LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
2405.11106
0
0
🏅
Abstract
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
Create account to get full access
Overview
- This paper provides an overview of conventional Multi-Agent Reinforcement Learning (MARL) and Large Language Model (LLM)-based single-agent Reinforcement Learning (RL) frameworks, laying the groundwork for exploring LLM-based MARL.
- The authors survey existing literature on using LLMs as policy teachers for training RL agents, as well as the use of LLMs in game-playing agents and text-based educational environments.
- The paper aims to identify current challenges and future directions for LLM-based MARL, which could have significant implications for advancing the field of multi-agent systems.
Plain English Explanation
This research paper explores the potential of using large language models (LLMs) to enhance multi-agent reinforcement learning (MARL) systems. Reinforcement learning is a type of machine learning where agents learn to make decisions by interacting with their environment and receiving rewards or punishments. MARL involves multiple agents learning and acting together in the same environment.
The authors first provide an overview of traditional MARL approaches, as well as how LLMs have been used in single-agent reinforcement learning. This lays the groundwork for their exploration of using LLMs in MARL.
The paper then surveys existing research on using LLMs as "policy teachers" to help train reinforcement learning agents by providing guidance and knowledge. The authors also look at how LLMs have been used to create intelligent game-playing agents [and in text-based educational environments](https://aimodels.fyi/papers/arxiv/survey-large-language-model-based-game-agents, https://aimodels.fyi/papers/arxiv/towards-generalizable-agents-text-based-educational-environments).
By understanding the current state of LLM-based RL and MARL, the authors aim to identify the key challenges and promising future directions for using LLMs to advance the field of multi-agent systems. This could lead to more capable and flexible multi-agent systems that can tackle complex real-world problems.
Technical Explanation
The paper begins by providing an overview of conventional MARL approaches, which involve multiple agents learning to cooperate or compete in a shared environment. The authors then survey the use of LLMs in single-agent RL, where LLMs have been leveraged as "policy teachers" to guide the training of RL agents.
Building on this foundation, the authors explore how LLMs could be integrated into MARL frameworks. They discuss research on using LLMs to provide guidance and knowledge to RL agents during training, as well as the application of LLM-based agents in game-playing [and text-based educational environments](https://aimodels.fyi/papers/arxiv/survey-large-language-model-based-game-agents, https://aimodels.fyi/papers/arxiv/towards-generalizable-agents-text-based-educational-environments).
The key insights and challenges identified in this survey are:
- LLMs can serve as powerful policy teachers, providing high-level guidance and task-specific knowledge to RL agents
- LLM-based agents have shown strong performance in complex game environments, suggesting their potential for MARL
- Integrating LLMs into MARL systems poses unique challenges, such as scalability, credit assignment, and multi-agent coordination
Critical Analysis
The paper provides a comprehensive overview of the current state of LLM-based RL and MARL, highlighting the potential benefits and challenges of this approach. However, the authors acknowledge several limitations and areas for further research:
- Scalability: Integrating LLMs into MARL systems may face scalability issues, as the computational and memory requirements of LLMs can be substantial.
- Credit Assignment: Effectively assigning credit or blame to individual agents in a multi-agent system is a significant challenge that needs to be addressed.
- Multi-Agent Coordination: Coordinating the actions and decision-making of multiple LLM-based agents in a shared environment is a complex problem that requires further investigation.
Additionally, the paper does not delve into potential societal implications or ethical concerns associated with the deployment of LLM-based MARL systems, such as issues related to transparency, accountability, and fairness. These are important considerations that future research in this area should explore.
Conclusion
This research paper provides a valuable survey of the current state of LLM-based RL and MARL, outlining the key insights, challenges, and future directions for this emerging field. By integrating large language models into multi-agent reinforcement learning frameworks, the authors argue that researchers could develop more capable and flexible multi-agent systems to tackle complex real-world problems.
While the potential benefits of LLM-based MARL are significant, the authors highlight important scalability, credit assignment, and coordination challenges that must be addressed. Addressing these issues and exploring the broader societal implications of this technology will be crucial as the field continues to evolve.
