LLMs Meet Multimodal Generation and Editing: A Survey
2405.19334
0
0

Abstract
With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on multimodal understanding. This survey elaborates on multimodal generation and editing across various domains, comprising image, video, 3D, and audio. Specifically, we summarize the notable advancements with milestone works in these fields and categorize these studies into LLM-based and CLIP/T5-based methods. Then, we summarize the various roles of LLMs in multimodal generation and exhaustively investigate the critical technical components behind these methods and the multimodal datasets utilized in these studies. Additionally, we dig into tool-augmented multimodal agents that can leverage existing generative models for human-computer interaction. Lastly, we discuss the advancements in the generative AI safety field, investigate emerging applications, and discuss future prospects. Our work provides a systematic and insightful overview of multimodal generation and processing, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
Create account to get full access
Overview
- This survey paper explores the exciting intersection of large language models (LLMs) and multimodal generation and editing, including text-to-image, text-to-video, text-to-3D, and text-to-audio capabilities.
- It delves into the latest advancements in generative AI, multimodal agents, and the efficient integration of LLMs with different modalities.
- The paper also discusses crucial considerations around AI safety and the responsible development of these powerful multimodal LLM systems.
Plain English Explanation
This research paper explores the exciting new capabilities that emerge when large language models (LLMs) are combined with the ability to generate and manipulate different types of media, such as images, videos, 3D models, and audio. LLMs are advanced AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human language with remarkable fluency.
By integrating LLMs with the capacity to create and edit multimodal content, researchers are unlocking a world of new possibilities. For example, these systems can now generate detailed images, produce animated videos, design 3D objects, or even compose original music, all based on simple text prompts. This opens up exciting applications in fields like art, entertainment, education, and beyond.
However, the paper also highlights the important considerations around the responsible development of these powerful technologies. As these systems become more capable, there are crucial questions to address around AI safety, bias, and the potential for misuse. The researchers emphasize the need to thoughtfully navigate these challenges to ensure that multimodal LLMs are developed and deployed in a manner that benefits humanity.
Technical Explanation
The paper provides a comprehensive survey of the current state of the art in multimodal generation and editing with large language models. It covers a wide range of modalities, including text-to-image, text-to-video, text-to-3D, and text-to-audio, exploring the latest architectures, techniques, and insights from the research community.
The authors delve into the foundational generative AI models, such as diffusion models and transformers, that have enabled these multimodal capabilities. They also examine the role of multimodal agents and the efficient integration of LLMs with different modalities.
Importantly, the paper discusses the critical safety and ethical considerations surrounding the development and deployment of these powerful multimodal systems, emphasizing the need for responsible and thoughtful approaches.
Critical Analysis
The paper provides a comprehensive and well-researched overview of the rapidly evolving field of multimodal generation and editing with large language models. The authors have done an excellent job of synthesizing the latest advancements and highlighting the key technical details and insights.
One potential area of concern raised in the paper is the need for robust safety and ethical frameworks to guide the development of these powerful technologies. As multimodal LLMs become more capable, there are valid concerns around the potential for misuse, bias, and unintended consequences. The authors rightly emphasize the importance of addressing these challenges proactively.
Additionally, the paper could have delved deeper into the limitations and practical challenges of integrating LLMs with different modalities, such as the computational and memory requirements, data availability, and the complexities of cross-modal alignment and coherence. These are crucial considerations for the real-world deployment of these systems.
Overall, the paper provides a valuable and timely contribution to the field, serving as a comprehensive resource for researchers, developers, and policymakers interested in the intersection of LLMs and multimodal generation and editing.
Conclusion
This survey paper offers a broad and detailed exploration of the exciting advancements at the intersection of large language models (LLMs) and multimodal generation and editing. By integrating LLMs with the ability to create and manipulate diverse media, including images, videos, 3D models, and audio, researchers are unlocking a wealth of new possibilities in fields ranging from art and entertainment to education and beyond.
However, the paper also highlights the critical importance of addressing the safety and ethical considerations surrounding the development and deployment of these powerful multimodal systems. As these technologies continue to advance, it will be crucial to navigate the challenges of bias, misuse, and unintended consequences to ensure that they are leveraged in a responsible and beneficial manner.
Overall, this survey provides a valuable and timely overview of the state of the art in this rapidly evolving field, serving as a valuable resource for anyone interested in the intersection of large language models and multimodal generation and editing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
🤖
A Survey on Generative AI and LLM for Video Generation, Understanding, and Streaming
Pengyuan Zhou, Lin Wang, Zhi Liu, Yanbin Hao, Pan Hui, Sasu Tarkoma, Jussi Kangasharju
0
0
This paper offers an insightful examination of how currently top-trending AI technologies, i.e., generative artificial intelligence (Generative AI) and large language models (LLMs), are reshaping the field of video technology, including video generation, understanding, and streaming. It highlights the innovative use of these technologies in producing highly realistic videos, a significant leap in bridging the gap between real-world dynamics and digital creation. The study also delves into the advanced capabilities of LLMs in video understanding, demonstrating their effectiveness in extracting meaningful information from visual content, thereby enhancing our interaction with videos. In the realm of video streaming, the paper discusses how LLMs contribute to more efficient and user-centric streaming experiences, adapting content delivery to individual viewer preferences. This comprehensive review navigates through the current achievements, ongoing challenges, and future possibilities of applying Generative AI and LLMs to video-related tasks, underscoring the immense potential these technologies hold for advancing the field of video technology related to multimedia, networking, and AI communities.
