MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
2403.11207
77
0

Abstract
Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
Create account to get full access
Overview
- Presents a new deep learning model called MindEye2 that can translate fMRI brain scans into images
- Demonstrates the ability to generate accurate images from just 1 hour of brain scan data, a significant improvement over prior work
- Introduces the concept of "shared-subject models" that leverage data from multiple individuals to improve performance
Plain English Explanation
MindEye2 is a deep learning system that can interpret brain scans from functional magnetic resonance imaging (fMRI) and generate corresponding visual images. This is an exciting capability, as it allows us to see what people are imagining or perceiving in their minds.
Previous attempts at "mind-reading" through brain decoding required hours or even days of fMRI data to produce useful results. However, the researchers behind MindEye2 have developed a new approach that can generate accurate images from just 1 hour of brain scan data. This is a significant improvement in efficiency and could make brain-to-image translation much more practical for real-world applications.
The key innovation in MindEye2 is the use of "shared-subject models" - models that are trained on data from multiple individuals, rather than just a single person. By leveraging common patterns across brains, the system is able to extract more useful information from limited data and produce higher quality image reconstructions. This builds on prior work like Lite-Mind and MindShot that have explored shared brain representations.
Overall, MindEye2 represents an important step forward in the field of computational neuroscience and "mind reading" technology. By making brain-to-image translation more efficient and effective, it opens up new possibilities for how we can interface with and understand the human mind.
Technical Explanation
The key innovation in MindEye2 is the use of "shared-subject models" - neural network architectures that are trained on fMRI data from multiple individuals, rather than a single person. This allows the model to learn common patterns and representations across brains, which improves its ability to generate accurate image reconstructions from limited data.
Specifically, the MindEye2 model consists of an encoder network that maps fMRI scans to a shared latent space, and a decoder network that translates those latent representations into visual images. The shared-subject training approach means that the encoder can effectively extract salient features from brain activity across a diverse set of individuals.
The researchers demonstrate the effectiveness of this approach by training MindEye2 on just 1 hour of fMRI data per subject, which is a significant reduction from prior work that required hours or days of brain scan data. Despite this limited input, MindEye2 is able to generate remarkably detailed and accurate image reconstructions, outperforming previous state-of-the-art brain-to-image models.
Critical Analysis
While the results presented in this paper are impressive, there are a few important caveats to consider. First, the experiments were conducted on a relatively small sample size of just 4 individuals. Scaling this approach to larger and more diverse populations will be an important next step to truly evaluate its generalization capabilities.
Additionally, the paper does not provide much insight into the specific brain representations and computations that are being leveraged by the shared-subject model. A deeper understanding of the underlying neuroscience principles at play could lead to further innovations and refinements of the MindEye2 architecture.
Finally, there are important ethical considerations around the development of "mind-reading" technologies like this. While the potential applications in fields like neuroAI and computational neuroscience are exciting, care must be taken to ensure these systems are developed and deployed responsibly, with strong safeguards around privacy and consent.
Conclusion
Overall, the MindEye2 system represents a significant advance in the field of brain-to-image translation. By leveraging shared representations across multiple individuals, the model is able to generate high-quality image reconstructions from just 1 hour of fMRI data - a major improvement in efficiency over prior work.
This breakthrough has important implications for our understanding of the human brain and how it encodes and processes visual information. It also opens up new possibilities for brain-computer interfaces and assistive technologies that can help people express their internal mental states.
