LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models
2210.02249
0
0
🖼️
Abstract
Research in vision-language models has seen rapid developments off-late, enabling natural language-based interfaces for image generation and manipulation. Many existing text guided manipulation techniques are restricted to specific classes of images, and often require fine-tuning to transfer to a different style or domain. Nevertheless, generic image manipulation using a single model with flexible text inputs is highly desirable. Recent work addresses this task by guiding generative models trained on the generic image datasets using pretrained vision-language encoders. While promising, this approach requires expensive optimization for each input. In this work, we propose an optimization-free method for the task of generic image manipulation from text prompts. Our approach exploits recent Latent Diffusion Models (LDM) for text to image generation to achieve zero-shot text guided manipulation. We employ a deterministic forward diffusion in a lower dimensional latent space, and the desired manipulation is achieved by simply providing the target text to condition the reverse diffusion process. We refer to our approach as LDEdit. We demonstrate the applicability of our method on semantic image manipulation and artistic style transfer. Our method can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion. Extensive experiments demonstrate the benefit of our approach over competing baselines.
Create account to get full access
Overview
- Recent advancements in vision-language models have enabled natural language-based interfaces for image generation and manipulation
- Existing text-guided manipulation techniques are often limited to specific image classes and require fine-tuning to transfer to different styles or domains
- This work proposes an optimization-free method for generic image manipulation from text prompts, leveraging Latent Diffusion Models (LDM) for zero-shot text-guided manipulation
Plain English Explanation
Recent progress in vision-language models has led to exciting new ways of interacting with images using natural language. However, many existing techniques for text-guided image manipulation are restricted to certain types of images and often require additional training to work with different styles or subject matter.
This research paper introduces a new approach that aims to overcome these limitations. The key idea is to use a special kind of AI model called a Latent Diffusion Model (LDM) to enable "zero-shot" text-guided image manipulation. This means you can simply provide a text description, and the model will manipulate the image accordingly, without requiring any additional training or optimization steps.
The way this works is by first encoding the image into a compact, lower-dimensional representation. Then, the model uses the text prompt to guide the process of "diffusion" - a technique for gradually transforming this encoded image representation to match the desired attributes described in the text. This happens in a fast, deterministic way, without the need for iterative optimization.
The researchers demonstrate that this approach, which they call "LDEdit," can be used for a wide variety of image manipulation tasks, from changing the semantic content of an image to applying artistic styles. It's a flexible and efficient way to interact with images using natural language, without the limitations of previous methods.
Technical Explanation
The researchers propose an optimization-free method for generic image manipulation from text prompts, building on recent advancements in Latent Diffusion Models (LDMs) for text-to-image generation.
Their approach, called "LDEdit," exploits the properties of LDMs to achieve zero-shot text-guided manipulation. First, the input image is encoded into a lower-dimensional latent representation using a pre-trained LDM encoder. Then, the desired manipulation is achieved by simply providing the target text prompt to condition the reverse diffusion process in the latent space.
This deterministic forward diffusion in the latent space, followed by the text-guided reverse diffusion, enables efficient and flexible image manipulation without the need for expensive optimization for each input, as required by previous methods.
The researchers demonstrate the versatility of LDEdit on a range of tasks, including semantic image manipulation and artistic style transfer. Their experiments show that LDEdit can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion, outperforming competing baselines that require optimization-based approaches.
Critical Analysis
The proposed LDEdit method represents a promising step forward in the field of text-guided image manipulation. By leveraging the capabilities of Latent Diffusion Models, the researchers have developed a flexible and efficient approach that overcomes the limitations of previous techniques, which were often restricted to specific image domains and required costly optimization for each input.
However, the paper does acknowledge some potential caveats and areas for further research. For example, the method may struggle with fine-grained control over specific image attributes, as the text-guided diffusion process operates at a more holistic level. Additionally, the researchers note that their approach may not be suitable for tasks that require precise, pixel-level control, such as image inpainting.
