LLM Uncertainty Quantification through Directional Entailment Graph and Claim Level Response Augmentation
2407.00994
0
0

Abstract
The Large language models (LLMs) have showcased superior capabilities in sophisticated tasks across various domains, stemming from basic question-answer (QA), they are nowadays used as decision assistants or explainers for unfamiliar content. However, they are not always correct due to the data sparsity in specific domain corpus, or the model's hallucination problems. Given this, how much should we trust the responses from LLMs? This paper presents a novel way to evaluate the uncertainty that captures the directional instability, by constructing a directional graph from entailment probabilities, and we innovatively conduct Random Walk Laplacian given the asymmetric property of a constructed directed graph, then the uncertainty is aggregated by the derived eigenvalues from the Laplacian process. We also provide a way to incorporate the existing work's semantics uncertainty with our proposed layer. Besides, this paper identifies the vagueness issues in the raw response set and proposes an augmentation approach to mitigate such a problem, we conducted extensive empirical experiments and demonstrated the superiority of our proposed solutions.
Create account to get full access
Overview
- The paper proposes a novel approach for quantifying uncertainty in large language models (LLMs) using a directional entailment graph and claim-level response augmentation.
- The method aims to provide more reliable uncertainty estimates for LLM outputs, which is crucial for their safe and trustworthy deployment in real-world applications.
- The authors introduce a new metric called "directional entailment probability" to measure the uncertainty associated with each claim in an LLM's response.
- They also present a claim-level response augmentation technique to improve the reliability of uncertainty estimates.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at tasks like generating human-like text, answering questions, and completing various language-related activities. However, these models can sometimes be overconfident in their outputs, even when they are uncertain or making mistakes. This can be a problem when LLMs are used in real-world applications where reliable predictions are crucial, such as medical diagnosis or financial decision-making.
To address this issue, the researchers in this paper have developed a new approach to quantify the uncertainty in LLM outputs. The key idea is to look at the "entailment" relationships between the claims made by the LLM in its response. Entailment means that one claim logically follows from another, and the researchers use this concept to build a "directional entailment graph" that captures the logical structure of the LLM's output.
By analyzing this graph, the researchers can assign a "directional entailment probability" to each claim, which reflects how certain the LLM is about that particular claim. Claims with lower entailment probabilities are considered more uncertain.
The researchers also introduce a technique called "claim-level response augmentation" to improve the reliability of the uncertainty estimates. This involves generating additional variations of the LLM's response and using them to refine the uncertainty estimates.
Overall, this research aims to make LLMs more transparent and trustworthy by providing reliable uncertainty information alongside their outputs. This could be particularly useful in sensitive applications where the consequences of mistakes can be severe.
Technical Explanation
The paper introduces a novel approach for quantifying uncertainty in large language models (LLMs) through the use of a directional entailment graph and claim-level response augmentation.
The key idea is to analyze the logical structure of an LLM's output by considering the "entailment" relationships between the individual claims made in the response. Entailment refers to the concept that one claim logically follows from another. The researchers construct a directional entailment graph to capture these dependencies, with each node representing a claim and the directed edges indicating the entailment relationships.
Based on this graph, the authors define a new metric called "directional entailment probability" (DEP) to quantify the uncertainty associated with each claim. Claims with lower DEP values are considered more uncertain, as they are less strongly entailed by the other claims in the response.
To improve the reliability of the uncertainty estimates, the researchers also present a "claim-level response augmentation" technique. This involves generating multiple variations of the LLM's original response and using them to refine the DEP values for each claim. The intuition is that claims that are consistently uncertain across the augmented responses are more likely to be truly uncertain.
