Lite-Mind: Towards Efficient and Robust Brain Representation Network
2312.03781
0
0
Abstract
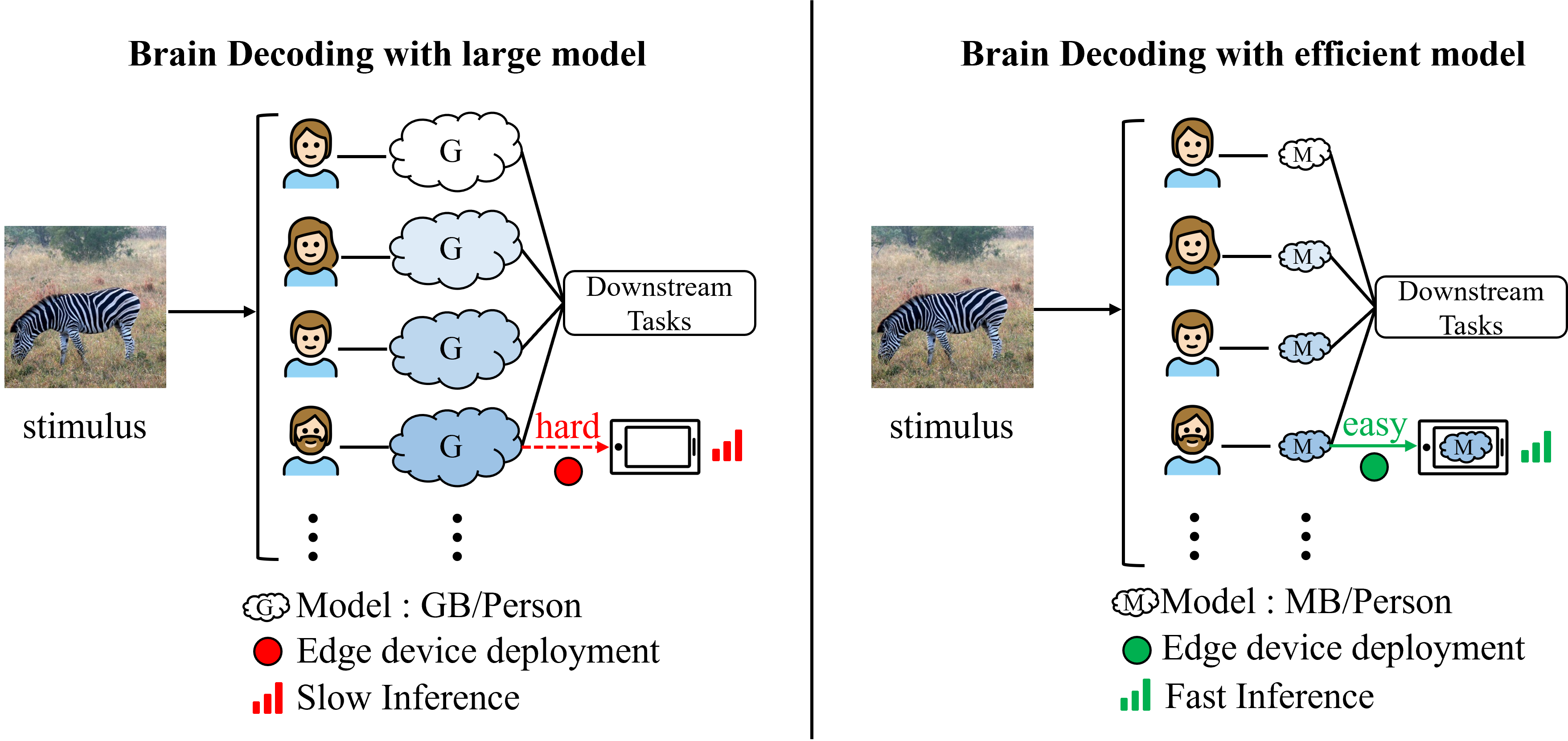
The limited data availability and the low signal-to-noise ratio of fMRI signals lead to the challenging task of fMRI-to-image retrieval. State-of-the-art MindEye remarkably improves fMRI-to-image retrieval performance by leveraging a large model, i.e., a 996M MLP Backbone per subject, to align fMRI embeddings to the final hidden layer of CLIP's Vision Transformer (ViT). However, significant individual variations exist among subjects, even under identical experimental setups, mandating the training of large subject-specific models. The substantial parameters pose significant challenges in deploying fMRI decoding on practical devices. To this end, we propose Lite-Mind, a lightweight, efficient, and robust brain representation learning paradigm based on Discrete Fourier Transform (DFT), which efficiently aligns fMRI voxels to fine-grained information of CLIP. We elaborately design a DFT backbone with Spectrum Compression and Frequency Projector modules to learn informative and robust voxel embeddings. Our experiments demonstrate that Lite-Mind achieves an impressive 94.6% fMRI-to-image retrieval accuracy on the NSD dataset for Subject 1, with 98.7% fewer parameters than MindEye. Lite-Mind is also proven to be able to be migrated to smaller fMRI datasets and establishes a new state-of-the-art for zero-shot classification on the GOD dataset.