Further research could explore ways to enhance the level of granularity and control in the text-guided manipulation process, potentially by incorporating additional mechanisms or integrating with complementary techniques. Investigating the scalability and generalization of the LDEdit method to even broader image domains and manipulation tasks would also be valuable.
Conclusion
This research paper presents a novel optimization-free approach for generic image manipulation from text prompts, leveraging the capabilities of Latent Diffusion Models. By exploiting the latent representation and the text-guided diffusion process, the proposed LDEdit method enables flexible and efficient image manipulation across diverse domains, outperforming previous optimization-based techniques.
The key innovation of this work is the ability to achieve zero-shot text-guided manipulation without the need for expensive optimization, making it a promising step towards more natural and intuitive ways of interacting with images using language. While the method has some limitations, the demonstrated versatility and performance of LDEdit suggest that it could have significant implications for a wide range of image-related applications and workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ClickDiffusion: Harnessing LLMs for Interactive Precise Image Editing
Alec Helbling, Seongmin Lee, Polo Chau
0
0
Recently, researchers have proposed powerful systems for generating and manipulating images using natural language instructions. However, it is difficult to precisely specify many common classes of image transformations with text alone. For example, a user may wish to change the location and breed of a particular dog in an image with several similar dogs. This task is quite difficult with natural language alone, and would require a user to write a laboriously complex prompt that both disambiguates the target dog and describes the destination. We propose ClickDiffusion, a system for precise image manipulation and generation that combines natural language instructions with visual feedback provided by the user through a direct manipulation interface. We demonstrate that by serializing both an image and a multi-modal instruction into a textual representation it is possible to leverage LLMs to perform precise transformations of the layout and appearance of an image. Code available at https://github.com/poloclub/ClickDiffusion.
4/9/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024
🤖
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
0
0
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
5/7/2024
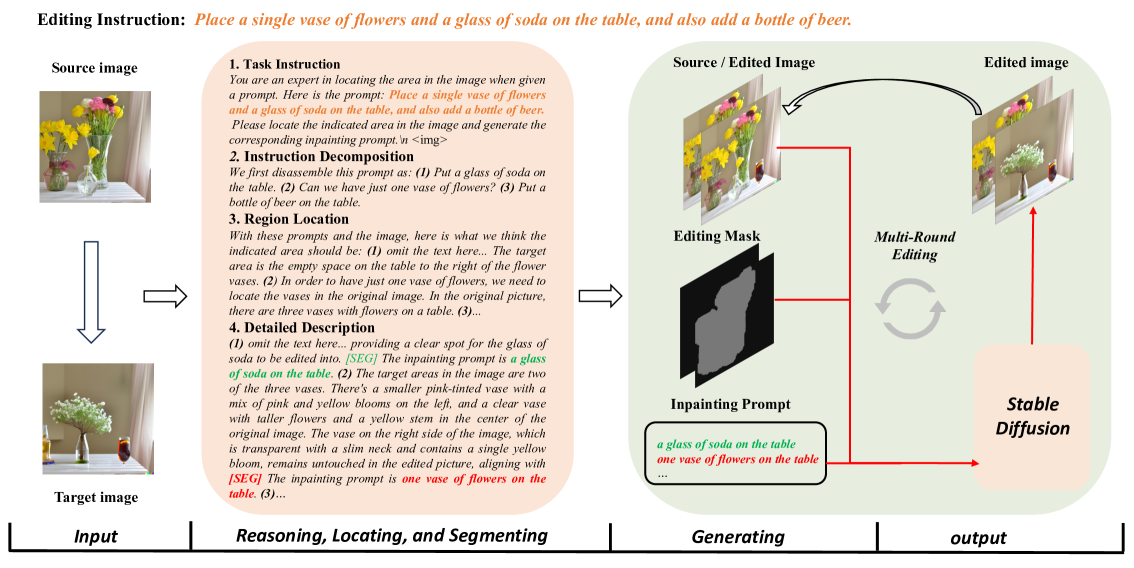
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
0
0
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
5/28/2024