Literary and Colloquial Dialect Identification for Tamil using Acoustic Features

0
Sign in to get full access
Overview
- This paper explores the use of acoustic features to identify literary and colloquial dialects in the Tamil language.
- The researchers developed a machine learning model to classify spoken Tamil into literary or colloquial forms based on acoustic characteristics.
- The model was trained and evaluated on a dataset of Tamil speech samples, achieving high accuracy in distinguishing the two dialects.
Plain English Explanation
The Tamil language has two main forms: a formal, literary dialect and a more casual, colloquial dialect. Identifying the dialect used in speech can be useful for various applications, such as language learning, speech recognition, and natural language processing.
In this study, the researchers explored using acoustic features - characteristics of the sound waves in speech - to automatically classify Tamil speech as either literary or colloquial. They trained a machine learning model on a dataset of Tamil speech samples, teaching it to recognize the distinctive acoustic patterns of each dialect.
The model was able to accurately distinguish between the literary and colloquial forms of Tamil, suggesting that the acoustic features captured meaningful differences between the two dialects. This approach could be used to build better speech recognition systems for Tamil or to analyze dialect usage in various contexts.
Technical Explanation
The researchers first collected a dataset of Tamil speech samples, including both literary and colloquial forms. They then extracted a set of acoustic features from the speech data, such as pitch, energy, and spectral characteristics.
Using these acoustic features as inputs, the researchers trained a machine learning model, specifically a Support Vector Machine (SVM) classifier, to distinguish between the literary and colloquial Tamil dialects. The model was evaluated using cross-validation techniques to assess its performance on unseen data.
The results showed that the SVM classifier was able to achieve high accuracy in correctly identifying the dialect of Tamil speech, demonstrating the potential of using acoustic features for this task. The researchers also compared the performance of their model to that of human listeners, finding that the model outperformed human judgments in some cases.
Critical Analysis
The authors acknowledge several limitations of their study, including the relatively small size of the dataset and the potential for bias in the data collection process. They also note that the performance of the model may be influenced by factors such as the recording environment, speaker characteristics, and the specific acoustic features used.
Additionally, the researchers do not provide much discussion on the practical implications or applications of their work. It would be interesting to see how this approach could be integrated into real-world systems, such as language learning platforms or speech recognition engines, and how it might perform in more diverse and realistic scenarios.
Further research could also explore the use of more advanced machine learning techniques, such as deep neural networks, to capture more nuanced acoustic patterns and improve the performance of the dialect identification system.
Conclusion
This study demonstrates the feasibility of using acoustic features to automatically distinguish between literary and colloquial dialects in the Tamil language. The proposed machine learning model achieved high accuracy in this task, suggesting that this approach could be a valuable tool for various language-related applications.
While the research has limitations and room for improvement, it represents a promising step forward in the field of dialect identification and highlights the potential of leveraging acoustic characteristics to understand the linguistic diversity within a language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Literary and Colloquial Dialect Identification for Tamil using Acoustic Features
M. Nanmalar, P. Vijayalakshmi, T. Nagarajan
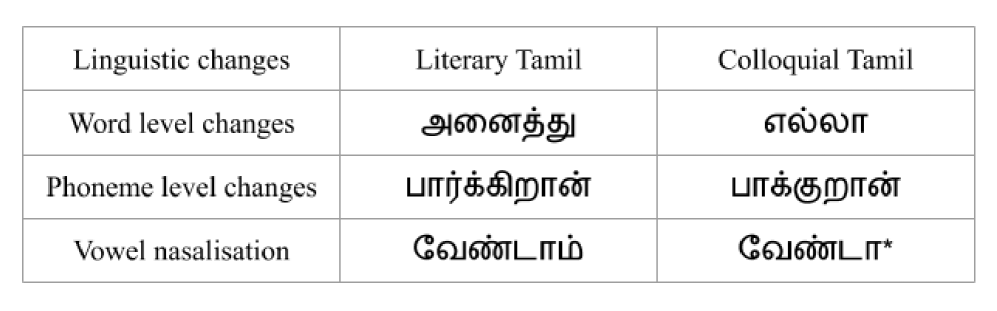
The evolution and diversity of a language is evident from it's various dialects. If the various dialects are not addressed in technological advancements like automatic speech recognition and speech synthesis, there is a chance that these dialects may disappear. Speech technology plays a role in preserving various dialects of a language from going extinct. In order to build a full fledged automatic speech recognition system that addresses various dialects, an Automatic Dialect Identification (ADI) system acting as the front end is required. This is similar to how language identification systems act as front ends to automatic speech recognition systems that handle multiple languages. The current work proposes a way to identify two popular and broadly classified Tamil dialects, namely literary and colloquial Tamil. Acoustical characteristics rather than phonetics and phonotactics are used, alleviating the requirement of language-dependant linguistic tools. Hence one major advantage of the proposed method is that it does not require an annotated corpus, hence it can be easily adapted to other languages. Gaussian Mixture Models (GMM) using Mel Frequency Cepstral Coefficient (MFCC) features are used to perform the classification task. The experiments yielded an error rate of 12%. Vowel nasalization, as being the reason for this good performance, is discussed. The number of mixture models for the GMM is varied and the performance is analysed.
Read more8/28/2024