As the field of computational neuroscience continues to advance, innovations like MindEye2 will be crucial for unlocking the mysteries of the mind and developing more seamless and intuitive ways for humans to interact with machines.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
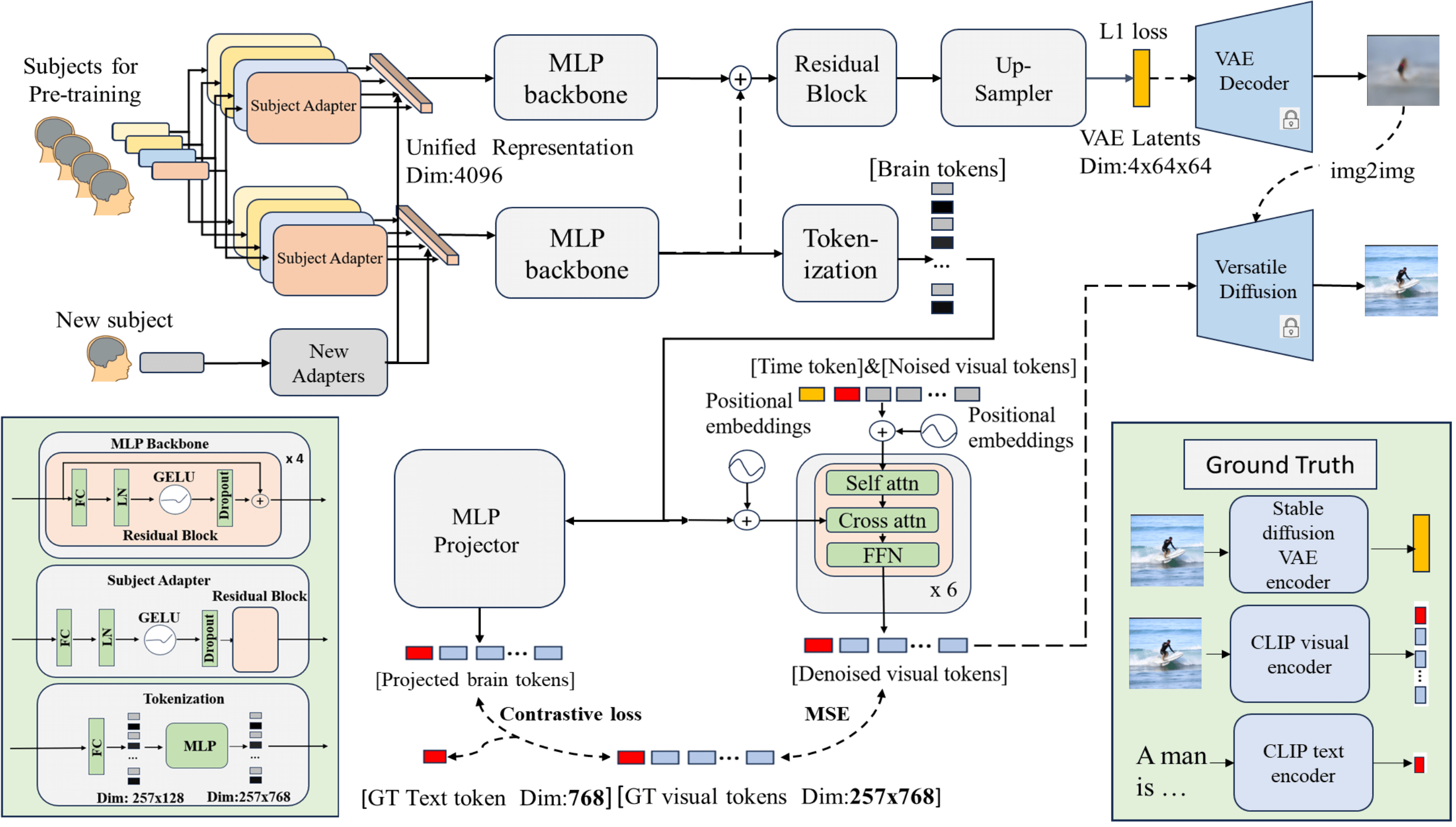
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024
Lite-Mind: Towards Efficient and Robust Brain Representation Network
Zixuan Gong, Qi Zhang, Guangyin Bao, Lei Zhu, Yu Zhang, Ke Liu, Liang Hu, Duoqian Miao
0
0
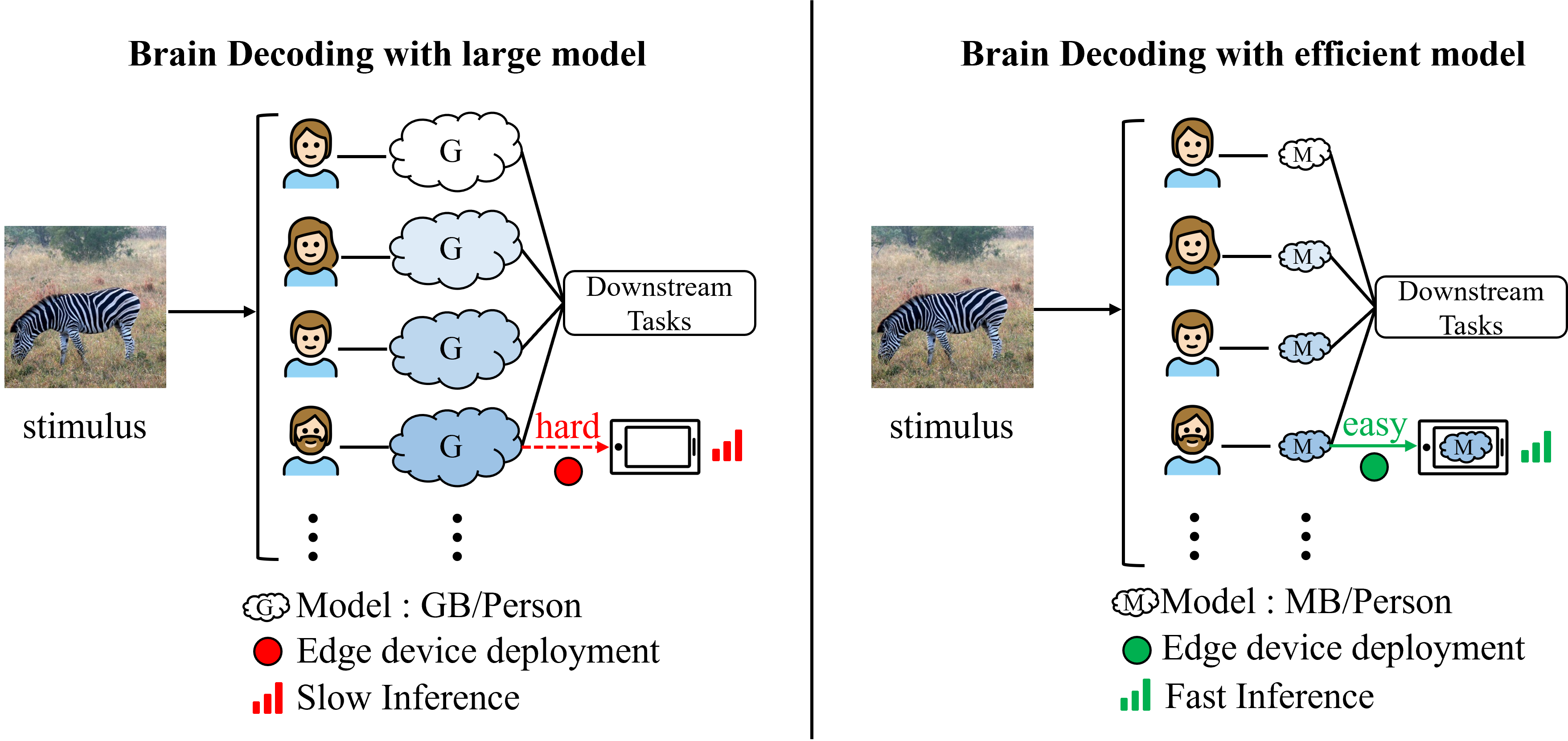
The limited data availability and the low signal-to-noise ratio of fMRI signals lead to the challenging task of fMRI-to-image retrieval. State-of-the-art MindEye remarkably improves fMRI-to-image retrieval performance by leveraging a large model, i.e., a 996M MLP Backbone per subject, to align fMRI embeddings to the final hidden layer of CLIP's Vision Transformer (ViT). However, significant individual variations exist among subjects, even under identical experimental setups, mandating the training of large subject-specific models. The substantial parameters pose significant challenges in deploying fMRI decoding on practical devices. To this end, we propose Lite-Mind, a lightweight, efficient, and robust brain representation learning paradigm based on Discrete Fourier Transform (DFT), which efficiently aligns fMRI voxels to fine-grained information of CLIP. We elaborately design a DFT backbone with Spectrum Compression and Frequency Projector modules to learn informative and robust voxel embeddings. Our experiments demonstrate that Lite-Mind achieves an impressive 94.6% fMRI-to-image retrieval accuracy on the NSD dataset for Subject 1, with 98.7% fewer parameters than MindEye. Lite-Mind is also proven to be able to be migrated to smaller fMRI datasets and establishes a new state-of-the-art for zero-shot classification on the GOD dataset.
