To Believe or Not to Believe Your LLM

40

Sign in to get full access
Overview
- This paper explores the challenges of assessing the reliability and trustworthiness of large language models (LLMs) when used for high-stakes applications.
- It examines the ability of LLMs to provide accurate self-assessments of their own uncertainty and limitations.
- The paper presents several approaches for quantifying and expressing the uncertainty of LLM outputs, aiming to help users better understand the model's capabilities and limitations.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at generating human-like text, answering questions, and completing a variety of language-related tasks. However, it's not always clear how reliable or trustworthy the outputs of these models are, especially when they are used in important real-world applications.
The key challenge is that LLMs can sometimes produce responses that seem plausible and coherent, but may actually be inaccurate or biased in ways that the user may not realize. This is because LLMs are trained on large datasets, but don't have a full understanding of the world in the way that humans do. They can sometimes make mistakes or give responses that are misleading or inconsistent.
To address this, the researchers in this paper explore different ways that LLMs can provide more transparent and reliable information about their own uncertainty and limitations. This could involve having the model output a "confidence score" along with its responses, or quantifying the model's uncertainty in other ways.
The goal is to help users better understand when they can trust the model's outputs, and when they should be more skeptical or seek additional confirmation. By having a clearer sense of the model's reliability, users can make more informed decisions about when to rely on the model's recommendations, especially in high-stakes scenarios.
Overall, this research is an important step towards making large language models more transparent and trustworthy as they become increasingly integrated into everyday applications and decision-making processes.
Technical Explanation
The paper presents several approaches for quantifying and expressing the uncertainty of LLM outputs, with the goal of helping users better understand the model's capabilities and limitations.
One key technique explored is semantic density uncertainty quantification, which measures the density of semantically similar outputs in the model's latent space. This can provide a sense of how confident the model is in a particular response, as outputs with higher density are likely to be more reliable.
The researchers also investigate generating confidence scores - additional information provided by the model about its own uncertainty. This can take the form of explicit probability estimates or other metrics that convey the model's self-assessed reliability.
Additionally, the paper explores contextual uncertainty quantification, which considers how the model's uncertainty may vary depending on the specific input or task. This can help users understand when the model is more or less likely to produce accurate results.
Through a series of experiments, the researchers demonstrate the effectiveness of these techniques in improving the transparency and trustworthiness of LLM outputs. They show that users are better able to calibrate their trust in the model's responses when provided with reliable uncertainty information.
Critical Analysis
The research presented in this paper is a valuable contribution to the ongoing efforts to make large language models more reliable and trustworthy. The proposed approaches for quantifying and expressing model uncertainty are well-designed and show promising results.
However, it's important to note that these techniques are not a panacea for the inherent limitations of LLMs. Even with enhanced uncertainty reporting, users may still struggle to fully understand the model's biases and blind spots, especially in high-stakes scenarios. Additional research is needed to further explore the impact of these model limitations on real-world decision-making.
Furthermore, the paper does not address the potential ethical and societal implications of deploying LLMs with uncertain outputs. As these models become more integrated into critical systems, it will be crucial to carefully consider the risks and ensure appropriate safeguards are in place.
Overall, while this paper represents an important step forward, continued research and rigorous testing will be necessary to ensure that LLMs can be safely and responsibly deployed in high-stakes applications.
Conclusion
This paper presents several innovative approaches for quantifying and expressing the uncertainty of large language model outputs, with the goal of improving the transparency and trustworthiness of these powerful AI systems.
By providing users with reliable information about the model's self-assessed reliability, these techniques can help them make more informed decisions about when to trust the model's recommendations, especially in critical real-world scenarios.
As LLMs become increasingly integrated into everyday applications and decision-making processes, this research represents a crucial step towards ensuring that these models can be safely and responsibly deployed in a way that benefits society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
40
To Believe or Not to Believe Your LLM
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr'as Gyorgy, Csaba Szepesv'ari
We explore uncertainty quantification in large language models (LLMs), with the goal to identify when uncertainty in responses given a query is large. We simultaneously consider both epistemic and aleatoric uncertainties, where the former comes from the lack of knowledge about the ground truth (such as about facts or the language), and the latter comes from irreducible randomness (such as multiple possible answers). In particular, we derive an information-theoretic metric that allows to reliably detect when only epistemic uncertainty is large, in which case the output of the model is unreliable. This condition can be computed based solely on the output of the model obtained simply by some special iterative prompting based on the previous responses. Such quantification, for instance, allows to detect hallucinations (cases when epistemic uncertainty is high) in both single- and multi-answer responses. This is in contrast to many standard uncertainty quantification strategies (such as thresholding the log-likelihood of a response) where hallucinations in the multi-answer case cannot be detected. We conduct a series of experiments which demonstrate the advantage of our formulation. Further, our investigations shed some light on how the probabilities assigned to a given output by an LLM can be amplified by iterative prompting, which might be of independent interest.
