Literary and Colloquial Tamil Dialect Identification

0

Sign in to get full access
Overview
- The paper focuses on identifying literary and colloquial Tamil dialects.
- It explores the nuances and differences between these two forms of the Tamil language.
- Techniques for automatically distinguishing between literary and colloquial Tamil are presented.
Plain English Explanation
The paper discusses the differences between two forms of the Tamil language - literary Tamil and colloquial Tamil. Literary Tamil is the formal, written form of the language, while colloquial Tamil is the informal, spoken form used in everyday conversations.
The paper explains the key linguistic and stylistic differences between these two dialects. For example, literary Tamil tends to use more complex grammatical structures and vocabulary, while colloquial Tamil is simpler and more conversational.
The researchers then describe techniques for automatically identifying whether a given piece of Tamil text is in the literary or colloquial dialect. They use machine learning models trained on samples of each dialect to classify new text. This could be useful for applications like language processing, translation, and educational tools.
Overall, the paper sheds light on the nuanced relationship between the formal and informal versions of the Tamil language, and demonstrates how computational methods can be used to distinguish between them.
Technical Explanation
The paper first outlines the key linguistic and stylistic differences between literary and colloquial Tamil. Literary Tamil tends to use more complex grammatical structures, like case inflections and honorifics, as well as a broader, more formal vocabulary. In contrast, colloquial Tamil is simpler and more conversational, drawing on a more limited lexicon.
To automatically identify the dialect of a given Tamil text, the researchers use supervised machine learning models. They compile datasets of literary and colloquial Tamil samples, which they use to train classifiers like logistic regression and support vector machines. The models learn to recognize the linguistic patterns that distinguish the two dialects.
When tested on new text, the best-performing model was able to achieve over 90% accuracy in identifying the dialect. The researchers explore various feature sets, including lexical, syntactic, and stylistic features, to understand which characteristics are most informative for the classification task.
Critical Analysis
The paper provides a thorough investigation of the differences between literary and colloquial Tamil, and demonstrates the feasibility of automatically distinguishing between the two dialects using machine learning techniques.
One potential limitation is the reliance on written text samples, which may not fully capture the nuances of spoken colloquial Tamil. Incorporating audio data or transcripts of natural conversations could further improve the models' ability to recognize colloquial language.
Additionally, the research is focused on the Tamil language specifically, so the generalizability of the techniques to other language pairs with formal and informal varieties is not addressed. Exploring the applicability of the approach to different linguistic contexts could be a valuable area for future research.
Overall, the paper makes a meaningful contribution to the understanding and computational modeling of Tamil dialect differences, which could have practical applications in areas like machine translation, language education, and text analysis.
Conclusion
This paper explores the nuances of literary and colloquial Tamil, and presents techniques for automatically distinguishing between these two dialects of the language. By highlighting the linguistic and stylistic differences, and demonstrating the feasibility of computational identification, the research contributes to our understanding of the Tamil language and its diverse forms of expression.
The findings could have practical applications in areas like language processing, translation, and educational tools, by enabling more accurate and contextually appropriate handling of Tamil text and speech. Further research investigating the generalizability of the approach to other language pairs, as well as the integration of additional data sources, could extend the impact of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Literary and Colloquial Tamil Dialect Identification
M. Nanmalar, P. Vijayalakshmi, T. Nagarajan
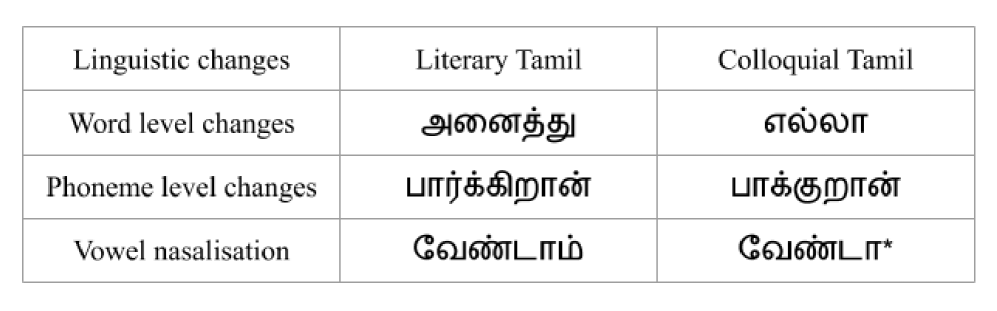
Culture and language evolve together. The old literary form of Tamil is used commonly for writing and the contemporary colloquial Tamil is used for speaking. Human-computer interaction applications require Colloquial Tamil (CT) to make it more accessible and easy for the everyday user and, it requires Literary Tamil (LT) when information is needed in a formal written format. Continuing the use of LT alongside CT in computer aided language learning applications will both preserve LT, and provide ease of use via CT, at the same time. Hence there is a need for the conversion between LT and CT dialects, which demands as a first step, dialect identification. Dialect Identification (DID) of LT and CT is an unexplored area of research. In the current work, keeping the nuances of both these dialects in mind, five methods are explored which include two implicit methods - Gaussian Mixture Model (GMM) and Convolutional Neural Network (CNN); two explicit methods - Parallel Phone Recognition (PPR) and Parallel Large Vocabulary Continuous Speech Recognition (P-LVCSR); two versions of the proposed explicit Unified Phone Recognition method (UPR-1 and UPR-2). These methods vary based on: the need for annotated data, the size of the unit, the way in which modelling is carried out, and the way in which the final decision is made. Even though the average duration of the test utterances is less - 4.9s for LT and 2.5s for CT - the systems performed well, offering the following identification accuracies: 87.72% (GMM), 93.97% (CNN), 89.24% (PPR), 94.21% (P-LVCSR), 88.57% (UPR-1), 93.53% (UPR-1 with P-LVCSR), 94.55% (UPR-2), and 95.61% (UPR-2 with P-LVCSR).