4/22/2024
MindShot: Brain Decoding Framework Using Only One Image
Shuai Jiang, Zhu Meng, Delong Liu, Haiwen Li, Fei Su, Zhicheng Zhao
0
0
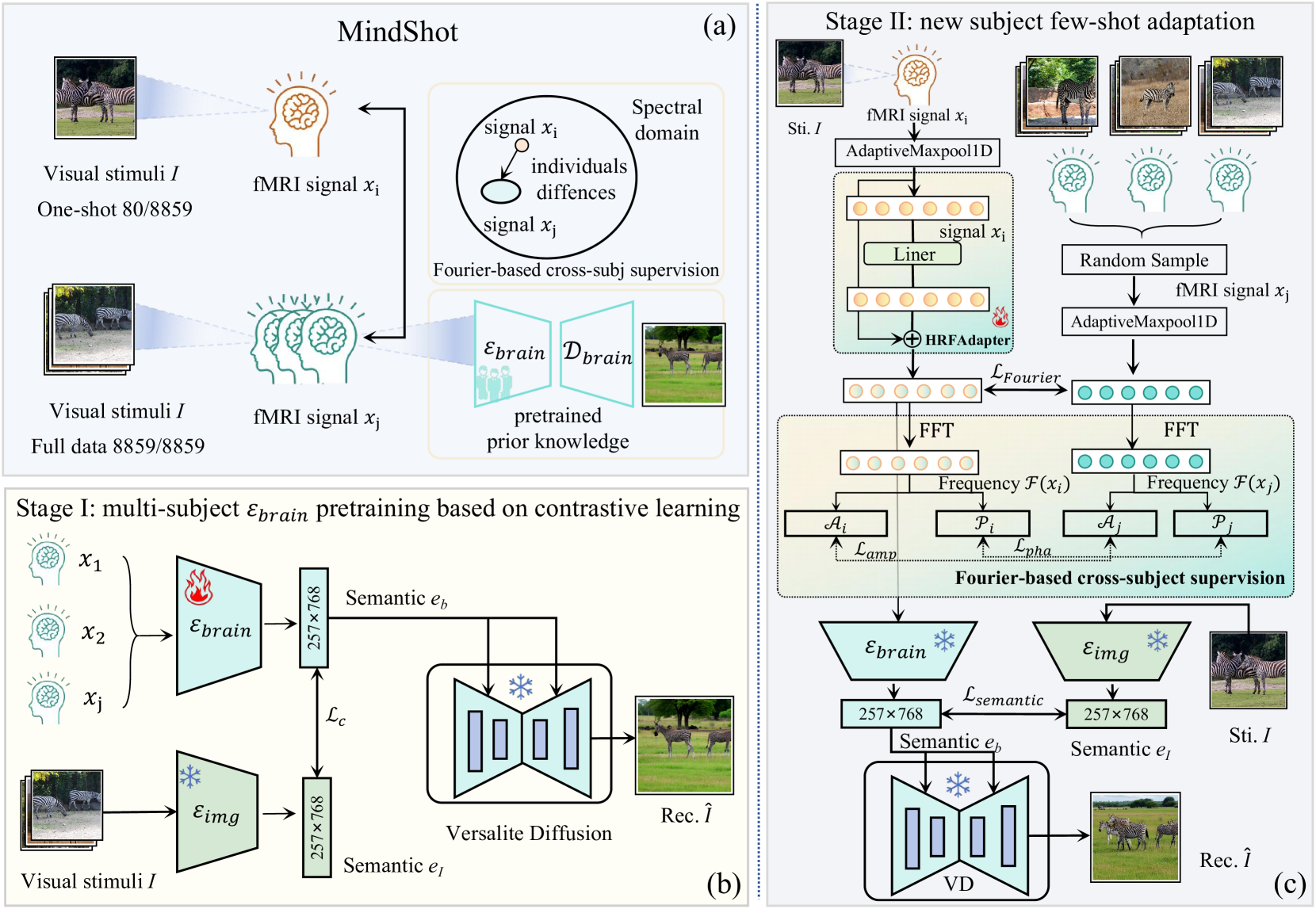
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
5/27/2024

Mind-to-Image: Projecting Visual Mental Imagination of the Brain from fMRI
Hugo Caselles-Dupr'e, Charles Mellerio, Paul H'erent, Aliz'ee Lopez-Persem, Benoit B'eranger, Mathieu Soularue, Pierre Fautrel, Gauthier Vernier, Matthieu Cord
0
0
The reconstruction of images observed by subjects from fMRI data collected during visual stimuli has made strong progress in the past decade, thanks to the availability of extensive fMRI datasets and advancements in generative models for image generation. However, the application of visual reconstruction has remained limited. Reconstructing visual imagination presents a greater challenge, with potentially revolutionary applications ranging from aiding individuals with disabilities to verifying witness accounts in court. The primary hurdles in this field are the absence of data collection protocols for visual imagery and the lack of datasets on the subject. Traditionally, fMRI-to-image relies on data collected from subjects exposed to visual stimuli, which poses issues for generating visual imagery based on the difference of brain activity between visual stimulation and visual imagery. For the first time, we have compiled a substantial dataset (around 6h of scans) on visual imagery along with a proposed data collection protocol. We then train a modified version of an fMRI-to-image model and demonstrate the feasibility of reconstructing images from two modes of imagination: from memory and from pure imagination. The resulting pipeline we call Mind-to-Image marks a step towards creating a technology that allow direct reconstruction of visual imagery.
5/29/2024