Create account to get full access
Overview
- This paper introduces Lite-Mind, an efficient and versatile brain representation network for decoding visual information from brain signals.
- Lite-Mind aims to address the challenges of existing brain decoding approaches, such as high computational complexity and limited cross-subject generalization.
- The proposed model leverages a lightweight architecture and task-agnostic training to enable efficient and robust visual decoding across different subjects and tasks.
Plain English Explanation
The human brain is an incredibly complex and fascinating organ, capable of processing a vast amount of information from our senses. Researchers have long been interested in understanding how the brain represents and processes visual information, with the ultimate goal of being able to decode or "read" this information directly from brain signals.
Lite-Mind: Towards Efficient and Versatile Brain Representation Network introduces a new approach called Lite-Mind that aims to make this brain decoding process more efficient and versatile. The key idea is to develop a lightweight neural network architecture that can effectively extract and represent visual information from brain signals, while also being able to generalize across different individuals and tasks.
This is an important advancement because existing brain decoding approaches often struggle with high computational complexity and limited cross-subject performance. Lite-Mind addresses these challenges by using a more efficient network design and a training strategy that allows the model to learn task-agnostic visual representations, rather than being tied to a specific task or dataset.
Technical Explanation
The Lite-Mind architecture is built around a lightweight convolutional neural network (CNN) that takes brain signals (e.g., electroencephalography or functional magnetic resonance imaging data) as input and outputs a visual representation. The key innovations of Lite-Mind include:
-
Efficient Network Design: Lite-Mind employs a streamlined CNN architecture with fewer parameters and layers compared to traditional brain decoding models. This reduces the computational resources required for training and inference, making the system more practical for real-world applications.
-
Task-Agnostic Training: Instead of training the model on a specific visual decoding task, Lite-Mind is trained in a more general, task-agnostic manner. This allows the model to learn versatile visual representations that can be effectively applied to a wide range of decoding tasks, rather than being limited to a single task or dataset.
-
Cross-Subject Generalization: By training Lite-Mind in a task-agnostic manner, the model is able to generalize better to new subjects, overcoming the common challenge of limited cross-subject performance in brain decoding research. This makes Lite-Mind a more robust and practical solution for real-world applications.
The paper presents extensive experiments evaluating the performance of Lite-Mind on various brain decoding tasks, including image classification, image reconstruction, and cross-subject visual decoding. The results demonstrate that Lite-Mind outperforms state-of-the-art brain decoding models in terms of both efficiency and versatility, making it a promising approach for advancing the field of brain-computer interfaces and neural representation learning.
Critical Analysis
The Lite-Mind paper presents a well-designed and thoughtful approach to addressing the challenges of existing brain decoding models. The authors have effectively identified the key limitations of current systems, such as high computational complexity and limited cross-subject generalization, and have proposed a solution that directly targets these issues.
One potential area for further research is the exploration of even more efficient network architectures and training strategies. While Lite-Mind already represents a significant improvement in efficiency, there may be room for further optimization, especially as hardware constraints and real-world deployment scenarios become more demanding.
Additionally, the paper could have provided more in-depth discussion of the potential limitations or failure modes of the Lite-Mind approach. For example, it would be interesting to understand the types of visual tasks or brain signal characteristics that might pose challenges for the model, and how the authors might address these limitations in future work.
Overall, the Lite-Mind paper makes a valuable contribution to the field of brain-computer interfaces and neural representation learning. The proposed approach offers a promising path forward for developing efficient and versatile brain decoding systems that can be more widely adopted and applied in real-world settings.
Conclusion
The Lite-Mind paper presents a novel and efficient brain representation network that addresses key limitations of existing brain decoding models. By leveraging a lightweight architecture and task-agnostic training, Lite-Mind demonstrates improved performance in terms of computational efficiency and cross-subject generalization, making it a promising step towards more practical and versatile brain-computer interfaces.