4/26/2024
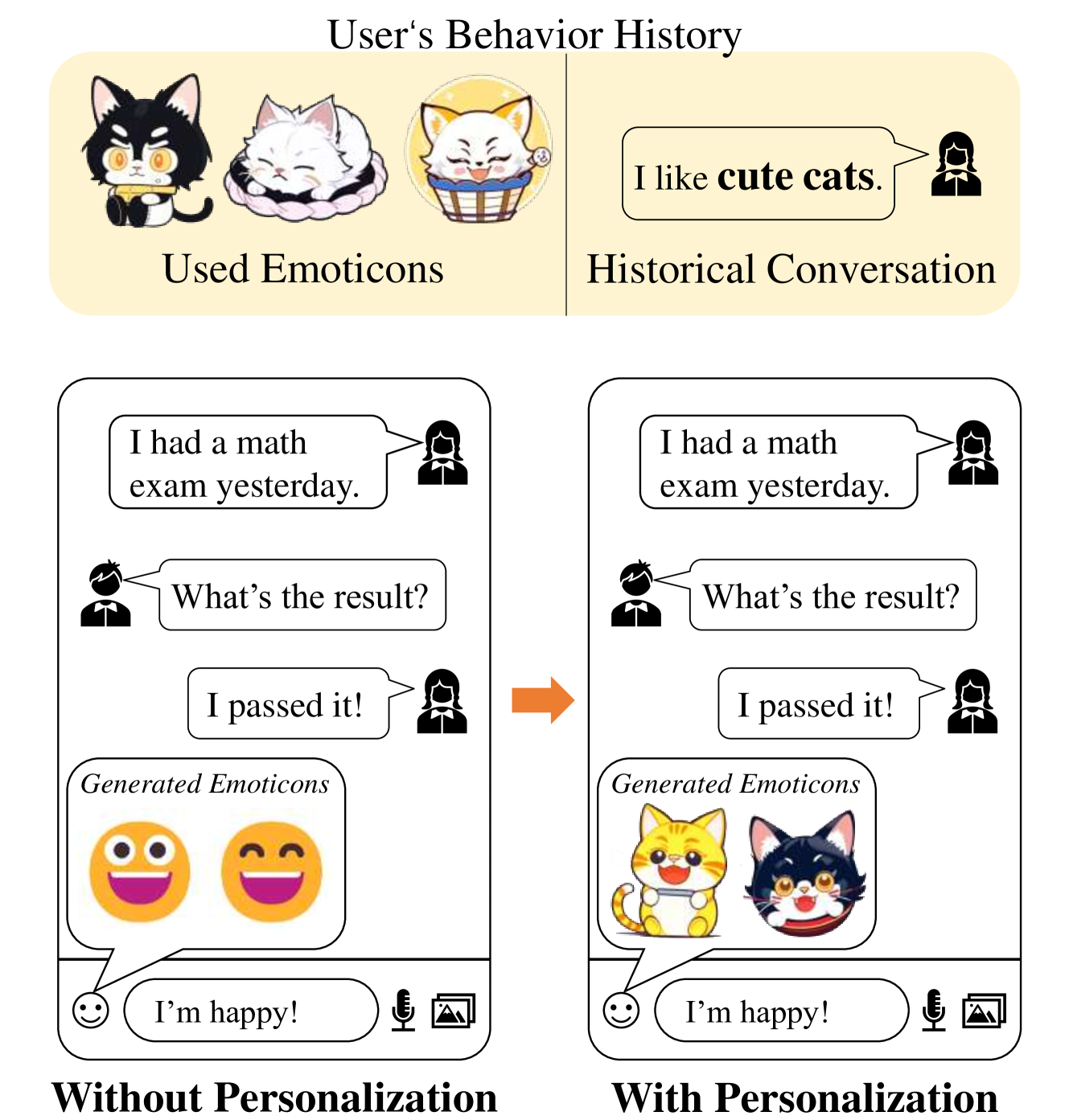
PMG : Personalized Multimodal Generation with Large Language Models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao
0
0
The emergence of large language models (LLMs) has revolutionized the capabilities of text comprehension and generation. Multi-modal generation attracts great attention from both the industry and academia, but there is little work on personalized generation, which has important applications such as recommender systems. This paper proposes the first method for personalized multimodal generation using LLMs, showcases its applications and validates its performance via an extensive experimental study on two datasets. The proposed method, Personalized Multimodal Generation (PMG for short) first converts user behaviors (e.g., clicks in recommender systems or conversations with a virtual assistant) into natural language to facilitate LLM understanding and extract user preference descriptions. Such user preferences are then fed into a generator, such as a multimodal LLM or diffusion model, to produce personalized content. To capture user preferences comprehensively and accurately, we propose to let the LLM output a combination of explicit keywords and implicit embeddings to represent user preferences. Then the combination of keywords and embeddings are used as prompts to condition the generator. We optimize a weighted sum of the accuracy and preference scores so that the generated content has a good balance between them. Compared to a baseline method without personalization, PMG has a significant improvement on personalization for up to 8% in terms of LPIPS while retaining the accuracy of generation.
4/16/2024