Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
2311.13373
0
0
💬
Abstract
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel framework that addresses the challenges of using Large Language Models (LLMs) and Reinforcement Learning (RL) agents for complex sequential decision-making tasks.
- LLM-based agents lack specialization in specific target problems, particularly in real-time dynamic environments, and can be costly and time-consuming to deploy.
- RL agents can specialize in target tasks but often suffer from low sampling efficiency and high exploration costs.
- The proposed framework trains a smaller, specialized student RL agent using instructions from an LLM-based teacher agent, allowing the student to distill the prior knowledge of the LLM.
Plain English Explanation
The paper introduces a new approach to train AI agents that can solve complex, real-world problems. Traditional methods have limitations - large language models can provide high-level guidance, but struggle with specific tasks, while reinforcement learning agents are specialized but require a lot of data and experimentation.
The key idea is to combine the strengths of these two approaches. The researchers train a "teacher" agent using a large language model, which can provide general instructions. Then, they use this teacher to efficiently train a smaller, more specialized "student" agent using reinforcement learning. The student agent can learn from the teacher's guidance, requiring much less data and exploration than a typical RL agent.
Through further training, the student agent even surpasses the capabilities of its teacher for the target task. The researchers test this approach on challenging simulated environments, showing it outperforms other methods.
Technical Explanation
The paper presents a framework that addresses the limitations of both LLM-based agents and RL agents for complex sequential decision-making tasks.
The framework involves training a smaller, specialized student RL agent using guidance from a larger, pre-trained LLM-based teacher agent. By incorporating the teacher's high-level instructions, the student agent can distill the prior knowledge of the LLM into its own model, allowing it to be trained with significantly less data.
Furthermore, through additional training with environment feedback, the student agent is able to surpass the capabilities of its teacher for the target task. The researchers evaluate their approach on challenging MiniGrid and Habitat environments, designed for embodied AI research. The results demonstrate that their framework achieves superior performance compared to strong baseline methods.
Critical Analysis
The paper presents a promising approach to combine the strengths of LLM-based agents and RL agents, addressing the limitations of each. However, the researchers acknowledge that their framework may still be costly and time-consuming to deploy in practical scenarios, as it requires training both a teacher and a student agent.
Additionally, the experiments are conducted in simulated environments, and the researchers note that further research is needed to evaluate the framework's performance in real-world, dynamic settings. The generalizability of the approach to a wider range of tasks and environments also remains an area for further exploration.