This research has important implications for the development of advanced neural decoding systems, which could enable a wide range of applications, from assistive technology for individuals with disabilities to the study of human cognition and perception. As the field of brain-computer interfaces continues to evolve, the Lite-Mind approach offers a valuable contribution that can help drive the development of more efficient and robust brain decoding solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Paul S. Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A. Norman, Tanishq Mathew Abraham
0
0
Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
6/18/2024
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
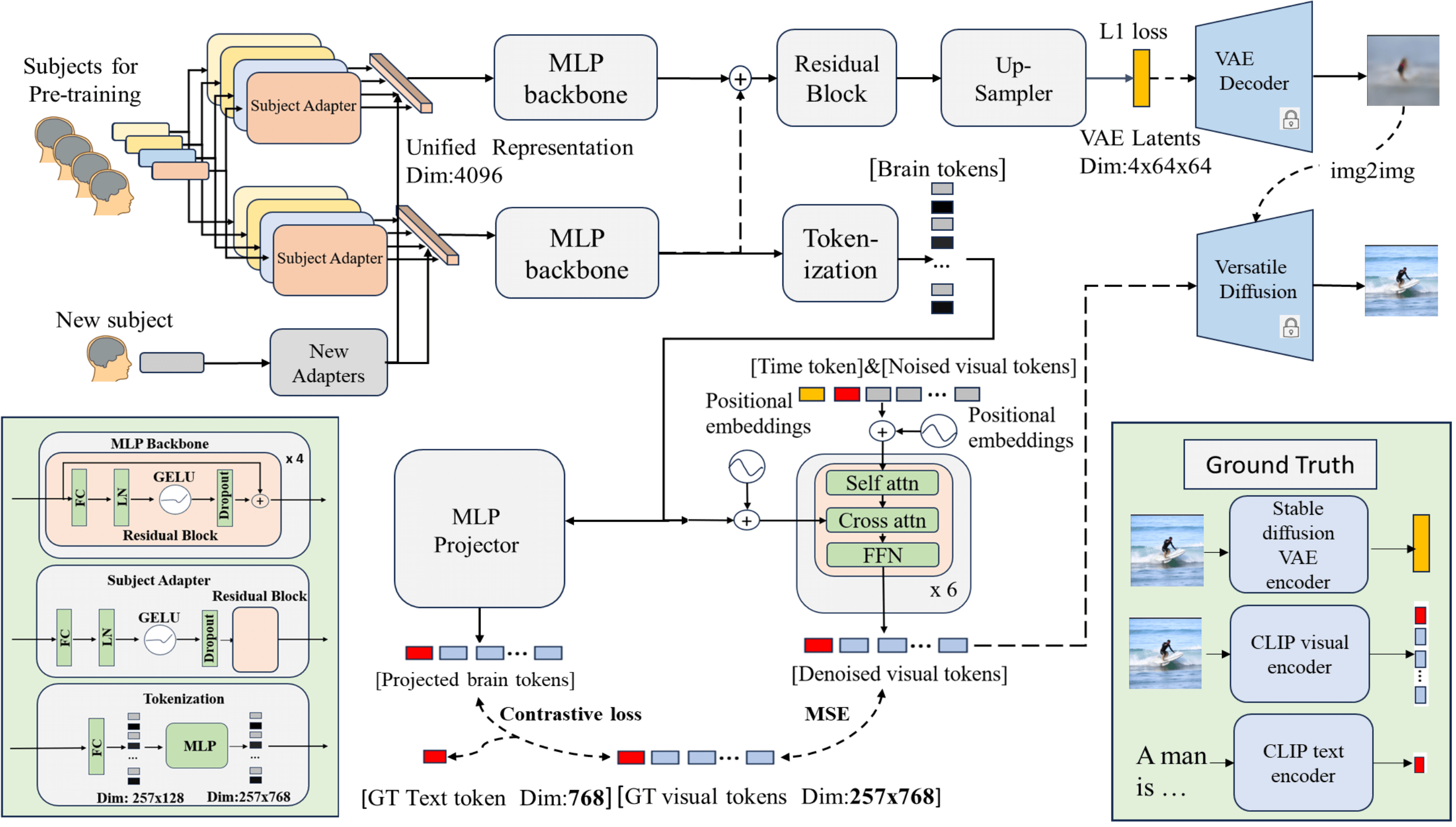
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024

MindFormer: A Transformer Architecture for Multi-Subject Brain Decoding via fMRI
Inhwa Han, Jaayeon Lee, Jong Chul Ye
0
0
Research efforts to understand neural signals have been ongoing for many years, with visual decoding from fMRI signals attracting considerable attention. Particularly, the advent of image diffusion models has advanced the reconstruction of images from fMRI data significantly. However, existing approaches often introduce inter- and intra- subject variations in the reconstructed images, which can compromise accuracy. To address current limitations in multi-subject brain decoding, we introduce a new Transformer architecture called MindFormer. This model is specifically designed to generate fMRI-conditioned feature vectors that can be used for conditioning Stable Diffusion model. More specifically, MindFormer incorporates two key innovations: 1) a novel training strategy based on the IP-Adapter to extract semantically meaningful features from fMRI signals, and 2) a subject specific token and linear layer that effectively capture individual differences in fMRI signals while synergistically combines multi subject fMRI data for training. Our experimental results demonstrate that Stable Diffusion, when integrated with MindFormer, produces semantically consistent images across different subjects. This capability significantly surpasses existing models in multi-subject brain decoding. Such advancements not only improve the accuracy of our reconstructions but also deepen our understanding of neural processing variations among individuals.
