LLMGA: Multimodal Large Language Model based Generation Assistant

0

Sign in to get full access
Overview
- Introduces a Multimodal Large Language Model based Generation Assistant (LLMGA)
- Integrates large language models with multimodal capabilities for generation tasks
- Aims to enable efficient and effective multimodal content creation
Plain English Explanation
The research paper describes a Multimodal Large Language Model based Generation Assistant (LLMGA). This system combines powerful large language models with the ability to handle multiple types of media, such as text, images, and even video.
The goal of LLMGA is to make it easier and more efficient for people to create various kinds of content, whether it's writing, designing graphics, or producing multimedia. By leveraging the capabilities of large language models, LLMGA can assist users in generating high-quality output across different modalities.
Technical Explanation
The paper outlines the key components and architecture of the LLMGA system. It describes how the system integrates large language models, such as GPT-3, with multimodal capabilities to enable generation tasks that combine text, images, and other media.
The researchers explain the training process, which involves fine-tuning the language models on diverse datasets to expand their abilities beyond just text-based generation. They also discuss the inference mechanisms used by LLMGA to generate coherent and relevant multimodal outputs in response to user prompts.
Critical Analysis
The paper acknowledges some limitations of the LLMGA system, such as the potential for biases and inconsistencies in the generated content. The authors suggest that further research is needed to address these issues and improve the system's robustness and reliability.
Additionally, the paper doesn't provide a comprehensive evaluation of LLMGA's performance compared to other state-of-the-art multimodal generation systems. More extensive testing and benchmarking would be helpful to fully assess the system's capabilities and limitations.
Conclusion
The LLMGA research presents a promising approach to leveraging the power of large language models for efficient and effective multimodal content creation. By integrating these models with multimodal capabilities, the system aims to enable users to generate high-quality, diverse outputs across various media types.
While the paper highlights some areas for improvement, the overall concept of a Multimodal Large Language Model based Generation Assistant has the potential to significantly impact the way people create and interact with digital content in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMGA: Multimodal Large Language Model based Generation Assistant
Bin Xia, Shiyin Wang, Yingfan Tao, Yitong Wang, Jiaya Jia
In this paper, we introduce a Multimodal Large Language Model-based Generation Assistant (LLMGA), leveraging the vast reservoir of knowledge and proficiency in reasoning, comprehension, and response inherent in Large Language Models (LLMs) to assist users in image generation and editing. Diverging from existing approaches where Multimodal Large Language Models (MLLMs) generate fixed-size embeddings to control Stable Diffusion (SD), our LLMGA provides a detailed language generation prompt for precise control over SD. This not only augments LLM context understanding but also reduces noise in generation prompts, yields images with more intricate and precise content, and elevates the interpretability of the network. To this end, we curate a comprehensive dataset comprising prompt refinement, similar image generation, inpainting & outpainting, and instruction-based editing. Moreover, we propose a two-stage training scheme. In the first stage, we train the MLLM to grasp the properties of image generation and editing, enabling it to generate detailed prompts. In the second stage, we optimize SD to align with the MLLM's generation prompts. Additionally, we propose a reference-based restoration network to alleviate texture, brightness, and contrast disparities between generated and preserved regions during inpainting and outpainting. Extensive results show that LLMGA has promising generation and editing capabilities and can enable more flexible and expansive applications in an interactive manner.
Read more7/30/2024

