversarial loss, which are expensive to train and not always available in other domains. Thus, we reframe CTM's training framework and introduce a novel feature distance by utilizing the teacher's network for a distillation loss. Additionally, while distilling classifier-free guided trajectories, we train conditional and unconditional student models simultaneously and interpolate between these models during inference. We also propose training-free controllable frameworks for SoundCTM, leveraging its flexible sampling capability. SoundCTM achieves both promising 1-step and multi-step real-time sound generation without using any extra off-the-shelf networks. Furthermore, we demonstrate SoundCTM's capability of controllable sound generation in a training-free manner. Our codes, pretrained models, and audio samples are available at https://github.com/sony/soundctm.
6/12/2024
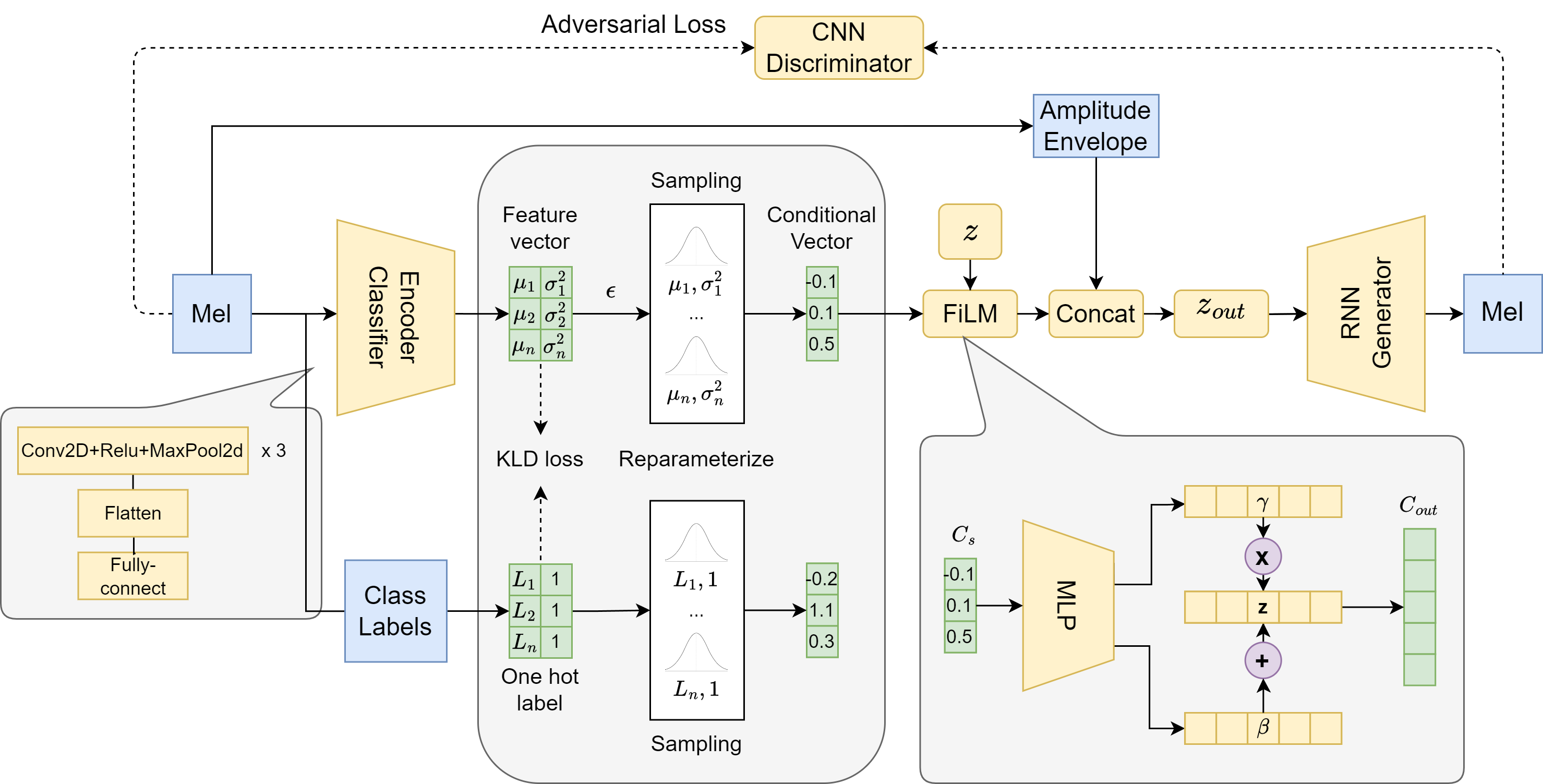
ICGAN: An implicit conditioning method for interpretable feature control of neural audio synthesis
Yunyi Liu, Craig Jin
0
0
