Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts

0
Sign in to get full access
Overview
- Proposes a novel "Uni-MoE" framework for scaling unified multimodal large language models (LLMs) using a mixture of experts (MoE) approach
- Aims to address the challenges of building large-scale, high-performance multimodal LLMs
- Introduces a training strategy and architectural design to enable efficient parallel training and inference of multimodal LLMs
Plain English Explanation
The paper introduces a new framework called "Uni-MoE" that uses a mixture of experts (MoE) approach to scale unified multimodal large language models (LLMs). Multimodal LLMs are powerful AI models that can understand and generate content across different modalities, such as text, images, and audio.
However, building large-scale, high-performance multimodal LLMs comes with significant challenges. The Uni-MoE framework aims to address these challenges by employing a MoE architecture and a novel training strategy. The MoE approach allows the model to effectively leverage different "expert" submodules, each focusing on a specific task or modality. This enables more efficient parallel training and inference, allowing the model to scale to larger sizes without sacrificing performance.
The paper also introduces an intuition-aware mixture of rank-1 experts design, which further enhances the MoE approach by incorporating expert-specific intuitions and parameters.
Overall, the Uni-MoE framework provides a promising approach for building scalable, high-performance multimodal LLMs that can be applied to a wide range of applications, from natural language processing to multimodal content generation and understanding.
Technical Explanation
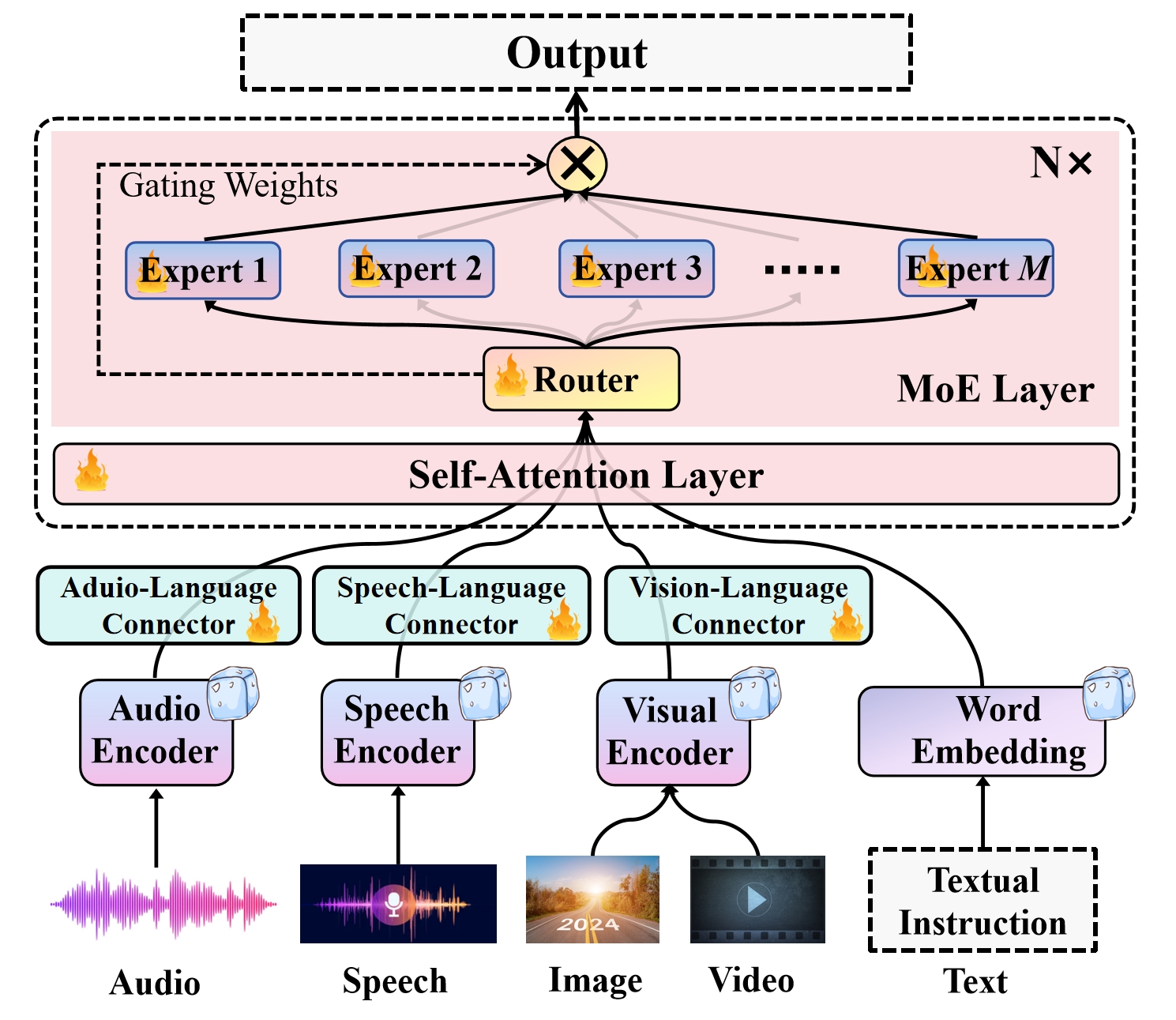
The Uni-MoE framework proposes a novel mixture of experts (MoE) architecture and training strategy for scaling unified multimodal large language models (LLMs). The key components of the Uni-MoE approach include:
-
MoE Architecture: The model is composed of a shared backbone network and a set of expert submodules, each specializing in a specific task or modality. A gating network dynamically routes the input to the appropriate expert(s) based on the input's characteristics.