0
Literary and Colloquial Tamil Dialect Identification
M. Nanmalar, P. Vijayalakshmi, T. Nagarajan
Culture and language evolve together. The old literary form of Tamil is used commonly for writing and the contemporary colloquial Tamil is used for speaking. Human-computer interaction applications require Colloquial Tamil (CT) to make it more accessible and easy for the everyday user and, it requires Literary Tamil (LT) when information is needed in a formal written format. Continuing the use of LT alongside CT in computer aided language learning applications will both preserve LT, and provide ease of use via CT, at the same time. Hence there is a need for the conversion between LT and CT dialects, which demands as a first step, dialect identification. Dialect Identification (DID) of LT and CT is an unexplored area of research. In the current work, keeping the nuances of both these dialects in mind, five methods are explored which include two implicit methods - Gaussian Mixture Model (GMM) and Convolutional Neural Network (CNN); two explicit methods - Parallel Phone Recognition (PPR) and Parallel Large Vocabulary Continuous Speech Recognition (P-LVCSR); two versions of the proposed explicit Unified Phone Recognition method (UPR-1 and UPR-2). These methods vary based on: the need for annotated data, the size of the unit, the way in which modelling is carried out, and the way in which the final decision is made. Even though the average duration of the test utterances is less - 4.9s for LT and 2.5s for CT - the systems performed well, offering the following identification accuracies: 87.72% (GMM), 93.97% (CNN), 89.24% (PPR), 94.21% (P-LVCSR), 88.57% (UPR-1), 93.53% (UPR-1 with P-LVCSR), 94.55% (UPR-2), and 95.61% (UPR-2 with P-LVCSR).
Read more8/27/2024

0
Abusive Speech Detection in Indic Languages Using Acoustic Features
Anika A. Spiesberger, Andreas Triantafyllopoulos, Iosif Tsangko, Bjorn W. Schuller
Abusive content in online social networks is a well-known problem that can cause serious psychological harm and incite hatred. The ability to upload audio data increases the importance of developing methods to detect abusive content in speech recordings. However, simply transferring the mechanisms from written abuse detection would ignore relevant information such as emotion and tone. In addition, many current algorithms require training in the specific language for which they are being used. This paper proposes to use acoustic and prosodic features to classify abusive content. We used the ADIMA data set, which contains recordings from ten Indic languages, and trained different models in multilingual and cross-lingual settings. Our results show that it is possible to classify abusive and non-abusive content using only acoustic and prosodic features. The most important and influential features are discussed.
Read more7/31/2024

0
Automatic detection of Mild Cognitive Impairment using high-dimensional acoustic features in spontaneous speech
Cong Zhang, Wenxing Guo, Hongsheng Dai
This study addresses the TAUKADIAL challenge, focusing on the classification of speech from people with Mild Cognitive Impairment (MCI) and neurotypical controls. We conducted three experiments comparing five machine-learning methods: Random Forests, Sparse Logistic Regression, k-Nearest Neighbors, Sparse Support Vector Machine, and Decision Tree, utilizing 1076 acoustic features automatically extracted using openSMILE. In Experiment 1, the entire dataset was used to train a language-agnostic model. Experiment 2 introduced a language detection step, leading to separate model training for each language. Experiment 3 further enhanced the language-agnostic model from Experiment 1, with a specific focus on evaluating the robustness of the models using out-of-sample test data. Across all three experiments, results consistently favored models capable of handling high-dimensional data, such as Random Forest and Sparse Logistic Regression, in classifying speech from MCI and controls.
Read more8/30/2024