0
GenArtist: Multimodal LLM as an Agent for Unified Image Generation and Editing
Zhenyu Wang, Aoxue Li, Zhenguo Li, Xihui Liu
Despite the success achieved by existing image generation and editing methods, current models still struggle with complex problems including intricate text prompts, and the absence of verification and self-correction mechanisms makes the generated images unreliable. Meanwhile, a single model tends to specialize in particular tasks and possess the corresponding capabilities, making it inadequate for fulfilling all user requirements. We propose GenArtist, a unified image generation and editing system, coordinated by a multimodal large language model (MLLM) agent. We integrate a comprehensive range of existing models into the tool library and utilize the agent for tool selection and execution. For a complex problem, the MLLM agent decomposes it into simpler sub-problems and constructs a tree structure to systematically plan the procedure of generation, editing, and self-correction with step-by-step verification. By automatically generating missing position-related inputs and incorporating position information, the appropriate tool can be effectively employed to address each sub-problem. Experiments demonstrate that GenArtist can perform various generation and editing tasks, achieving state-of-the-art performance and surpassing existing models such as SDXL and DALL-E 3, as can be seen in Fig. 1. Project page is https://zhenyuw16.github.io/GenArtist_page.
Read more7/9/2024
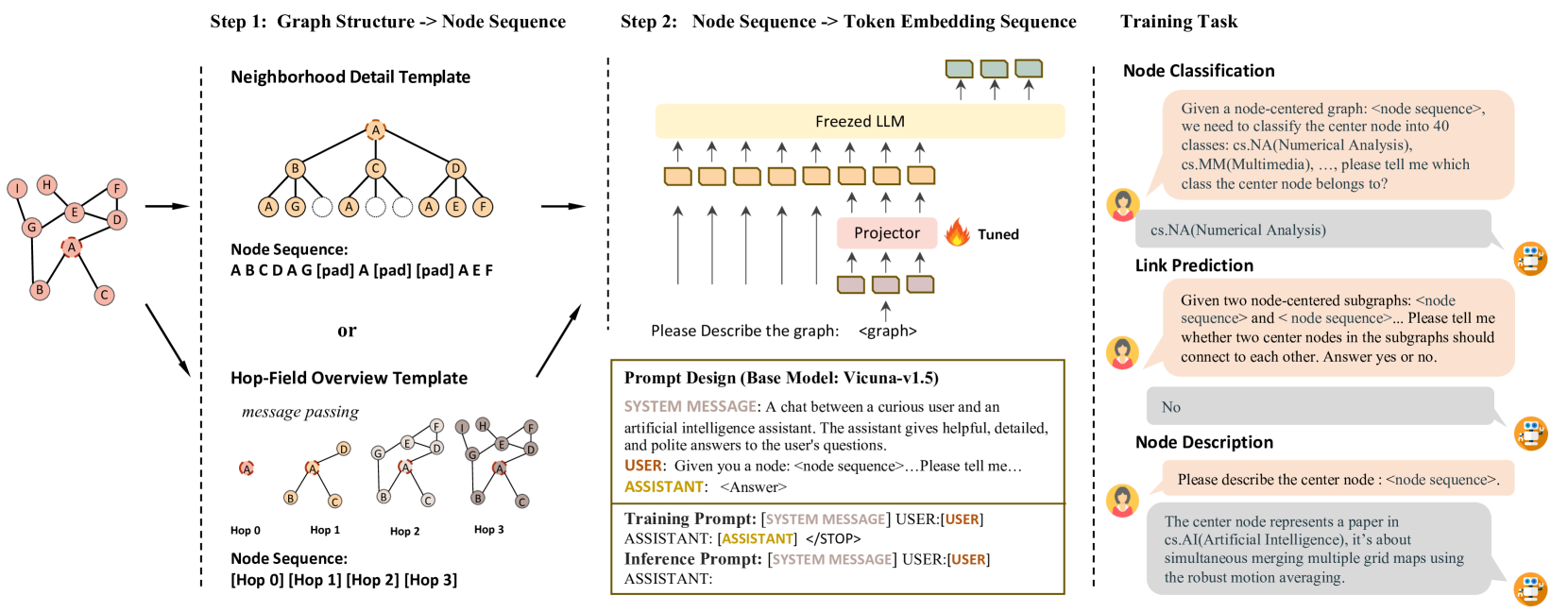
0
LLaGA: Large Language and Graph Assistant
Runjin Chen, Tong Zhao, Ajay Jaiswal, Neil Shah, Zhangyang Wang
Graph Neural Networks (GNNs) have empowered the advance in graph-structured data analysis. Recently, the rise of Large Language Models (LLMs) like GPT-4 has heralded a new era in deep learning. However, their application to graph data poses distinct challenges due to the inherent difficulty of translating graph structures to language. To this end, we introduce the Large Language and Graph Assistant (LLaGA), an innovative model that effectively integrates LLM capabilities to handle the complexities of graph-structured data. LLaGA retains the general-purpose nature of LLMs while adapting graph data into a format compatible with LLM input. LLaGA achieves this by reorganizing graph nodes to structure-aware sequences and then mapping these into the token embedding space through a versatile projector. LLaGA excels in versatility, generalizability and interpretability, allowing it to perform consistently well across different datasets and tasks, extend its ability to unseen datasets or tasks, and provide explanations for graphs. Our extensive experiments across popular graph benchmarks show that LLaGA delivers outstanding performance across four datasets and three tasks using one single model, surpassing state-of-the-art graph models in both supervised and zero-shot scenarios. Our code is available at url{https://github.com/VITA-Group/LLaGA}.
Read more4/12/2024

0
LLMs Meet Multimodal Generation and Editing: A Survey
Yingqing He, Zhaoyang Liu, Jingye Chen, Zeyue Tian, Hongyu Liu, Xiaowei Chi, Runtao Liu, Ruibin Yuan, Yazhou Xing, Wenhai Wang, Jifeng Dai, Yong Zhang, Wei Xue, Qifeng Liu, Yike Guo, Qifeng Chen
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on multimodal understanding. This survey elaborates on multimodal generation and editing across various domains, comprising image, video, 3D, and audio. Specifically, we summarize the notable advancements with milestone works in these fields and categorize these studies into LLM-based and CLIP/T5-based methods. Then, we summarize the various roles of LLMs in multimodal generation and exhaustively investigate the critical technical components behind these methods and the multimodal datasets utilized in these studies. Additionally, we dig into tool-augmented multimodal agents that can leverage existing generative models for human-computer interaction. Lastly, we discuss the advancements in the generative AI safety field, investigate emerging applications, and discuss future prospects. Our work provides a systematic and insightful overview of multimodal generation and processing, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
Read more6/11/2024