Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
2405.17842
0
0
Abstract
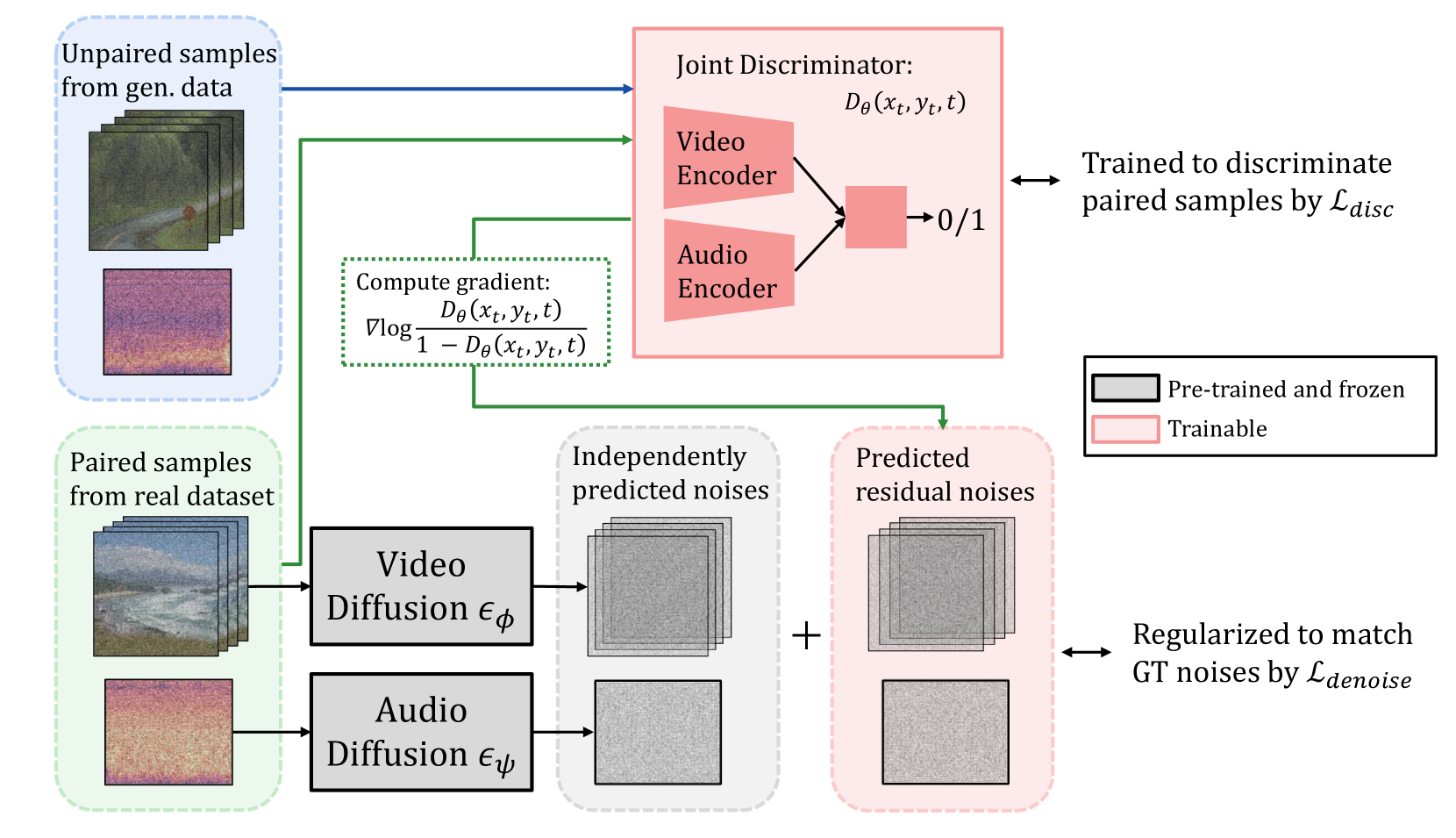
In this study, we aim to construct an audio-video generative model with minimal computational cost by leveraging pre-trained single-modal generative models for audio and video. To achieve this, we propose a novel method that guides each single-modal model to cooperatively generate well-aligned samples across modalities. Specifically, given two pre-trained base diffusion models, we train a lightweight joint guidance module to adjust scores separately estimated by the base models to match the score of joint distribution over audio and video. We theoretically show that this guidance can be computed through the gradient of the optimal discriminator distinguishing real audio-video pairs from fake ones independently generated by the base models. On the basis of this analysis, we construct the joint guidance module by training this discriminator. Additionally, we adopt a loss function to make the gradient of the discriminator work as a noise estimator, as in standard diffusion models, stabilizing the gradient of the discriminator. Empirical evaluations on several benchmark datasets demonstrate that our method improves both single-modal fidelity and multi-modal alignment with a relatively small number of parameters.
Create account to get full access
Overview
• This paper presents a novel method called Discriminator-Guided Cooperative Diffusion (DGCD) for jointly generating audio and video content.
• The approach uses a discriminator network to guide the diffusion process, allowing for more coherent and realistic audiovisual generation compared to previous methods.
• The paper also introduces a novel dataset for audiovisual generation and demonstrates the effectiveness of DGCD through extensive experiments.
Plain English Explanation
The researchers have developed a new way to create audio and video content together, rather than producing them separately. Their method, called Discriminator-Guided Cooperative Diffusion (DGCD), uses a special type of neural network called a "discriminator" to help guide the process of generating the audio and video in a more coherent and realistic way.
