Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have shown promising capabilities in natural language generation (NLG)
- Assessing the trustworthiness of LLM-generated responses is an open challenge, with limited research on uncertainty quantification (UQ) for NLG
- Existing UQ methods typically assume white-box access to language models, which is becoming unrealistic due to closed-source models or computational constraints
- This paper investigates UQ in NLG for
black-box LLMs
Plain English Explanation
Large language models (LLMs) are advanced AI systems that can generate human-like text on a variety of topics. While these models have become increasingly capable, it's not always clear how reliable or trustworthy their responses are. This is an important challenge, as we want to be able to trust the information and outputs generated by these powerful AI systems.
The researchers in this paper wanted to explore ways of quantifying the
The researchers tested several different methods for measuring uncertainty and confidence, and applied them to LLMs performing question-answering tasks. The goal was to see if these uncertainty measures could help identify when the LLM's responses might be unreliable, so that they could be ignored or flagged for further review. The results revealed that a simple measure of the semantic dispersion of the model's potential responses could be a good way to predict the quality of the LLM's output.
This work provides valuable insights for practitioners who want to adopt LLMs while managing the uncertainty and reliability of the systems.
Technical Explanation
The researchers first differentiated between
To investigate UQ for
The results reveal that a simple measure of semantic dispersion can be a reliable predictor of the quality of LLM responses. This provides valuable insights for practitioners adopting LLMs on how to manage the uncertainty of these powerful language models.
Critical Analysis
The paper provides a practical approach to addressing the challenge of uncertainty quantification for black-box LLMs, which is becoming increasingly relevant as the latest, most capable models are often closed-source. By differentiating between uncertainty and confidence, the researchers were able to explore various measures that could be applied without needing full access to the model.
However, the paper does not delve into the potential limitations or caveats of the proposed methods. It would be useful to understand the specific scenarios or contexts where the uncertainty measures may be less reliable, or cases where they could be susceptible to biases or other issues. Additionally, the paper could have discussed potential avenues for further research, such as exploring more sophisticated UQ techniques or investigating the generalizability of the findings to a broader range of LLM architectures and tasks.
Overall, this work provides a valuable contribution to the field of uncertainty quantification for large language models, and the insights on confidence and uncertainty management could be beneficial for practitioners looking to safely harness the power of LLMs.
Conclusion
This paper investigates uncertainty quantification (UQ) for natural language generation (NLG) in the context of
The experimental results revealed that a simple measure of semantic dispersion can be a reliable predictor of LLM response quality, providing valuable insights for practitioners adopting these powerful language models and needing to manage the uncertainty of their outputs.
This work contributes to the broader research on uncertainty quantification for large language models and benchmarking LLM capabilities through uncertainty-aware methods, which is crucial as these advanced AI systems become more widely adopted.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Zhen Lin, Shubhendu Trivedi, Jimeng Sun
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification (UQ) for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or computational constraints. In this work, we investigate UQ in NLG for *black-box* LLMs. We first differentiate *uncertainty* vs *confidence*: the former refers to the ``dispersion'' of the potential predictions for a fixed input, and the latter refers to the confidence on a particular prediction/generation. We then propose and compare several confidence/uncertainty measures, applying them to *selective NLG* where unreliable results could either be ignored or yielded for further assessment. Experiments were carried out with several popular LLMs on question-answering datasets (for evaluation purposes). Results reveal that a simple measure for the semantic dispersion can be a reliable predictor of the quality of LLM responses, providing valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate our experiments is available at https://github.com/zlin7/UQ-NLG.
Read more5/21/2024
💬
0
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Akim Tsvigun, Daniil Vasilev, Rui Xing, Abdelrahman Boda Sadallah, Lyudmila Rvanova, Sergey Petrakov, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, Artem Shelmanov
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
Read more6/26/2024
0
On Subjective Uncertainty Quantification and Calibration in Natural Language Generation
Ziyu Wang, Chris Holmes
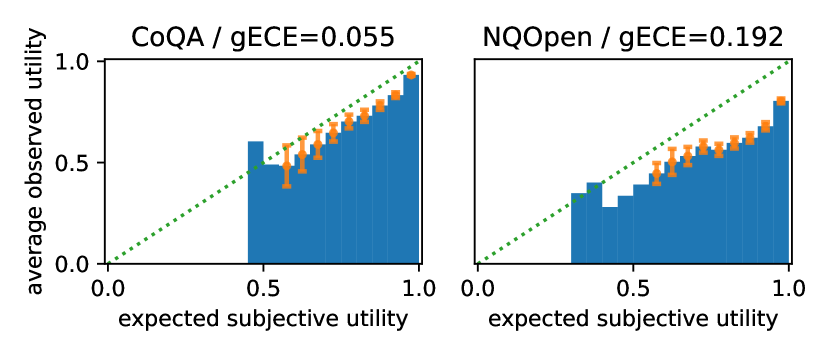
Applications of large language models often involve the generation of free-form responses, in which case uncertainty quantification becomes challenging. This is due to the need to identify task-specific uncertainties (e.g., about the semantics) which appears difficult to define in general cases. This work addresses these challenges from a perspective of Bayesian decision theory, starting from the assumption that our utility is characterized by a similarity measure that compares a generated response with a hypothetical true response. We discuss how this assumption enables principled quantification of the model's subjective uncertainty and its calibration. We further derive a measure for epistemic uncertainty, based on a missing data perspective and its characterization as an excess risk. The proposed measures can be applied to black-box language models. We demonstrate the proposed methods on question answering and machine translation tasks, where they extract broadly meaningful uncertainty estimates from GPT and Gemini models and quantify their calibration.