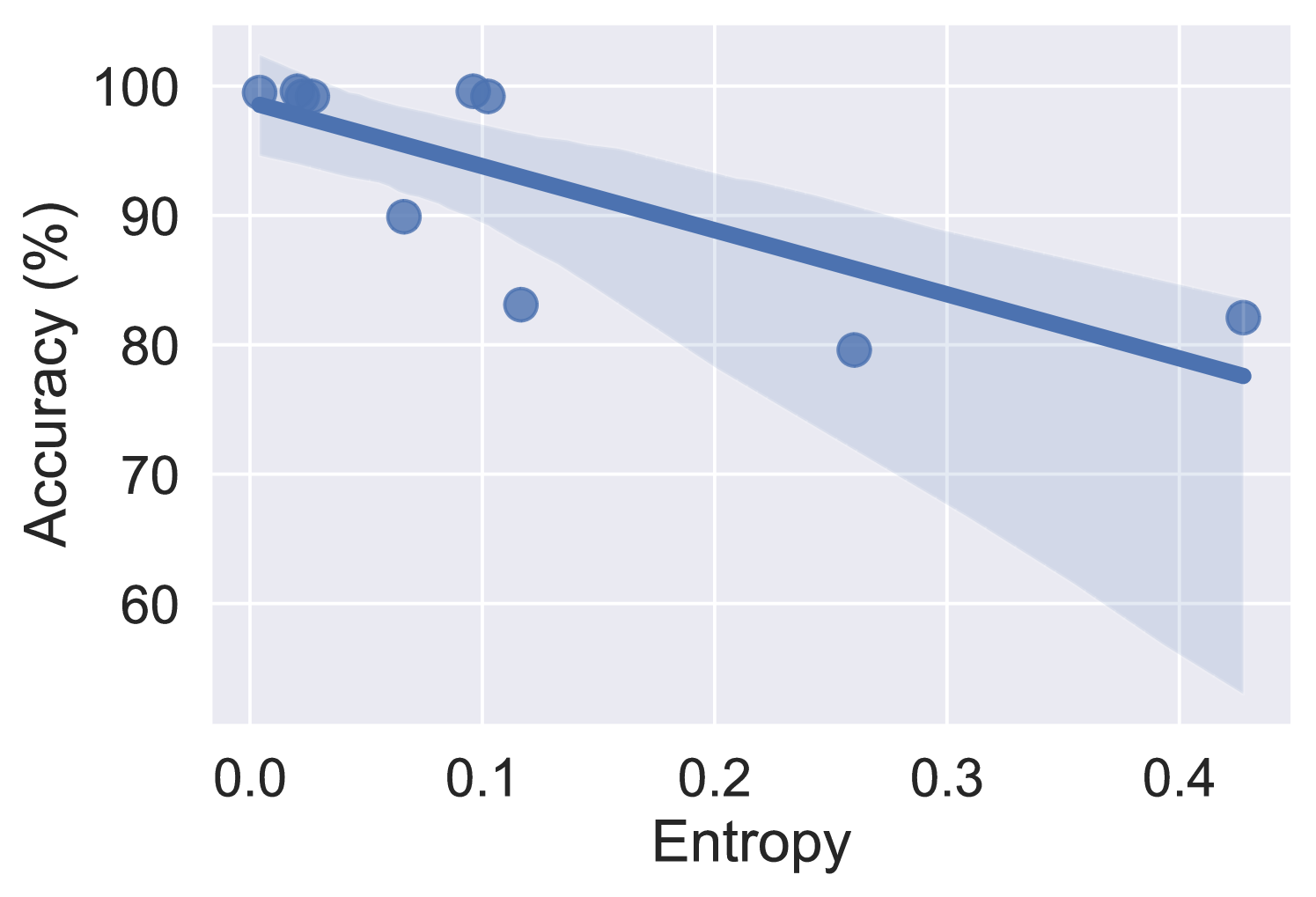
The authors evaluate their approach on several datasets, including question answering, natural language inference, and open-ended generation tasks. Their results demonstrate that the proposed method can effectively identify and estimate the uncertainty in LLM outputs, outperforming several baselines.
Critical Analysis
The paper presents a promising approach for quantifying uncertainty in LLMs, which is an important step towards making these models more reliable and transparent. The use of a directional entailment graph to capture the logical structure of the LLM's output is a novel and insightful idea.
However, the authors acknowledge that their method relies on the assumption that the LLM's outputs can be accurately represented as a set of discrete claims, which may not always be the case, especially for more open-ended generation tasks. Additionally, the claim-level response augmentation technique, while effective, may be computationally expensive and not scalable to large-scale applications.
It would also be interesting to see how the proposed approach performs on a wider range of tasks and datasets, including those that may involve more complex reasoning or domain-specific knowledge. Further research is needed to explore the generalizability and robustness of the method.
Conclusion
This paper presents a novel approach for quantifying uncertainty in large language models (LLMs) using a directional entailment graph and claim-level response augmentation. The key idea is to analyze the logical structure of the LLM's output and assign uncertainty estimates to individual claims based on their entailment relationships.
The proposed method has the potential to make LLMs more transparent and trustworthy, which is crucial for their safe and reliable deployment in real-world applications. While the approach shows promising results, there are still some limitations and areas for further research, such as addressing the assumption of discrete claims and exploring the scalability of the method.
Overall, this work contributes to the growing body of research on uncertainty quantification in LLMs, which is an important step towards developing more reliable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024

To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
0
0
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
6/5/2024
💬
Semantic Density: Uncertainty Quantification in Semantic Space for Large Language Models
Xin Qiu, Risto Miikkulainen
0
0
With the widespread application of Large Language Models (LLMs) to various domains, concerns regarding the trustworthiness of LLMs in safety-critical scenarios have been raised, due to their unpredictable tendency to hallucinate and generate misinformation. Existing LLMs do not have an inherent functionality to provide the users with an uncertainty metric for each response it generates, making it difficult to evaluate trustworthiness. Although a number of works aim to develop uncertainty quantification methods for LLMs, they have fundamental limitations, such as being restricted to classification tasks, requiring additional training and data, considering only lexical instead of semantic information, and being prompt-wise but not response-wise. A new framework is proposed in this paper to address these issues. Semantic density extracts uncertainty information for each response from a probability distribution perspective in semantic space. It has no restriction on task types and is off-the-shelf for new models and tasks. Experiments on seven state-of-the-art LLMs, including the latest Llama 3 and Mixtral-8x22B models, on four free-form question-answering benchmarks demonstrate the superior performance and robustness of semantic density compared to prior approaches.
5/28/2024
💬
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
0
0
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
5/21/2024