Typically, audio and video have been generated independently, which can result in mismatches or inconsistencies between the two. The DGCD approach aims to address this by allowing the audio and video generation to influence each other during the creation process. The discriminator network acts as a kind of "quality control" mechanism, providing feedback to ensure the final audiovisual output is more seamless and believable.
The researchers also created a new dataset specifically for this task, which they use to train and test their DGCD model. Through their experiments, they demonstrate that DGCD can outperform previous methods in generating high-quality, synchronized audio and video.
Technical Explanation
The key innovation in this paper is the Discriminator-Guided Cooperative Diffusion (DGCD) approach for joint audio and video generation. The method uses a diffusion model, which is a type of generative model that learns to add and remove noise from data in a controlled way to generate new samples.
In DGCD, the audio and video diffusion processes are guided by a discriminator network that evaluates the coherence and realism of the generated audiovisual content. This discriminator feedback is used to steer the diffusion of both the audio and video streams, allowing them to influence each other during generation.
The paper also introduces a new audiovisual dataset, which the authors use to train and evaluate their DGCD model. Experiments show that DGCD outperforms previous approaches in terms of audiovisual quality, as measured by both objective metrics and human evaluation.
Critical Analysis
The DGCD approach represents an interesting advance in the field of joint audio and video generation. By incorporating a discriminator to provide feedback during the diffusion process, the method is able to generate more coherent and realistic audiovisual content compared to previous techniques.
However, the paper does not explore some potential limitations or areas for further research. For example, the dataset used is relatively small, and it's unclear how well the DGCD model would scale to larger or more diverse audiovisual data. Additionally, the paper does not delve into the computational complexity or training time of the DGCD approach, which could be important considerations for real-world applications.
It would also be valuable to see how DGCD compares to other multimodal generation techniques, such as those based on Versatile Diffusion Transformer, SonicDiffusion, or HydiscGAN. Exploring the relative strengths and weaknesses of these different approaches could provide important insights for advancing the state of the art in this area.
Conclusion
This paper introduces a novel method called Discriminator-Guided Cooperative Diffusion (DGCD) for joint audio and video generation. By using a discriminator network to guide the diffusion process, DGCD is able to generate more coherent and realistic audiovisual content compared to previous techniques.
The researchers' work highlights the potential benefits of incorporating multimodal feedback and interaction during the generative process. Their findings could have important implications for a range of applications, from virtual avatars and interactive media to improving multimodal learning through multi-loss gradient modulation and weakly supervised audio separation.
As the field of generative AI continues to advance, techniques like DGCD that can seamlessly combine multiple modalities will likely become increasingly important for creating engaging and immersive experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, Brendan Jou, Jos'e Lezama, Agrim Gupta, Lijun Yu, Lu Jiang, Aren Jansen, Jacob Walker, Krishna Somandepalli
0
0
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
5/24/2024

SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models
Burak Can Biner, Farrin Marouf Sofian, Umur Berkay Karakac{s}, Duygu Ceylan, Erkut Erdem, Aykut Erdem
0
0
We are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. While spatial control using cues such as depth, sketch, and other images has attracted a lot of research, we argue that another equally effective modality is audio since sound and sight are two main components of human perception. Hence, we propose a method to enable audio-conditioning in large scale image diffusion models. Our method first maps features obtained from audio clips to tokens that can be injected into the diffusion model in a fashion similar to text tokens. We introduce additional audio-image cross attention layers which we finetune while freezing the weights of the original layers of the diffusion model. In addition to audio conditioned image generation, our method can also be utilized in conjuction with diffusion based editing methods to enable audio conditioned image editing. We demonstrate our method on a wide range of audio and image datasets. We perform extensive comparisons with recent methods and show favorable performance.
5/3/2024

HyDiscGAN: A Hybrid Distributed cGAN for Audio-Visual Privacy Preservation in Multimodal Sentiment Analysis
Zhuojia Wu, Qi Zhang, Duoqian Miao, Kun Yi, Wei Fan, Liang Hu
0
0
Multimodal Sentiment Analysis (MSA) aims to identify speakers' sentiment tendencies in multimodal video content, raising serious concerns about privacy risks associated with multimodal data, such as voiceprints and facial images. Recent distributed collaborative learning has been verified as an effective paradigm for privacy preservation in multimodal tasks. However, they often overlook the privacy distinctions among different modalities, struggling to strike a balance between performance and privacy preservation. Consequently, it poses an intriguing question of maximizing multimodal utilization to improve performance while simultaneously protecting necessary modalities. This paper forms the first attempt at modality-specified (i.e., audio and visual) privacy preservation in MSA tasks. We propose a novel Hybrid Distributed cross-modality cGAN framework (HyDiscGAN), which learns multimodality alignment to generate fake audio and visual features conditioned on shareable de-identified textual data. The objective is to leverage the fake features to approximate real audio and visual content to guarantee privacy preservation while effectively enhancing performance. Extensive experiments show that compared with the state-of-the-art MSA model, HyDiscGAN can achieve superior or competitive performance while preserving privacy.
4/19/2024
📈
Improving Multimodal Learning with Multi-Loss Gradient Modulation
Konstantinos Kontras, Christos Chatzichristos, Matthew Blaschko, Maarten De Vos
0
0
Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
5/14/2024