Read more7/18/2024

0
Uncertainty Estimation of Large Language Models in Medical Question Answering
Jiaxin Wu, Yizhou Yu, Hong-Yu Zhou
Large Language Models (LLMs) show promise for natural language generation in healthcare, but risk hallucinating factually incorrect information. Deploying LLMs for medical question answering necessitates reliable uncertainty estimation (UE) methods to detect hallucinations. In this work, we benchmark popular UE methods with different model sizes on medical question-answering datasets. Our results show that current approaches generally perform poorly in this domain, highlighting the challenge of UE for medical applications. We also observe that larger models tend to yield better results, suggesting a correlation between model size and the reliability of UE. To address these challenges, we propose Two-phase Verification, a probability-free Uncertainty Estimation approach. First, an LLM generates a step-by-step explanation alongside its initial answer, followed by formulating verification questions to check the factual claims in the explanation. The model then answers these questions twice: first independently, and then referencing the explanation. Inconsistencies between the two sets of answers measure the uncertainty in the original response. We evaluate our approach on three biomedical question-answering datasets using Llama 2 Chat models and compare it against the benchmarked baseline methods. The results show that our Two-phase Verification method achieves the best overall accuracy and stability across various datasets and model sizes, and its performance scales as the model size increases.
Read more7/12/2024
0
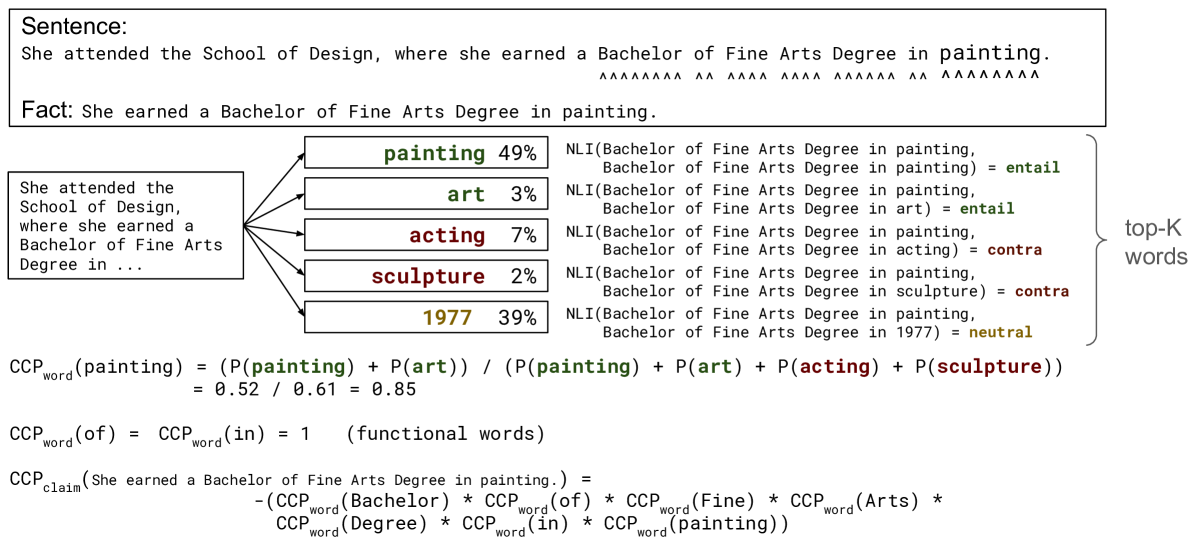
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov
Large language models (LLMs) are notorious for hallucinating, i.e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factually correct, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel fact-checking and hallucination detection pipeline based on token-level uncertainty quantification. Uncertainty scores leverage information encapsulated in the output of a neural network or its layers to detect unreliable predictions, and we show that they can be used to fact-check the atomic claims in the LLM output. Moreover, we present a novel token-level uncertainty quantification method that removes the impact of uncertainty about what claim to generate on the current step and what surface form to use. Our method Claim Conditioned Probability (CCP) measures only the uncertainty of a particular claim value expressed by the model. Experiments on the task of biography generation demonstrate strong improvements for CCP compared to the baselines for seven LLMs and four languages. Human evaluation reveals that the fact-checking pipeline based on uncertainty quantification is competitive with a fact-checking tool that leverages external knowledge.