Read more6/11/2024
0
Large Language Model Confidence Estimation via Black-Box Access
Tejaswini Pedapati, Amit Dhurandhar, Soumya Ghosh, Soham Dan, Prasanna Sattigeri
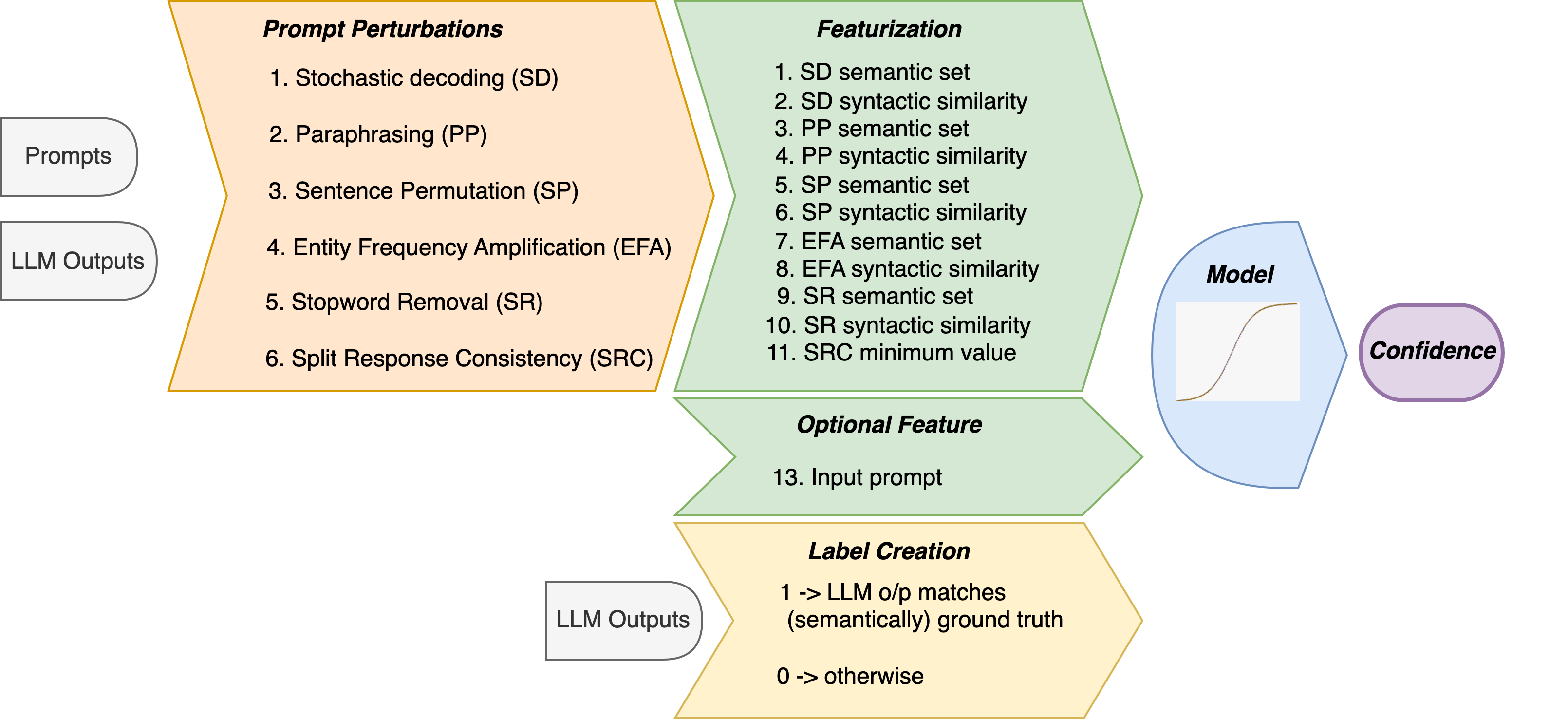
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.
Read more6/10/2024