LLM-grounded Video Diffusion Models
2309.17444
0
0
🤖
Abstract
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers have developed a new approach called LLM-grounded Video Diffusion (LVD) to address limitations in current text-conditioned video generation models.
- LVD first uses a large language model (LLM) to generate dynamic scene layouts based on text inputs, and then uses these layouts to guide a diffusion model for video generation.
- The paper claims that LVD significantly outperforms baseline video diffusion models in generating videos that faithfully match the desired attributes and motion patterns from the text prompts.
Plain English Explanation
The paper introduces a new technique called LLM-grounded Video Diffusion (LVD) to improve neural video generation from text inputs. Current models for text-to-video generation still struggle with generating videos that accurately reflect complex spatial and temporal dynamics described in the text prompts.
To address this, the researchers first use a large language model (LLM) to analyze the text prompt and generate a detailed "layout" of the scene, including the objects present and how they should move over time. This layout acts as a blueprint that then guides a diffusion model to generate the final video. The idea is that the LLM can better understand and capture the intricate spatiotemporal relationships from the text, and this information helps the video model produce more faithful outputs.
The paper demonstrates that this LLM-guided approach significantly outperforms previous video diffusion models that generate video directly from text. By first translating the text into a more structured scene layout, the model is better able to generate videos that match the intended motion and attributes.
Technical Explanation
The core idea of LVD is to leverage the powerful text understanding capabilities of large language models (LLMs) to guide the video generation process of diffusion models. Rather than directly generating video from text, LVD first uses an LLM to produce a dynamic scene layout that captures the spatial and temporal information implied by the text prompt. This layout is then used to adjust the attention maps of the diffusion model, helping it generate video sequences that faithfully reflect the desired object motions and scene dynamics.
Specifically, the researchers use a pre-trained LLM to encode the text prompt and generate a set of "layout tokens" that describe the scene elements, their locations, and how they should move over time. These layout tokens are then projected into spatial and temporal attention maps, which are used to modulate the attention of the video diffusion model. This "conditional guidance" helps the diffusion model focus on generating content that aligns with the LLM-predicted layout.
The paper evaluates LVD on several benchmark video generation tasks and shows that it outperforms previous state-of-the-art video diffusion models, as well as other text-to-video baselines. The authors attribute this performance gain to the ability of LLMs to better capture the complex spatiotemporal semantics in the text prompts, which then provides useful guidance for the video diffusion model.
Critical Analysis
The paper presents a compelling approach to improving text-conditioned video generation by leveraging the strengths of large language models. By first translating the text prompt into a structured scene layout, LVD is able to guide the diffusion model towards generating videos that more faithfully match the intended attributes and motion patterns.
However, the paper does not extensively discuss the limitations and potential issues with this approach. For example, it is unclear how well LVD would scale to more diverse or open-ended text prompts, or how robust the method is to prompts that contain ambiguity or inconsistencies. Additionally, the paper does not explore the computational and memory efficiency of the LLM-guided approach compared to direct text-to-video generation.
Further research could also investigate ways to tighten the integration between the LLM and the video diffusion model, possibly by training them jointly or exploring more sophisticated ways of fusing the layout information. Advancements in video diffusion models may also lead to improved video generation capabilities that could complement the LLM-guided approach.
Overall, the LVD method represents an interesting step forward in text-to-video generation, and the core idea of leveraging LLMs to guide other generative models is a promising direction for advancing generative AI beyond language modeling alone.
Conclusion
The paper introduces a novel approach called LLM-grounded Video Diffusion (LVD) that combines the strengths of large language models and diffusion-based video generation. By first using an LLM to generate a detailed scene layout from the text prompt, LVD is able to guide a diffusion model to produce videos that more faithfully capture the desired spatiotemporal attributes and motion patterns.
The results demonstrate that this LLM-guided approach significantly outperforms direct text-to-video generation baselines, highlighting the potential of leveraging language models to enhance other generative AI tasks. While the paper does not fully explore the limitations of the method, the core idea represents an important step towards improving the realism and controllability of neural video generation from text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models
Paramanand Chandramouli, Kanchana Vaishnavi Gandikota
0
0
Research in vision-language models has seen rapid developments off-late, enabling natural language-based interfaces for image generation and manipulation. Many existing text guided manipulation techniques are restricted to specific classes of images, and often require fine-tuning to transfer to a different style or domain. Nevertheless, generic image manipulation using a single model with flexible text inputs is highly desirable. Recent work addresses this task by guiding generative models trained on the generic image datasets using pretrained vision-language encoders. While promising, this approach requires expensive optimization for each input. In this work, we propose an optimization-free method for the task of generic image manipulation from text prompts. Our approach exploits recent Latent Diffusion Models (LDM) for text to image generation to achieve zero-shot text guided manipulation. We employ a deterministic forward diffusion in a lower dimensional latent space, and the desired manipulation is achieved by simply providing the target text to condition the reverse diffusion process. We refer to our approach as LDEdit. We demonstrate the applicability of our method on semantic image manipulation and artistic style transfer. Our method can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion. Extensive experiments demonstrate the benefit of our approach over competing baselines.