Read more8/27/2024
0
Literary and Colloquial Dialect Identification for Tamil using Acoustic Features
M. Nanmalar, P. Vijayalakshmi, T. Nagarajan
The evolution and diversity of a language is evident from it's various dialects. If the various dialects are not addressed in technological advancements like automatic speech recognition and speech synthesis, there is a chance that these dialects may disappear. Speech technology plays a role in preserving various dialects of a language from going extinct. In order to build a full fledged automatic speech recognition system that addresses various dialects, an Automatic Dialect Identification (ADI) system acting as the front end is required. This is similar to how language identification systems act as front ends to automatic speech recognition systems that handle multiple languages. The current work proposes a way to identify two popular and broadly classified Tamil dialects, namely literary and colloquial Tamil. Acoustical characteristics rather than phonetics and phonotactics are used, alleviating the requirement of language-dependant linguistic tools. Hence one major advantage of the proposed method is that it does not require an annotated corpus, hence it can be easily adapted to other languages. Gaussian Mixture Models (GMM) using Mel Frequency Cepstral Coefficient (MFCC) features are used to perform the classification task. The experiments yielded an error rate of 12%. Vowel nasalization, as being the reason for this good performance, is discussed. The number of mixture models for the GMM is varied and the performance is analysed.
Read more8/28/2024
💬
0
Tamil Language Computing: the Present and the Future
Kengatharaiyer Sarveswaran
This paper delves into the text processing aspects of Language Computing, which enables computers to understand, interpret, and generate human language. Focusing on tasks such as speech recognition, machine translation, sentiment analysis, text summarization, and language modelling, language computing integrates disciplines including linguistics, computer science, and cognitive psychology to create meaningful human-computer interactions. Recent advancements in deep learning have made computers more accessible and capable of independent learning and adaptation. In examining the landscape of language computing, the paper emphasises foundational work like encoding, where Tamil transitioned from ASCII to Unicode, enhancing digital communication. It discusses the development of computational resources, including raw data, dictionaries, glossaries, annotated data, and computational grammars, necessary for effective language processing. The challenges of linguistic annotation, the creation of treebanks, and the training of large language models are also covered, emphasising the need for high-quality, annotated data and advanced language models. The paper underscores the importance of building practical applications for languages like Tamil to address everyday communication needs, highlighting gaps in current technology. It calls for increased research collaboration, digitization of historical texts, and fostering digital usage to ensure the comprehensive development of Tamil language processing, ultimately enhancing global communication and access to digital services.
Read more8/13/2024
🗣️
0
Low-resource speech recognition and dialect identification of Irish in a multi-task framework
Liam Lonergan, Mengjie Qian, Neasa N'i Chiar'ain, Christer Gobl, Ailbhe N'i Chasaide
This paper explores the use of Hybrid CTC/Attention encoder-decoder models trained with Intermediate CTC (InterCTC) for Irish (Gaelic) low-resource speech recognition (ASR) and dialect identification (DID). Results are compared to the current best performing models trained for ASR (TDNN-HMM) and DID (ECAPA-TDNN). An optimal InterCTC setting is initially established using a Conformer encoder. This setting is then used to train a model with an E-branchformer encoder and the performance of both architectures are compared. A multi-task fine-tuning approach is adopted for language model (LM) shallow fusion. The experiments yielded an improvement in DID accuracy of 10.8% relative to a baseline ECAPA-TDNN, and WER performance approaching the TDNN-HMM model. This multi-task approach emerges as a promising strategy for Irish low-resource ASR and DID.
Read more5/3/2024