LLMParser: An Exploratory Study on Using Large Language Models for Log Parsing

0

Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) for the task of log parsing, which is the process of extracting structured information from unstructured log data.
- The researchers developed a system called LLMParser that leverages the capabilities of LLMs to perform log parsing, and they evaluated its performance on various real-world log datasets.
- The key findings suggest that LLMParser can achieve competitive or better performance compared to traditional rule-based and machine learning-based log parsing approaches, highlighting the potential of LLMs for this task.
Plain English Explanation
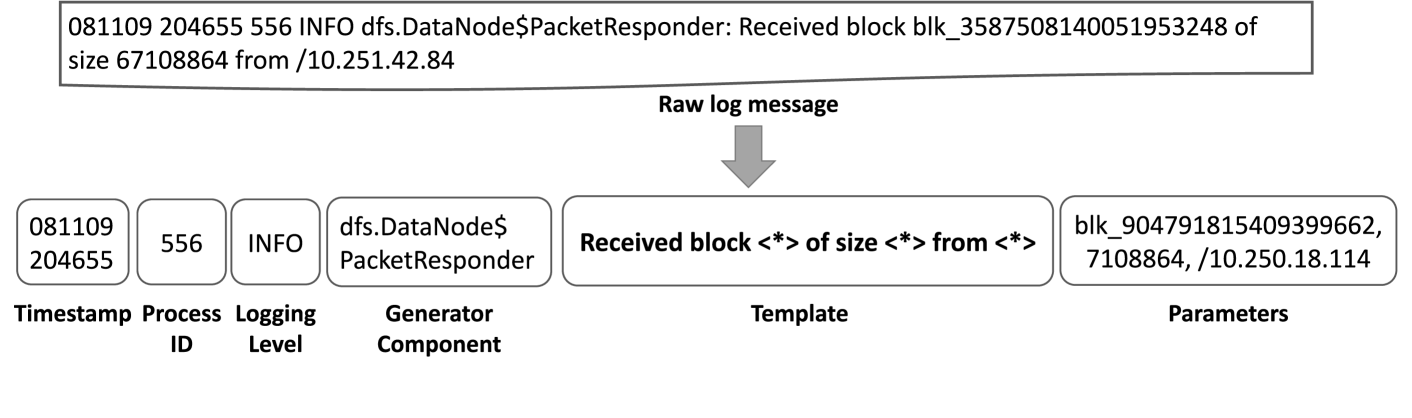
Computers and software systems often generate large amounts of log data, which are essentially records of what the system is doing. This log data can be very useful for troubleshooting, monitoring, and understanding the behavior of these systems. However, the log data is usually in a free-form, unstructured format, making it challenging to analyze and extract useful information from it.
The researchers in this paper explored the use of large language models (LLMs), which are powerful AI systems trained on vast amounts of text data, to help with the task of log parsing. They developed a system called LLMParser that uses LLMs to analyze the log data and extract structured information, such as the type of event, the time it occurred, and any relevant details.
The researchers tested LLMParser on several real-world log datasets and found that it could perform as well as or better than traditional rule-based and machine learning-based approaches to log parsing. This suggests that LLMs could be a promising tool for simplifying the process of working with log data and extracting valuable insights from it.
The key idea behind using LLMs for log parsing is that these models have a deep understanding of language and can recognize patterns and extract meaning from text, even if it is in a relatively unstructured format like log data. By leveraging this capability, the researchers were able to develop a more flexible and adaptable log parsing system that can handle a wide variety of log formats and content.
Technical Explanation
The researchers developed a system called LLMParser that uses large language models (LLMs) for the task of log parsing. The core idea behind LLMParser is to leverage the powerful language understanding capabilities of LLMs to extract structured information from unstructured log data.
The LLMParser system consists of two main components:
-
Log Preprocessing: The log data is first preprocessed to remove any noise or irrelevant information, and to standardize the format of the logs.
-
Log Parsing with LLMs: The preprocessed log data is then passed through a large language model, such as GPT-3 or BERT, which is fine-tuned on a dataset of labeled log entries. The LLM is used to classify the log entries into different event types and extract relevant attributes, such as timestamps, error codes, and other relevant details.
The researchers evaluated the performance of LLMParser on several real-world log datasets, including logs from web servers, cloud infrastructure, and financial systems. They compared the performance of LLMParser to traditional rule-based and machine learning-based log parsing approaches, and found that LLMParser could achieve competitive or better performance in terms of accuracy, F1 score, and other evaluation metrics.
The key insights from the research are:
- Apprentices to Research Assistants: Advancing Research with Large Language Models: LLMs can be effectively leveraged for the task of log parsing, demonstrating their versatility in handling unstructured data.