5/7/2024
📈
Grounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Xiaolong Li, Jiawei Mo, Ying Wang, Chethan Parameshwara, Xiaohan Fei, Ashwin Swaminathan, CJ Taylor, Zhuowen Tu, Paolo Favaro, Stefano Soatto
0
0
In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
4/30/2024
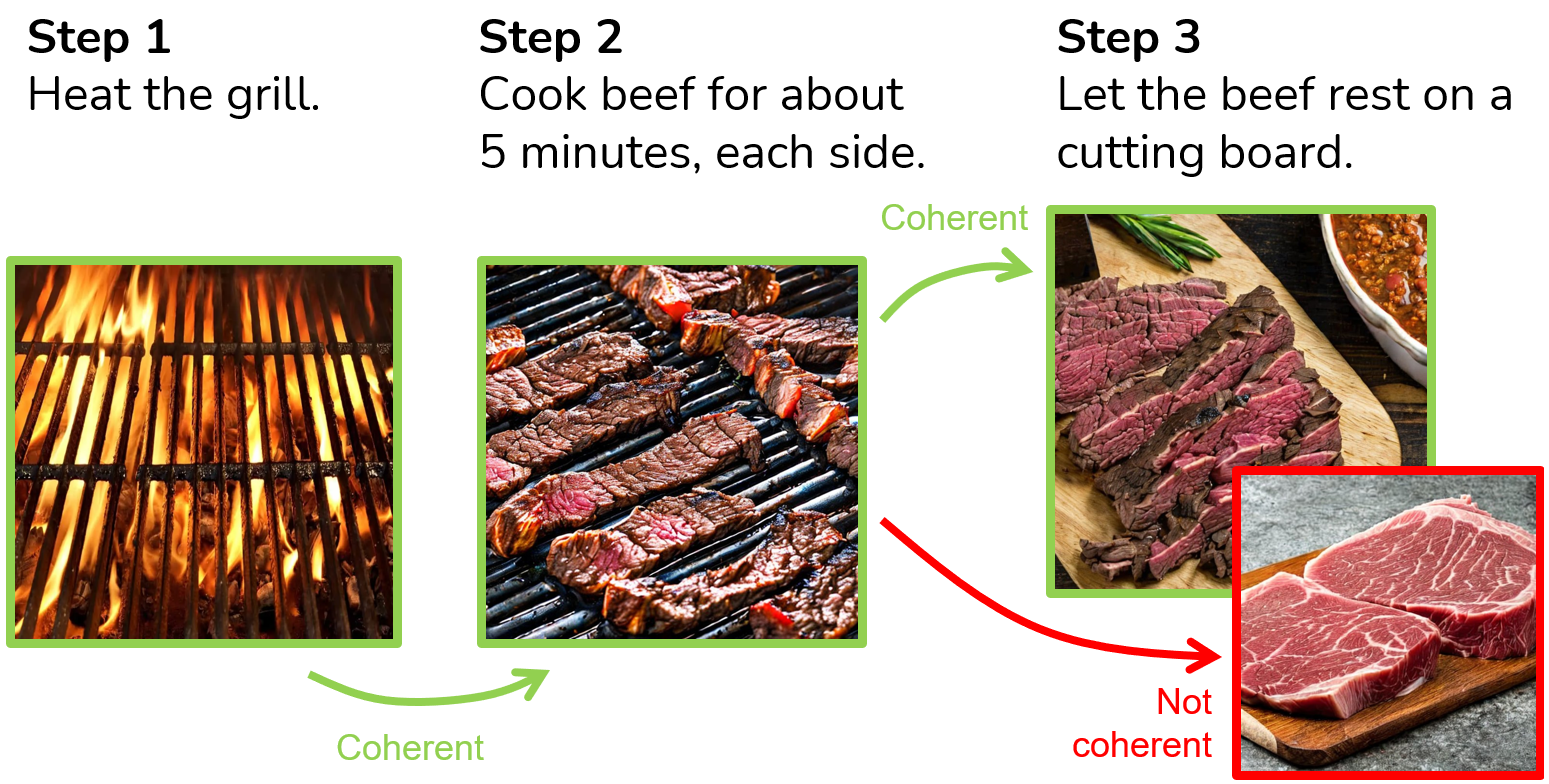
New!Generating Coherent Sequences of Visual Illustrations for Real-World Manual Tasks
Jo~ao Bordalo, Vasco Ramos, Rodrigo Val'erio, Diogo Gl'oria-Silva, Yonatan Bitton, Michal Yarom, Idan Szpektor, Joao Magalhaes
0
0
Multistep instructions, such as recipes and how-to guides, greatly benefit from visual aids, such as a series of images that accompany the instruction steps. While Large Language Models (LLMs) have become adept at generating coherent textual steps, Large Vision/Language Models (LVLMs) are less capable of generating accompanying image sequences. The most challenging aspect is that each generated image needs to adhere to the relevant textual step instruction, as well as be visually consistent with earlier images in the sequence. To address this problem, we propose an approach for generating consistent image sequences, which integrates a Latent Diffusion Model (LDM) with an LLM to transform the sequence into a caption to maintain the semantic coherence of the sequence. In addition, to maintain the visual coherence of the image sequence, we introduce a copy mechanism to initialise reverse diffusion processes with a latent vector iteration from a previously generated image from a relevant step. Both strategies will condition the reverse diffusion process on the sequence of instruction steps and tie the contents of the current image to previous instruction steps and corresponding images. Experiments show that the proposed approach is preferred by humans in 46.6% of the cases against 26.6% for the second best method. In addition, automatic metrics showed that the proposed method maintains semantic coherence and visual consistency across steps in both domains.
5/17/2024
🔗
Video Diffusion Models: A Survey
Andrew Melnik, Michal Ljubljanac, Cong Lu, Qi Yan, Weiming Ren, Helge Ritter
0
0
Diffusion generative models have recently become a robust technique for producing and modifying coherent, high-quality video. This survey offers a systematic overview of critical elements of diffusion models for video generation, covering applications, architectural choices, and the modeling of temporal dynamics. Recent advancements in the field are summarized and grouped into development trends. The survey concludes with an overview of remaining challenges and an outlook on the future of the field. Website: https://github.com/ndrwmlnk/Awesome-Video-Diffusion-Models
5/7/2024