LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking

0
Sign in to get full access
Overview
- Large language models (LLMs) are powerful AI systems that can understand and generate human-like text.
- This paper explores using LLMs to improve the performance of entity linking, a key task in natural language processing.
- The researchers show that LLMs can effectively augment context information to boost entity linking accuracy.
- The proposed approach, called LLMaEL, leverages the rich semantic knowledge captured in LLMs to enhance entity disambiguation.
Plain English Explanation
Entity linking is the process of identifying the specific real-world entities (like people, places, or organizations) mentioned in a text and connecting them to a knowledge base. This is an important task for many applications, like search engines and recommender systems.
The researchers in this paper found that using large language models (LLMs) as context augmenters can significantly improve entity linking performance. LLMs are AI systems that are trained on massive amounts of text data and can understand and generate human-like language.
The key insight is that the rich semantic knowledge captured in LLMs can provide valuable additional context to help resolve ambiguities in entity mentions. For example, if a text mentions "Washington," an LLM can use its understanding of the world to determine whether it is referring to the person, the city, or the state.
The researchers developed a system called LLMaEL that leverages this idea. LLMaEL takes the original text, uses an LLM to generate additional context information, and then feeds this augmented context to a standard entity linking model. They show that this approach outperforms using just the original text alone.
Technical Explanation
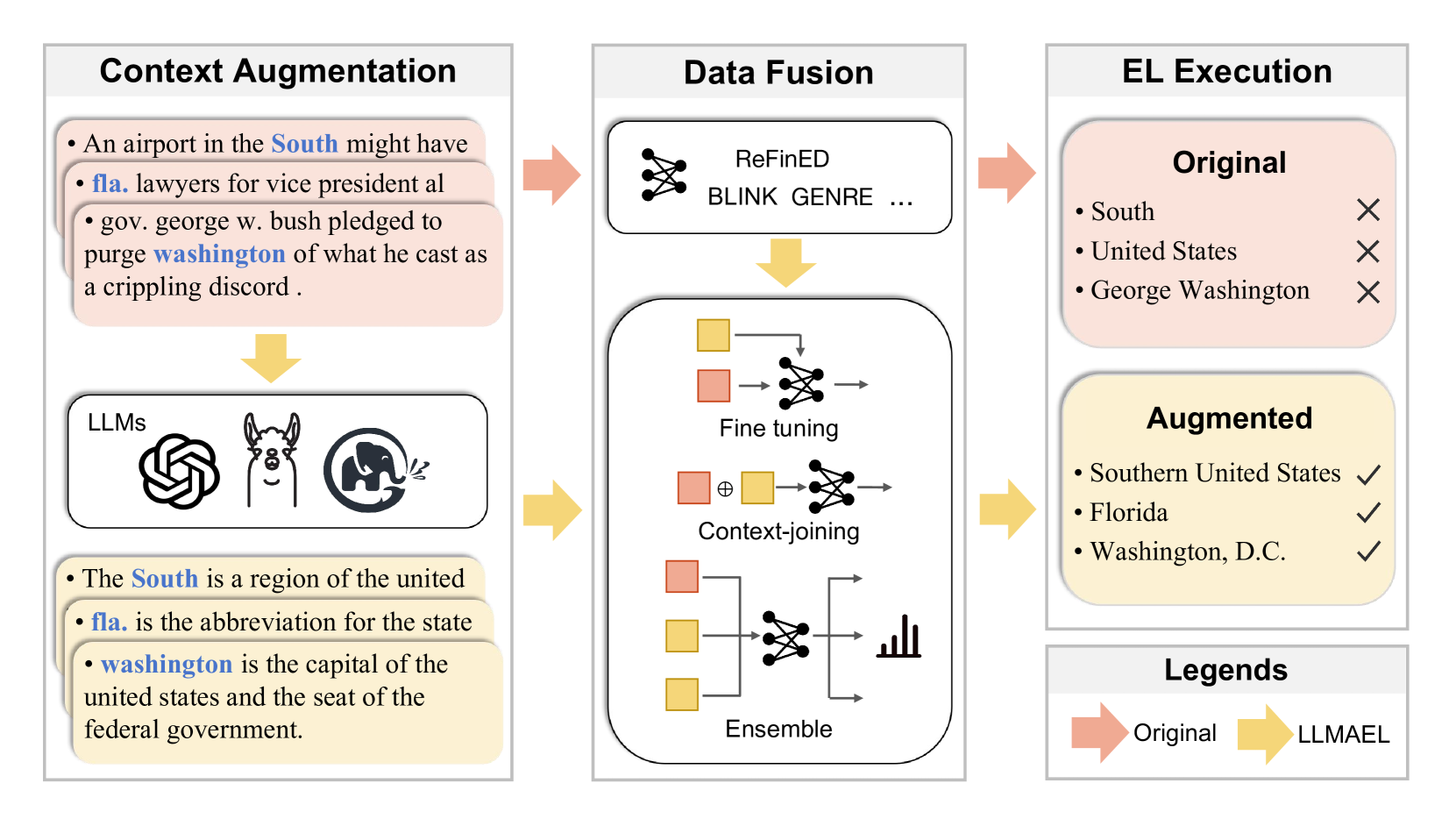
The researchers propose the LLMaEL (Large Language Models are Good Context Augmenters for Entity Linking) framework, which uses large language models to enhance the context information available for entity linking tasks.