- Unleashing the Potential of Large Language Models for Predictive Tabular Modeling: The flexibility and adaptability of LLMs can lead to improved performance compared to traditional log parsing approaches, which are often tailored to specific log formats or event types.
- Analyzing LLM Usage in an Advanced Computing Class in India: The successful application of LLMParser to real-world log datasets suggests that LLMs could be a valuable tool for a wide range of log analysis and monitoring tasks.
Critical Analysis
The researchers have provided a compelling demonstration of the potential of large language models for the task of log parsing. However, there are a few caveats and areas for further research that could be explored:
-
Interpretability and Explainability: While the LLMParser system achieves strong performance, the inner workings of the large language model used for log parsing may not be fully interpretable. This could make it challenging to understand the reasoning behind the model's decisions, especially for critical applications where transparency is important.
-
Domain-Specific Customization: The researchers mention that the LLMs used in LLMParser were fine-tuned on labeled log data, which may not be readily available for all domains. Exploring ways to adapt the system to new log formats and event types without extensive fine-tuning could improve its real-world applicability.
-
Handling of Rare or Unseen Events: Large language models, like any machine learning model, may struggle with accurately parsing log entries that represent rare or previously unseen events. Investigating strategies to improve the robustness of LLMParser in such scenarios could be a valuable area of future research.
-
Large Language Models for Mathematicians: While the paper demonstrates the potential of LLMs for log parsing, it would be interesting to see how the performance and capabilities of the system compare to other state-of-the-art log parsing approaches, both in terms of accuracy and computational efficiency.
-
Exploring the Landscape of Large Language Models: Foundations and Techniques: The researchers focused on using LLMs for log parsing, but the broader implications of leveraging these powerful language models for other data analysis and monitoring tasks could also be explored.
Overall, the LLMParser system represents an exciting step forward in the application of large language models to real-world log parsing challenges. With continued research and refinement, the techniques explored in this paper could have significant implications for the field of system monitoring and troubleshooting.
Conclusion
This paper presents an exploratory study on the use of large language models (LLMs) for the task of log parsing, a critical process in system monitoring and analysis. The researchers developed a system called LLMParser that leverages the powerful language understanding capabilities of LLMs to extract structured information from unstructured log data.
The key findings of the study suggest that LLMParser can achieve competitive or better performance compared to traditional rule-based and machine learning-based log parsing approaches, highlighting the potential of LLMs for this task. The flexibility and adaptability of LLMs allow the LLMParser system to handle a wide variety of log formats and event types, making it a promising tool for simplifying the process of working with log data and extracting valuable insights.
While the paper demonstrates the potential of this approach, there are also areas for further research, such as improving the interpretability and explainability of the LLM-based system, exploring strategies for domain-specific customization, and enhancing the system's ability to handle rare or unseen events. Nonetheless, the successful application of LLMParser to real-world log datasets suggests that LLMs could be a valuable tool for a wide range of log analysis and monitoring tasks, with significant implications for the field of system management and troubleshooting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMParser: An Exploratory Study on Using Large Language Models for Log Parsing
Zeyang Ma, An Ran Chen, Dong Jae Kim, Tse-Hsun Chen, Shaowei Wang
Logs are important in modern software development with runtime information. Log parsing is the first step in many log-based analyses, that involve extracting structured information from unstructured log data. Traditional log parsers face challenges in accurately parsing logs due to the diversity of log formats, which directly impacts the performance of downstream log-analysis tasks. In this paper, we explore the potential of using Large Language Models (LLMs) for log parsing and propose LLMParser, an LLM-based log parser based on generative LLMs and few-shot tuning. We leverage four LLMs, Flan-T5-small, Flan-T5-base, LLaMA-7B, and ChatGLM-6B in LLMParsers. Our evaluation of 16 open-source systems shows that LLMParser achieves statistically significantly higher parsing accuracy than state-of-the-art parsers (a 96% average parsing accuracy). We further conduct a comprehensive empirical analysis on the effect of training size, model size, and pre-training LLM on log parsing accuracy. We find that smaller LLMs may be more effective than more complex LLMs; for instance where Flan-T5-base achieves comparable results as LLaMA-7B with a shorter inference time. We also find that using LLMs pre-trained using logs from other systems does not always improve parsing accuracy. While using pre-trained Flan-T5-base shows an improvement in accuracy, pre-trained LLaMA results in a decrease (decrease by almost 55% in group accuracy). In short, our study provides empirical evidence for using LLMs for log parsing and highlights the limitations and future research direction of LLM-based log parsers.