Overall, this paper lays the groundwork for further research into LLM-based MARL, which could have far-reaching implications for the advancement of multi-agent systems and their applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
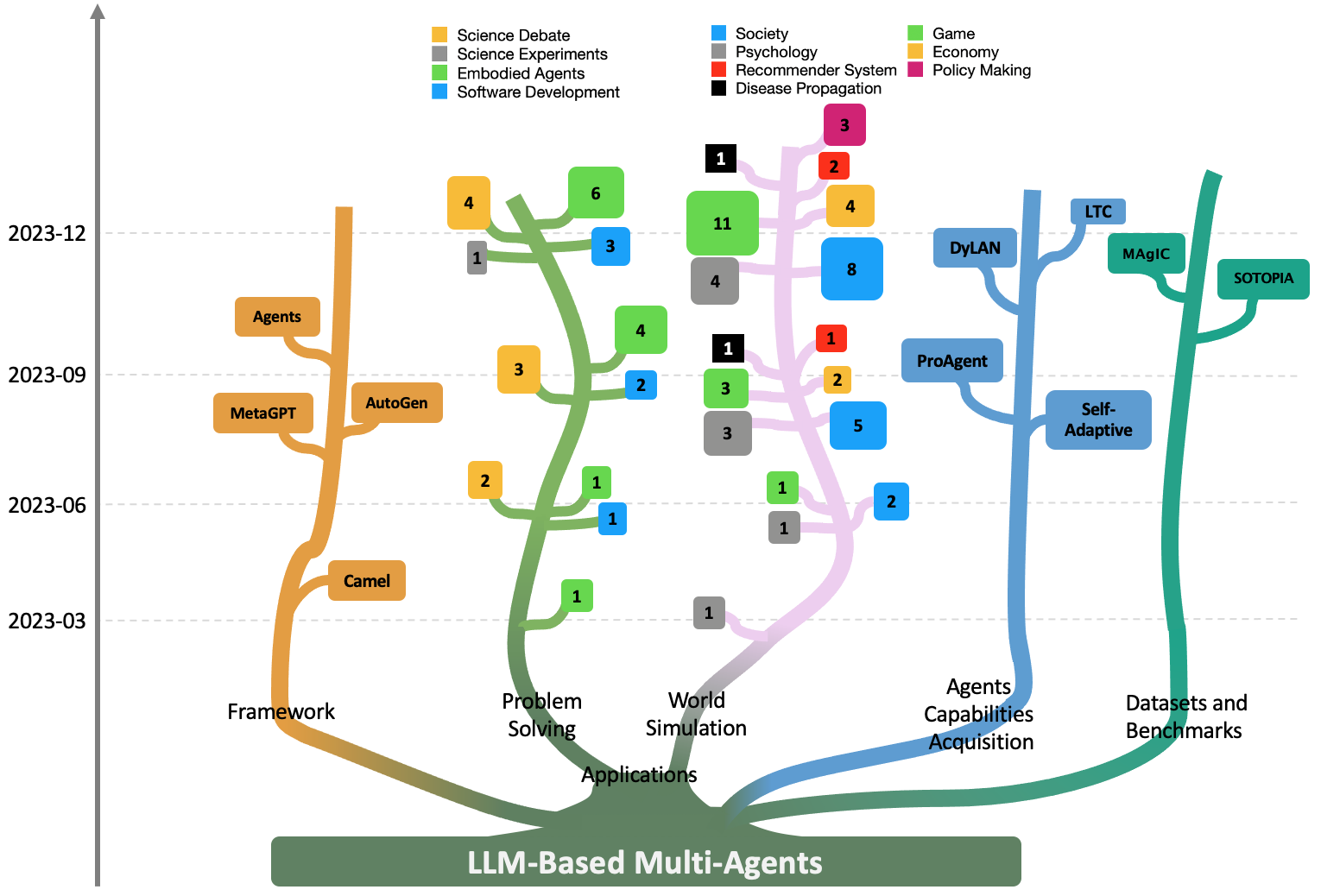
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
0
0
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
4/22/2024
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
💬
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
0
0
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
4/23/2024
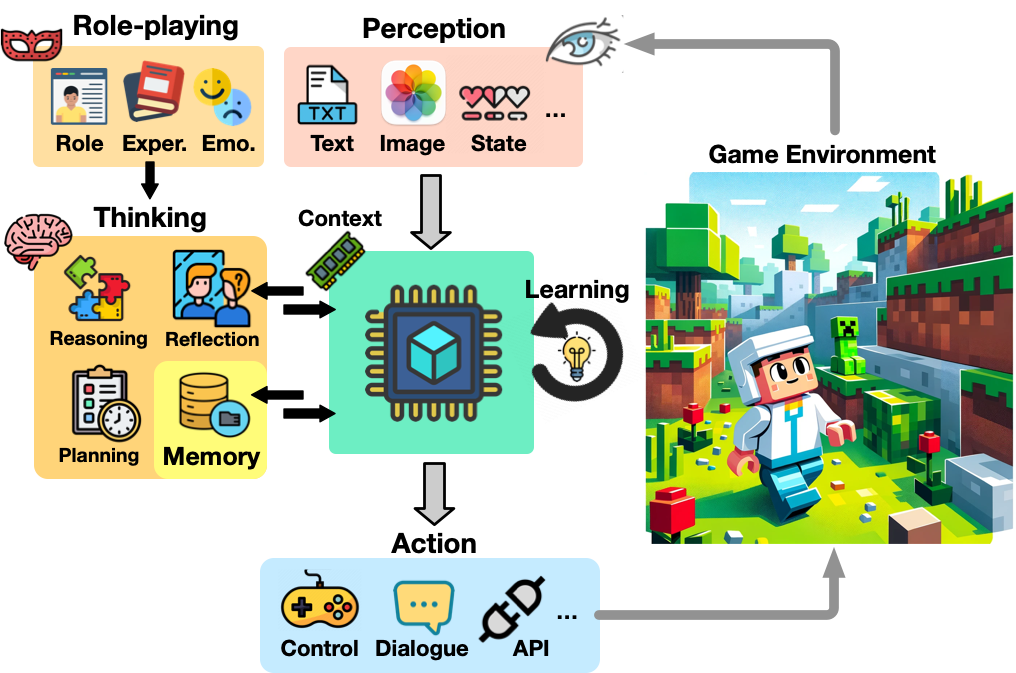
A Survey on Large Language Model-Based Game Agents
Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, Ling Liu
0
0
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
4/3/2024