-
Intuition-Aware Mixture of Rank-1 Experts: The expert submodules are designed as rank-1 matrices, which reduces the parameter count and enables more efficient parameter updates. The experts are also intuition-aware, incorporating expert-specific intuitions and parameters to further improve performance.
-
Training Strategy: The authors propose a training strategy that leverages parallel training and inference of the expert submodules. This allows the model to efficiently scale to larger sizes without sacrificing performance, addressing the challenges of building large-scale, high-performance multimodal LLMs.
The paper evaluates the Uni-MoE framework on various multimodal benchmarks and demonstrates its ability to outperform state-of-the-art multimodal LLMs in terms of performance and efficiency.
Critical Analysis
The Uni-MoE framework presents a promising approach for scaling unified multimodal LLMs, but there are a few caveats and limitations to consider:
-
Complexity: The MoE architecture and intuition-aware expert design introduce additional complexity, which may come with increased computational and memory requirements. The authors acknowledge the need to carefully balance the trade-off between model complexity and performance gains.
-
Domain-Specific Expertise: While the MoE approach allows for specialization, it is crucial to ensure that the expert submodules truly capture relevant domain-specific expertise. Improper initialization or training of the experts may lead to suboptimal performance.
-
Interpretability: The Uni-MoE framework's dynamic routing mechanism and expert-specific intuitions may reduce the interpretability of the model's decision-making process. This is an important consideration, especially in applications where model transparency is a key requirement.
-
Generalization: The authors focus on evaluating the Uni-MoE framework on multimodal benchmarks, but its ability to generalize to a wider range of real-world applications is not thoroughly explored in the paper.
Despite these potential limitations, the Uni-MoE framework represents a significant advancement in the field of scalable multimodal LLMs and warrants further research and refinement to address the identified challenges.
Conclusion
The Uni-MoE framework proposed in this paper offers a novel approach to scaling unified multimodal large language models (LLMs) using a mixture of experts (MoE) architecture. By leveraging parallel training and inference of expert submodules, and incorporating intuition-aware rank-1 experts, the Uni-MoE framework demonstrates the ability to build large-scale, high-performance multimodal LLMs.
The key contributions of this work include the Uni-MoE architectural design, the intuition-aware mixture of rank-1 experts, and the training strategy that enables efficient scaling of multimodal LLMs. The framework's performance on various multimodal benchmarks highlights its potential to advance the state of the art in multimodal language understanding and generation.
While the Uni-MoE framework presents some challenges, such as complexity, interpretability, and generalization, the overall approach offers a promising direction for the development of scalable, versatile, and high-performing multimodal LLMs, which can have a significant impact on a wide range of applications, from natural language processing to multimodal content creation and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024
0
Alt-MoE: Multimodal Alignment via Alternating Optimization of Multi-directional MoE with Unimodal Models
Hongyang Lei, Xiaolong Cheng, Dan Wang, Qi Qin, Huazhen Huang, Yetao Wu, Qingqing Gu, Zhonglin Jiang, Yong Chen, Luo Ji
Recent Large Multi-Modal Models (LMMs) have made significant advancements in multi-modal alignment by employing lightweight connection modules to facilitate the representation and fusion of knowledge from existing pre-trained uni-modal models. However, these methods still rely on modality-specific and direction-specific connectors, leading to compartmentalized knowledge representations and reduced computational efficiency, which limits the model's ability to form unified multi-modal representations. To address these issues, we introduce a novel training framework, Alt-MoE, which employs the Mixture of Experts (MoE) as a unified multi-directional connector across modalities, and employs a multi-step sequential alternating unidirectional alignment strategy, which converges to bidirectional alignment over iterations. The extensive empirical studies revealed the following key points: 1) Alt-MoE achieves competitive results by integrating diverse knowledge representations from uni-modal models. This approach seamlessly fuses the specialized expertise of existing high-performance uni-modal models, effectively synthesizing their domain-specific knowledge into a cohesive multi-modal representation. 2) Alt-MoE efficiently scales to new tasks and modalities without altering its model architecture or training strategy. Furthermore, Alt-MoE operates in latent space, supporting vector pre-storage and real-time retrieval via lightweight multi-directional MoE, thereby facilitating massive data processing. Our methodology has been validated on several well-performing uni-modal models (LLAMA3, Qwen2, and DINOv2), achieving competitive results on a wide range of downstream tasks and datasets.
Read more9/11/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024
📉
0
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
Read more5/10/2024