The core idea is to leverage the rich semantic knowledge captured in pre-trained LLMs to generate additional context around entity mentions. This augmented context is then provided as input to a standard entity linking system, boosting its performance.
Specifically, the LLMaEL pipeline consists of three main steps:
- Entity Mention Detection: The first step is to identify all entity mentions in the input text.
- Context Augmentation: For each entity mention, the system uses an LLM to generate additional context by prompting it with the mention and its surrounding text.
- Entity Linking: The augmented context is then fed into a base entity linking model, which maps the mentions to their corresponding entries in a knowledge base.
The researchers evaluate LLMaEL on several standard entity linking benchmarks and show that it significantly outperforms using just the original text as input. They attribute this improvement to the LLM's ability to capture relevant semantic and world knowledge that helps disambiguate entity mentions.
Critical Analysis
The paper makes a compelling case for the benefits of using large language models as context augmenters for entity linking. The results demonstrate clear performance improvements across multiple datasets, highlighting the value of the additional semantic information provided by the LLMs.
However, the paper does not address some potential limitations or concerns with this approach. For example, it is not clear how the LLMaEL system would scale to real-world scenarios with a large, dynamic knowledge base or handle rare or unseen entity mentions. There are also ongoing debates about the reliability and potential biases of large language models, which could impact the quality of the generated context.
Additionally, the authors do not provide a detailed analysis of the types of entity mentions or contexts where the LLM-based augmentation is most beneficial. Understanding these nuances could help guide future improvements and applications of the technique.
Overall, the LLMaEL framework represents a promising direction for leveraging the capabilities of large language models to enhance entity linking. However, further research is needed to fully characterize the strengths, weaknesses, and best practices for this approach.
Conclusion
This paper introduces the LLMaEL framework, which demonstrates the effectiveness of using large language models as context augmenters for entity linking tasks. By leveraging the rich semantic knowledge captured in pre-trained LLMs, the system is able to generate additional context that significantly improves the performance of standard entity linking models.
The results highlight the potential of combining the capabilities of large language models with traditional natural language processing techniques to tackle complex challenges. As the field of AI continues to advance, we can expect to see more innovative approaches that harness the power of large-scale language understanding to enhance a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking
Amy Xin, Yunjia Qi, Zijun Yao, Fangwei Zhu, Kaisheng Zeng, Xu Bin, Lei Hou, Juanzi Li
Entity Linking (EL) models are well-trained at mapping mentions to their corresponding entities according to a given context. However, EL models struggle to disambiguate long-tail entities due to their limited training data. Meanwhile, large language models (LLMs) are more robust at interpreting uncommon mentions. Yet, due to a lack of specialized training, LLMs suffer at generating correct entity IDs. Furthermore, training an LLM to perform EL is cost-intensive. Building upon these insights, we introduce LLM-Augmented Entity Linking LLMAEL, a plug-and-play approach to enhance entity linking through LLM data augmentation. We leverage LLMs as knowledgeable context augmenters, generating mention-centered descriptions as additional input, while preserving traditional EL models for task specific processing. Experiments on 6 standard datasets show that the vanilla LLMAEL outperforms baseline EL models in most cases, while the fine-tuned LLMAEL set the new state-of-the-art results across all 6 benchmarks.
Read more7/16/2024
0
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Read more4/30/2024
💬
0
Leveraging Large Language Models for Entity Matching
Qianyu Huang, Tongfang Zhao
Entity matching (EM) is a critical task in data integration, aiming to identify records across different datasets that refer to the same real-world entities. Traditional methods often rely on manually engineered features and rule-based systems, which struggle with diverse and unstructured data. The emergence of Large Language Models (LLMs) such as GPT-4 offers transformative potential for EM, leveraging their advanced semantic understanding and contextual capabilities. This vision paper explores the application of LLMs to EM, discussing their advantages, challenges, and future research directions. Additionally, we review related work on applying weak supervision and unsupervised approaches to EM, highlighting how LLMs can enhance these methods.
Read more6/3/2024
💬
0
Entity Matching using Large Language Models
Ralph Peeters, Christian Bizer
Entity Matching is the task of deciding whether two entity descriptions refer to the same real-world entity and is a central step in most data integration pipelines. Many state-of-the-art entity matching methods rely on pre-trained language models (PLMs) such as BERT or RoBERTa. Two major drawbacks of these models for entity matching are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. This paper investigates using generative large language models (LLMs) as a less task-specific training data-dependent and more robust alternative to PLM-based matchers. Our study covers hosted and open-source LLMs, which can be run locally. We evaluate these models in a zero-shot scenario and a scenario where task-specific training data is available. We compare different prompt designs and the prompt sensitivity of the models and show that there is no single best prompt but needs to be tuned for each model/dataset combination. We further investigate (i) the selection of in-context demonstrations, (ii) the generation of matching rules, as well as (iii) fine-tuning a hosted LLM using the same pool of training data. Our experiments show that the best LLMs require no or only a few training examples to perform similarly to PLMs that were fine-tuned using thousands of examples. LLM-based matchers further exhibit higher robustness to unseen entities. We show that GPT4 can generate structured explanations for matching decisions. The model can automatically identify potential causes of matching errors by analyzing explanations of wrong decisions. We demonstrate that the model can generate meaningful textual descriptions of the identified error classes, which can help data engineers improve entity matching pipelines.
Read more6/6/2024