Neural audio synthesis methods can achieve high-fidelity and realistic sound generation by utilizing deep generative models. Such models typically rely on external labels which are often discrete as conditioning information to achieve guided sound generation. However, it remains difficult to control the subtle changes in sounds without appropriate and descriptive labels, especially given a limited dataset. This paper proposes an implicit conditioning method for neural audio synthesis using generative adversarial networks that allows for interpretable control of the acoustic features of synthesized sounds. Our technique creates a continuous conditioning space that enables timbre manipulation without relying on explicit labels. We further introduce an evaluation metric to explore controllability and demonstrate that our approach is effective in enabling a degree of controlled variation of different synthesized sound effects for in-domain and cross-domain sounds.
6/12/2024
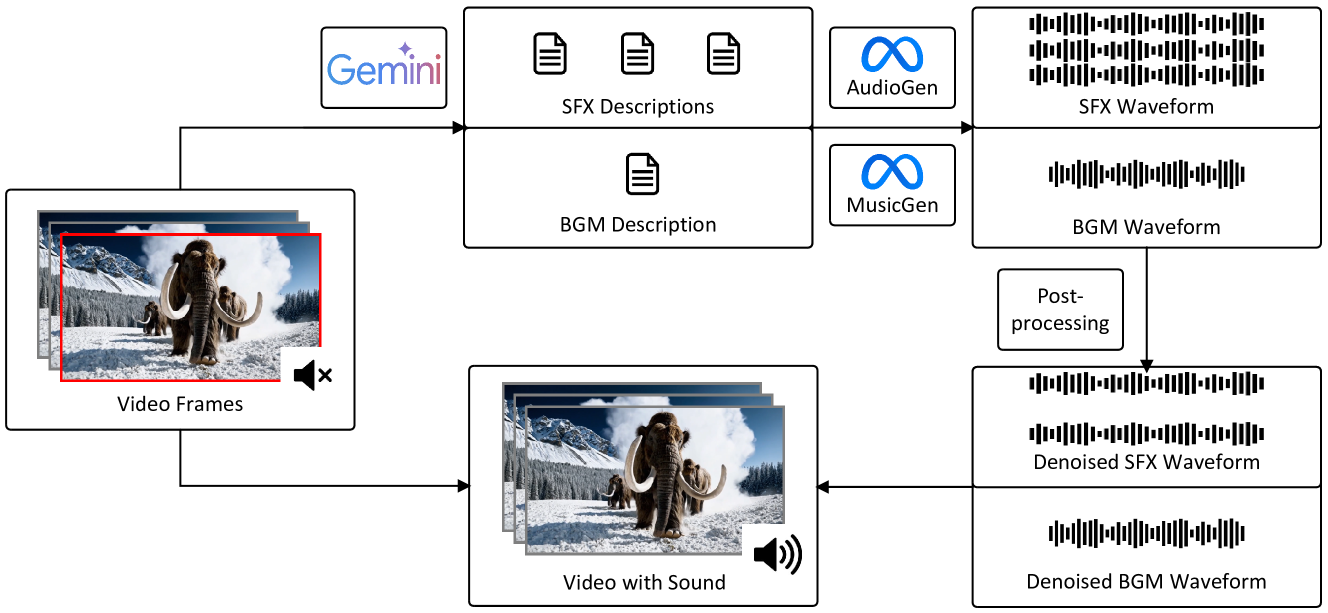
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
0
0
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
4/29/2024