Read more4/30/2024

0
LogParser-LLM: Advancing Efficient Log Parsing with Large Language Models
Aoxiao Zhong, Dengyao Mo, Guiyang Liu, Jinbu Liu, Qingda Lu, Qi Zhou, Jiesheng Wu, Quanzheng Li, Qingsong Wen
Logs are ubiquitous digital footprints, playing an indispensable role in system diagnostics, security analysis, and performance optimization. The extraction of actionable insights from logs is critically dependent on the log parsing process, which converts raw logs into structured formats for downstream analysis. Yet, the complexities of contemporary systems and the dynamic nature of logs pose significant challenges to existing automatic parsing techniques. The emergence of Large Language Models (LLM) offers new horizons. With their expansive knowledge and contextual prowess, LLMs have been transformative across diverse applications. Building on this, we introduce LogParser-LLM, a novel log parser integrated with LLM capabilities. This union seamlessly blends semantic insights with statistical nuances, obviating the need for hyper-parameter tuning and labeled training data, while ensuring rapid adaptability through online parsing. Further deepening our exploration, we address the intricate challenge of parsing granularity, proposing a new metric and integrating human interactions to allow users to calibrate granularity to their specific needs. Our method's efficacy is empirically demonstrated through evaluations on the Loghub-2k and the large-scale LogPub benchmark. In evaluations on the LogPub benchmark, involving an average of 3.6 million logs per dataset across 14 datasets, our LogParser-LLM requires only 272.5 LLM invocations on average, achieving a 90.6% F1 score for grouping accuracy and an 81.1% for parsing accuracy. These results demonstrate the method's high efficiency and accuracy, outperforming current state-of-the-art log parsers, including pattern-based, neural network-based, and existing LLM-enhanced approaches.
Read more8/27/2024
0
A Comparative Study on Large Language Models for Log Parsing
Merve Astekin, Max Hort, Leon Moonen
Background: Log messages provide valuable information about the status of software systems. This information is provided in an unstructured fashion and automated approaches are applied to extract relevant parameters. To ease this process, log parsing can be applied, which transforms log messages into structured log templates. Recent advances in language models have led to several studies that apply ChatGPT to the task of log parsing with promising results. However, the performance of other state-of-the-art large language models (LLMs) on the log parsing task remains unclear. Aims: In this study, we investigate the current capability of state-of-the-art LLMs to perform log parsing. Method: We select six recent LLMs, including both paid proprietary (GPT-3.5, Claude 2.1) and four free-to-use open models, and compare their performance on system logs obtained from a selection of mature open-source projects. We design two different prompting approaches and apply the LLMs on 1, 354 log templates across 16 different projects. We evaluate their effectiveness, in the number of correctly identified templates, and the syntactic similarity between the generated templates and the ground truth. Results: We found that free-to-use models are able to compete with paid models, with CodeLlama extracting 10% more log templates correctly than GPT-3.5. Moreover, we provide qualitative insights into the usability of language models (e.g., how easy it is to use their responses). Conclusions: Our results reveal that some of the smaller, free-to-use LLMs can considerably assist log parsing compared to their paid proprietary competitors, especially code-specialized models.
Read more9/5/2024

0
LUK: Empowering Log Understanding with Expert Knowledge from Large Language Models
Lipeng Ma, Weidong Yang, Sihang Jiang, Ben Fei, Mingjie Zhou, Shuhao Li, Bo Xu, Yanghua Xiao
Logs play a critical role in providing essential information for system monitoring and troubleshooting. Recently, with the success of pre-trained language models (PLMs) and large language models (LLMs) in natural language processing (NLP), smaller PLMs (such as BERT) and LLMs (like ChatGPT) have become the current mainstream approaches for log analysis. While LLMs possess rich knowledge, their high computational costs and unstable performance make LLMs impractical for analyzing logs directly. In contrast, smaller PLMs can be fine-tuned for specific tasks even with limited computational resources, making them more practical. However, these smaller PLMs face challenges in understanding logs comprehensively due to their limited expert knowledge. To better utilize the knowledge embedded within LLMs for log understanding, this paper introduces a novel knowledge enhancement framework, called LUK, which acquires expert knowledge from LLMs to empower log understanding on a smaller PLM. Specifically, we design a multi-expert collaboration framework based on LLMs consisting of different roles to acquire expert knowledge. In addition, we propose two novel pre-training tasks to enhance the log pre-training with expert knowledge. LUK achieves state-of-the-art results on different log analysis tasks and extensive experiments demonstrate expert knowledge from LLMs can be utilized more effectively to understand logs.
Read more9/4/2024