5/29/2024
MindShot: Brain Decoding Framework Using Only One Image
Shuai Jiang, Zhu Meng, Delong Liu, Haiwen Li, Fei Su, Zhicheng Zhao
0
0
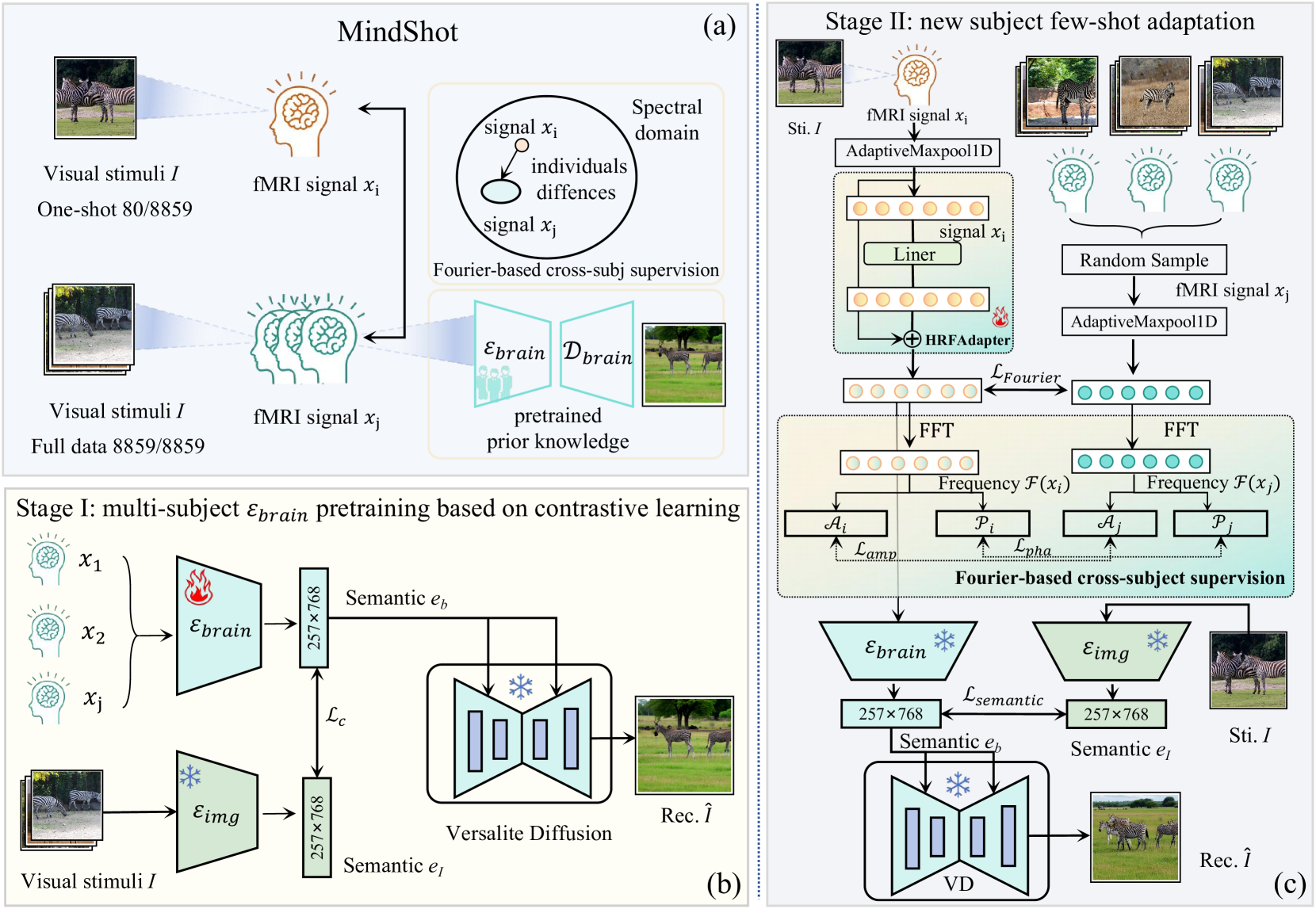
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
5/27/2024