Read more6/10/2024
0
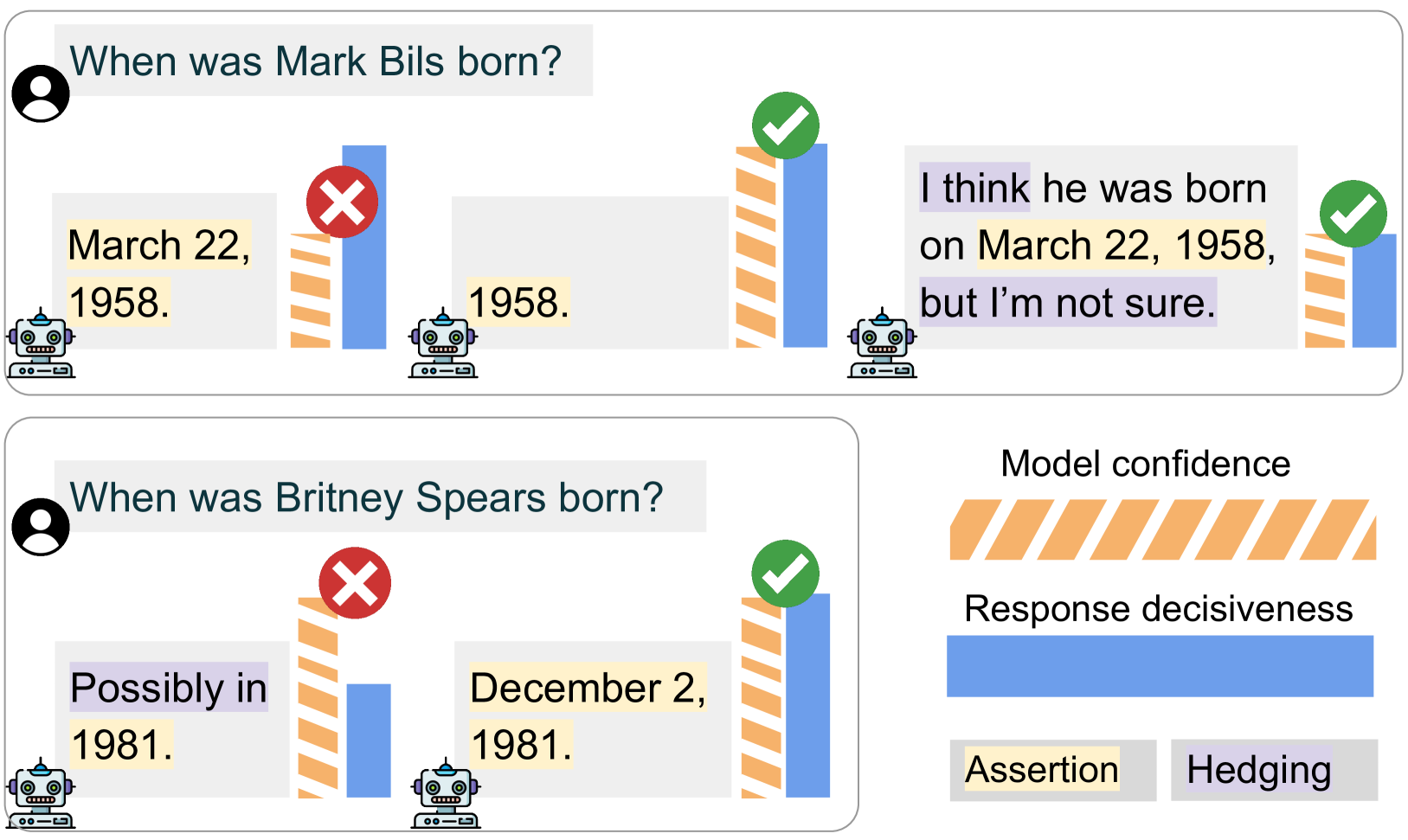
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Read more5/28/2024