While the results are impressive, it's important to consider potential biases or limitations in the training data and algorithms used, which could impact the agent's performance and decision-making in unexpected ways. Ongoing critical evaluation and transparency around the framework's capabilities and limitations will be essential as it is further developed and applied.
Conclusion
This paper introduces a novel framework that leverages the strengths of large language models and reinforcement learning to address complex sequential decision-making tasks. By training a specialized student RL agent using guidance from an LLM-based teacher, the framework allows the student to distill prior knowledge while surpassing the teacher's capabilities through further training.
The promising results demonstrate the potential of this approach to overcome the limitations of traditional LLM-based and RL-based agents, paving the way for more capable and efficient AI systems to tackle real-world problems. As the research continues, it will be important to explore the framework's scalability, robustness, and real-world applicability, as well as to address any ethical considerations that may arise.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
💬
Large Language Models as Generalizable Policies for Embodied Tasks
Andrew Szot, Max Schwarzer, Harsh Agrawal, Bogdan Mazoure, Walter Talbott, Katherine Metcalf, Natalie Mackraz, Devon Hjelm, Alexander Toshev
0
0
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
4/17/2024
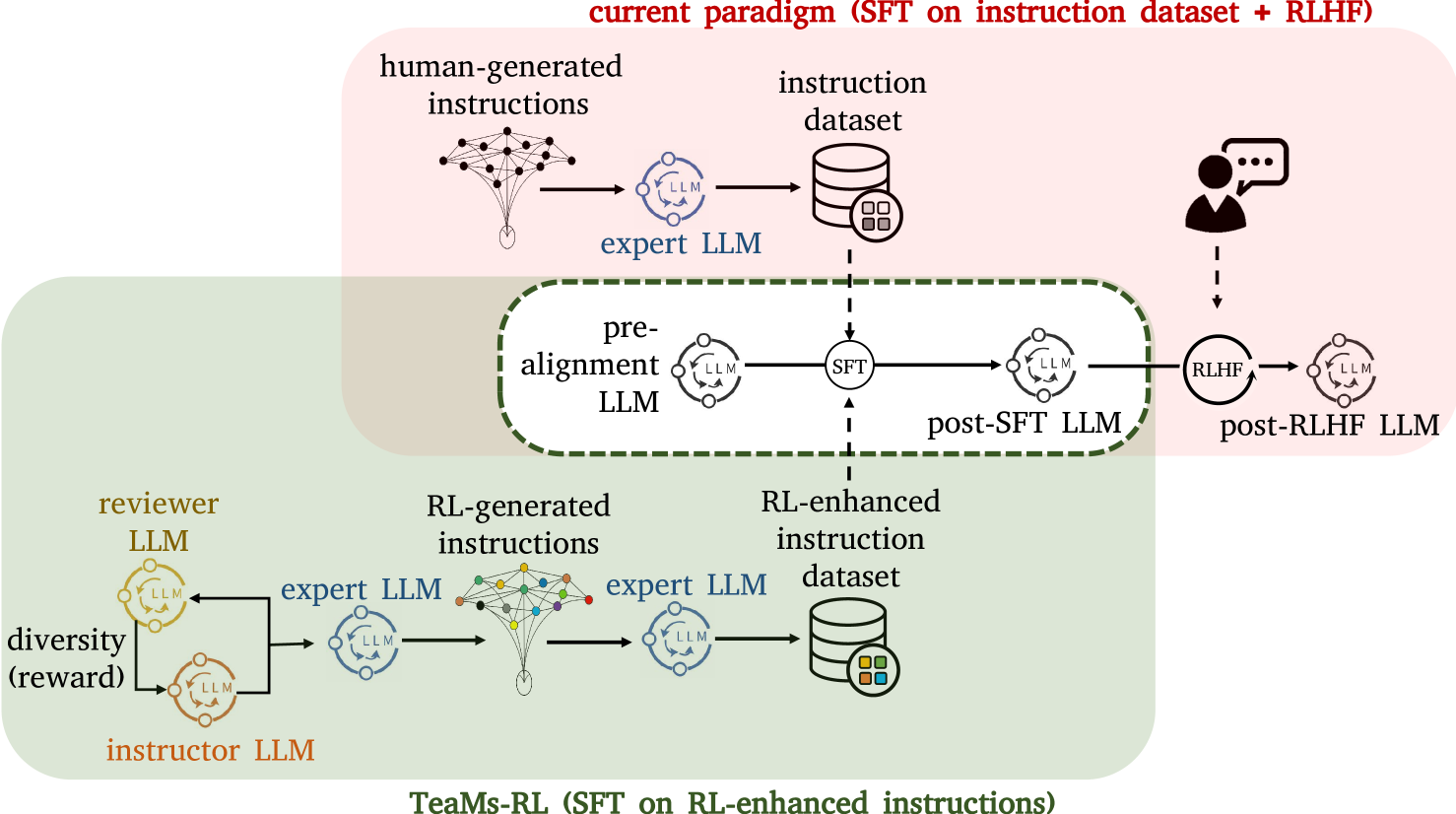
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
0
0
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of WizardLM's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection.
5/7/2024

Towards Generalizable Agents in Text-Based Educational Environments: A Study of Integrating RL with LLMs
Bahar Radmehr, Adish Singla, Tanja Kaser
0
0
There has been a growing interest in developing learner models to enhance learning and teaching experiences in educational environments. However, existing works have primarily focused on structured environments relying on meticulously crafted representations of tasks, thereby limiting the agent's ability to generalize skills across tasks. In this paper, we aim to enhance the generalization capabilities of agents in open-ended text-based learning environments by integrating Reinforcement Learning (RL) with Large Language Models (LLMs). We investigate three types of agents: (i) RL-based agents that utilize natural language for state and action representations to find the best interaction strategy, (ii) LLM-based agents that leverage the model's general knowledge and reasoning through prompting, and (iii) hybrid LLM-assisted RL agents that combine these two strategies to improve agents' performance and generalization. To support the development and evaluation of these agents, we introduce PharmaSimText, a novel benchmark derived from the PharmaSim virtual pharmacy environment designed for practicing diagnostic conversations. Our results show that RL-based agents excel in task completion but lack in asking quality diagnostic questions. In contrast, LLM-based agents perform better in asking diagnostic questions but fall short of completing the task. Finally, hybrid LLM-assisted RL agents enable us to overcome these limitations, highlighting the potential of combining RL and LLMs to develop high-performing agents for open-ended learning environments.
5/1/2024