Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
2312.14385
0
11
Abstract
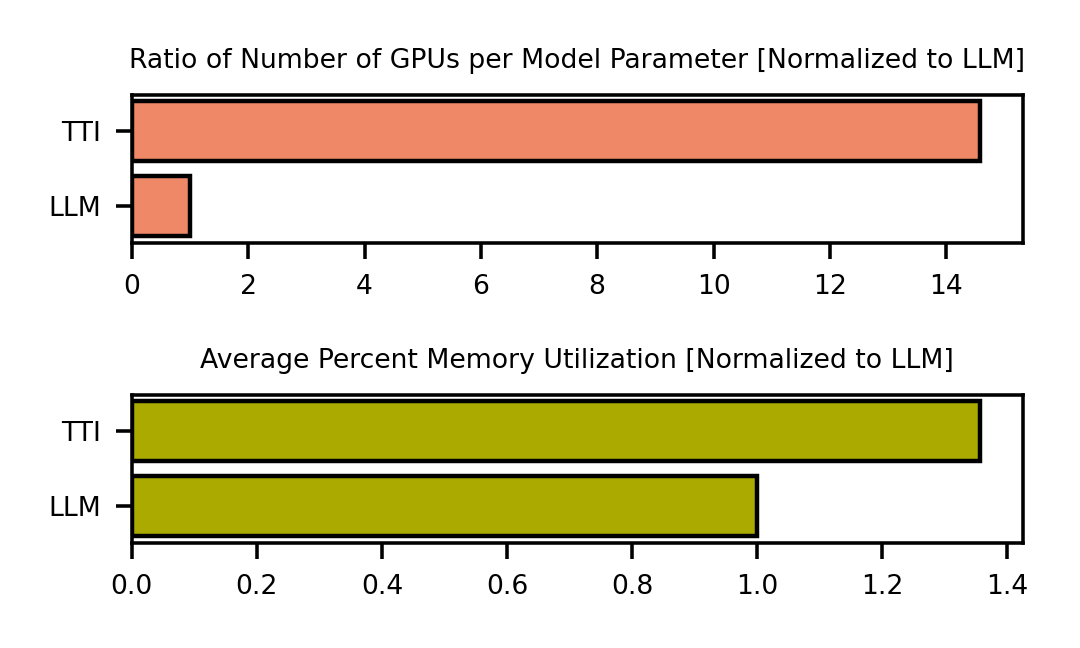
As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
Get summaries of the top AI research delivered straight to your inbox:
Understanding Multi-Modal Machine Learning Tasks
Text-to-Image Generation Models
Text-to-image generation models are a type of multi-modal machine learning task that aims to generate realistic images from text descriptions. These models use large language models (LLMs) and computer vision techniques to translate text prompts into corresponding visual outputs. This allows users to create unique images simply by describing what they want to see.
MaxFusion and other recent text-to-image models have significantly improved image quality and diversity compared to earlier approaches. By combining powerful language understanding with advanced generative adversarial networks (GANs) and diffusion models, these systems can produce highly detailed, coherent images from a wide range of textual inputs.
Plain English Explanation
Text-to-image generation models are AI systems that can create visual images based on written descriptions. These models use large language models to understand the meaning and context of text prompts, and then generate corresponding images using computer vision techniques like GANs and diffusion models.
The key advantage of these systems is that they allow anyone to easily create custom, photorealistic images just by describing what they want to see. This democratizes image creation and opens up new creative possibilities. Recent advances in text-to-image models have dramatically improved the quality, diversity, and fidelity of the generated images compared to earlier efforts.
Technical Explanation
Text-to-image generation models leverage large language models (LLMs) in combination with powerful computer vision techniques to translate text descriptions into corresponding visual outputs. The LLMs handle the language understanding aspect, parsing the semantic meaning and context of the input text prompt. This information is then fed into generative neural networks, often based on generative adversarial networks (GANs) or diffusion models, which synthesize the target image.
State-of-the-art models like MaxFusion have significantly improved the quality and diversity of the generated images compared to earlier text-to-image systems. These models use sophisticated multi-modal fusion techniques to effectively combine the language understanding capabilities of LLMs with the image generation power of advanced computer vision models.
Critical Analysis
While text-to-image generation models have made impressive strides, they still have important limitations and challenges to address. The models can sometimes struggle with generating coherent, consistent images for complex or abstract prompts. There are also concerns around potential biases and safety issues, as the models may produce inappropriate or harmful content.
Furthermore, the computational and memory requirements of these multi-modal systems are substantial, which limits their scalability and accessibility. Ongoing research is exploring ways to improve the efficiency and robustness of text-to-image models, as well as investigating their broader societal implications.
Conclusion
Text-to-image generation models represent a significant advance in the capabilities of generative AI, going beyond the language-only domain of large language models. By combining powerful language understanding with state-of-the-art computer vision techniques, these systems enable users to create custom, photorealistic images simply by describing what they want to see.
The implications of this technology are far-reaching, from democratizing image creation to opening up new creative possibilities. However, there are also important challenges and ethical considerations that will need to be addressed as these models become more widespread. Ongoing research and development in this field will be crucial for unlocking the full potential of multi-modal generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024

MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M Patel
0
0
Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess.
4/16/2024
🤖
A Survey on Generative AI and LLM for Video Generation, Understanding, and Streaming
Pengyuan Zhou, Lin Wang, Zhi Liu, Yanbin Hao, Pan Hui, Sasu Tarkoma, Jussi Kangasharju
0
0
This paper offers an insightful examination of how currently top-trending AI technologies, i.e., generative artificial intelligence (Generative AI) and large language models (LLMs), are reshaping the field of video technology, including video generation, understanding, and streaming. It highlights the innovative use of these technologies in producing highly realistic videos, a significant leap in bridging the gap between real-world dynamics and digital creation. The study also delves into the advanced capabilities of LLMs in video understanding, demonstrating their effectiveness in extracting meaningful information from visual content, thereby enhancing our interaction with videos. In the realm of video streaming, the paper discusses how LLMs contribute to more efficient and user-centric streaming experiences, adapting content delivery to individual viewer preferences. This comprehensive review navigates through the current achievements, ongoing challenges, and future possibilities of applying Generative AI and LLMs to video-related tasks, underscoring the immense potential these technologies hold for advancing the field of video technology related to multimedia, networking, and AI communities.
4/26/2024
🤖
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
0
0
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
5/7/2024